机器之心专栏
作者:中科大张举勇课题组
来自中科大的张举勇教授课题组联合杭州像衍科技有限公司与浙江大学,于近期一同提出一种基于单目 RGB 视频的高保真三维人体重建算法SelfRecon,该算法仅需输入目标对象一段十几秒的自转视频,即可恢复重建对象的高保真数字化身。
近年来,随着图形技术的快速发展,各类虚拟数字人开始走入我们的日常,如数字航天员小诤、百度智能云 AI 手语主播、腾讯 3D 手语数智人 “聆语” 等纷纷亮相。实际上,三维数字人技术于我们的日常生活早有应用,如早在 2015 年上映的电影《速度与激情 7》中,就曾使用三维数字人技术帮助复活已故演员保罗沃克。
在去年的 GTC 大会上,英伟达更是基于高保真虚拟数字人技术举办了一场以假乱真的产品发布会,一时引发广泛关社会关注与讨论。同样地, 英伟达的数字人生成与建模同样也需要高昂的人力成本和高端的硬件支持。据悉,英伟达为保证报告视频中的老黄足够真实,期间调配了 34 个 3D 美术师、15 个软件研究人员,实现了 21 个不同版本的假老黄,最终展示给我们的则是从中选择的最为理想的一个。在该版本中,英伟达可以说整合了各种建模、编辑、驱动以及渲染技术,更是借助工业级高规格采集设备来保证重建的三维人体的几何材质精度,在耗时良久的情况下才达到如下所示的难辨真假的视觉效果。
然而,如此高昂的人力成本与时间成本、以及技术上的复杂性和专业性要求不可避免地导致相关方法难以推广至一般消费市场。另一方面,随着移动端手机设备的普及,单目 RGB 数据开始变得唾手可得,因此若仅仅依靠单目 RGB 视频数据就能高效便捷地获取普通对象的高质量可驱动数字化身,将切实地推动虚拟数字人及其相关技术应用与发展,而这也是三维视觉以及图形学领域一直致力于的研究目标。
为此,中科大张举勇教授课题组联合杭州像衍科技有限公司与浙江大学,于近期一同提出一种基于单目 RGB 视频的高保真三维人体重建算法SelfRecon,该算法仅需输入目标对象一段十几秒的自转视频,即可恢复重建对象的高保真数字化身。该研究工作已被 CVPR 2022 接收,并将于 CVPR 会议期间