来源:机器之心
编辑:泽南
Minecraft 里面自建像素风世界不够过瘾?英伟达:那就让 AI 来脑补一个真实的世界。
在 4 月 12 日英伟达 GTC 2021 大会的 Keynote 上,黄仁勋除了展示 Grace 等一系列硬件产品之外,还曾向我们介绍了一种使用神经网络让《我的世界》(Minecraft)像素风 3D 画面自动转换为写实风格精细画面的技术(GANcraft)。最近,GANcraft 的论文被提交到了 arXiv 上,我们得以了解这项技术的细节。
最引人注意的是,GANcraft 的 AI 是在没有现实世界与 Minecraft 世界之间对应数据的情况下,完成学习并进行渲染的。从演示视频上看来,它提升的效果可谓惊人。

此前,英伟达的 GPU 可以利用 Tensor Core 开启 DLSS(深度学习超级采样)技术,让很多游戏的画质、帧数大幅提升。如果 GANcraft 的技术成熟,我们或许可以期待未来出现更加强大的 3D 图像精细化技术。
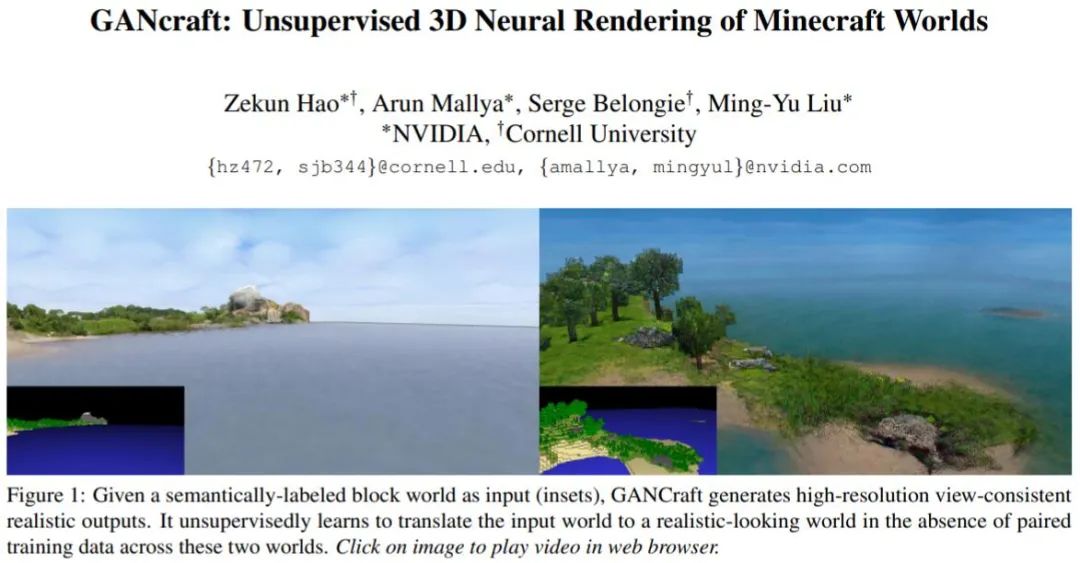
由康奈尔大学、英伟达研究人员 Zekun Hao 等人提出的 GANcraft 是一种无监督的神经渲染框架,用于生成基于大型 3D 像素块世界(如在《我的世界》中构建的世界)的拟真图像。其方法是将语义像素块作为输入,在每个块中都分配一个标签,例如土、草、树、沙或水。算法会将 3D 世界表示为连续的体积函数,并训练神经网络模型在没有对应像素——真实图像数据的情况下,从任意角度渲染与视图一致的真实化图像。除了摄像的视角外,GANcraft 还允许人们控制场景的语义和风格。
让每个玩家变身场景设计师
与以往的图像超分辨率算法不同,GANcraft 希望解决的是「世界到世界转换问题」:给定一个带有语义标记的方块世界,如流行游戏《我的世界》中的场景,GANcraft 能够将其转换为共享相同布局,但偏向真实感的新世界。人们可以从任意视角渲染新世界,以生成既具有视图一致性又具有真实感的图像和视频。
GANcraft 技术大幅简化了复杂场景下的 3D 建模过程。要在以往,这需要多年的专业领域知识,现在每个《我的世界》玩家都可以成为 3D 艺术家了。

通常,深度学习超分辨率算法需要原有真实图像,并在对应的情况下进行监督训练,但对于《我的世界》中大量的虚构场景来说,这样的要求显然不太现实。在研究中,作者也将 GANcraft 与一些基于 2D 数据训练的模型(MUNIT、SPADE)、基于 2D 修补和 3D 变形生成图像的方法 wc-vid2vid,以及从 3D 一致数据集中学习并进行预测的 NeRF-W 进行了比较。

相比之下,我们可以看到 im2im 的方法(MUNIT 和 SPADE)无法实现视角的一致性,因为它们并不学习 3D 结构,且每一帧都是独立生成的;wc-vid2vid 可以产生视图一致的视频,但是由于块状几何体和训练测试集差距引起的误差累积,图像质量会随着时间发展迅速恶化。NSVF-W 的效果看起来接近于 GANcraft,但缺少一些精细度。
在 GANcraft 生成的结果中,神经渲染的使用保证了 3D 视图的一致性,而模型架构和训练方案的创新让我们实现了前所未有的真实感。
如何让 AI「脑补」出真实世界
假设我们已经有了一个合适的体素条件神经渲染模型,其能够表示真实世界,我们仍然需要一种方法对其进行特殊的训练,使其在没有任何真实原图的情况下生成图像。
在没有参照图像的情况下,生成对抗网络 GAN 已在小规模、无限制的神经渲染任务中取得了一些成功。但对于 GANcraft 的应用场景来说,问题则更具挑战性——与真实世界相比,《我的世界》中的像素块具有完全不同的标签分布。例如,某些场景被雪、沙漠或水完全覆盖。也有在一个小区域内跨越多种内容的场景。此外,当从神经渲染模型随机采样视图时,我们不可能将采样的视角分布与互联网上可获取的照片相匹配。

如上图所示,由于任务的复杂性,使用互联网上的公开照片作为参照进行对抗训练(第一行)会导致难看的结果。生产和使用伪真实情况进行训练是 GANcraft 工作的主要贡献之一,并且可以显著提高生成效果(第二行)。
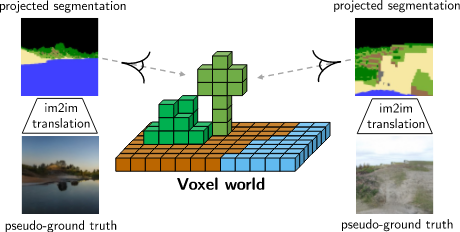
生成「伪真图」的方法是使用预训练的 SPADE 模型从分割蒙版生成真实感图像。当从方块世界中采样分割蒙版时,伪真图与从相同视图生成的图像共享相同的标签和相机视角。这不仅减少了标签和视角的不匹配,而且还使我们能够使用更强的损失函数(例如 perceptual 和 L2 loss)来进行更快、更稳定的训练。
在 GANcraft 中,研究人员结合了 3D 体积渲染器和 2D 图像空间渲染器来表示拟真场景。作者首先定义一个以体素为边界的神经辐射场:给定一个方块世界,为块的每个角分配一个可学习的特征向量,并使用三线性插值法在体素内的任意位置定义位置代码。随后我们就可以使用 MLP 来隐式定义辐射场,其接收位置数据,并用语义标签和共享的风格内容作为输入,生成点特征及其体积密度。
这样,只要再给定视角参数,我们就可以渲染辐射场以获得 2D 特征图了,该特征图最后通过卷积神经网络 CNN 转换为图像。
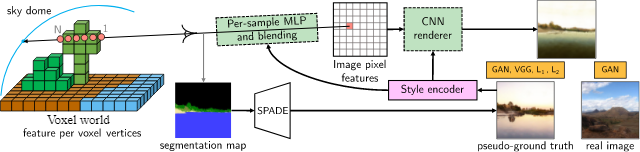
由于辐射场可以使用更简单的 MLP 进行建模,因此 GANcraft 的两阶段体系结构可显著提高图像质量,同时减少计算量和内存占用量,这是基于隐式体积方法的计算瓶颈。GANcraft 所提出的体系结构能够处理非常复杂的虚拟世界。研究人员表示在实验中,人们可以使用尺寸为 512×512×256 网格的内容,这相当于现实世界中的 65 英亩或 32 个足球场。
最后,天空怎么办呢?以往基于体素的神经渲染方法无法为距离为「无限远」的天空建模,但天空显然是拟真图像的重要部分。在 GANcraft 中,算法使用附加的 MLP 对天空进行建模,MLP 将视角射线方向转换为特征向量,其大小与辐射场中的点特征相同。然后,该特征向量会用作完全不透明的最终射线样本,根据射线的残留透射率混合到像素特征中。
GANcraft 的生成过程取决于风格图像。在训练过程中,我们需要使用拟真图像作为风格参考,这就是生成的图像与其对应的伪实况之间对于重建损失不一致的原因。在评估期间,我们可以通过为 GANcraft 提供不同风格的图像来控制输出样式。
GANcraft 的介绍视频:
这就是游戏世界的未来吗?或许在《我的世界》未来的版本中,我们就能看到这项新技术的应用。
论文《 GANcraft: Unsupervised 3D Neural Rendering of Minecraft Worlds 》
论文链接:https://arxiv.org/abs/2104.07659
参考内容:
https://nvlabs.github.io/GANcraft/
建新·见智 —— 2021亚马逊云科技 AI 在线大会
4月22日 14:00 - 18:00
为什么有那么多的机器学习负载选择亚马逊云科技?大规模机器学习、企业数字化转型如何实现?
《建新 · 见智——2021 亚马逊云科技 AI 在线大会》由亚马逊云科技全球人工智能技术副总裁及杰出科学家 Alex Smola、亚马逊云科技大中华区产品部总经理顾凡领衔,40多位重磅嘉宾将在主题演讲及6大分会场上为你深度剖析亚马逊云科技创新文化,揭秘 AI/ML 如何帮助企业加速创新。
分会场一:亚马逊机器学习实践揭秘
分会场二:人工智能赋能企业数字化转型
分会场三:大规模机器学习实现之道
分会场四:AI 服务助力互联网快速创新
分会场五:开源开放与前沿趋
分会场六:合作共赢的智能生态
6大分会场,你对哪个主题更感兴趣?

©THEEND
转载请联系本公众号获得授权







![[图]跌落神坛的上网本:曾认为会颠覆笔记本行业](https://n.sinaimg.cn/spider2021417/366/w700h466/20210417/e809-knvsnuf9327334.jpg)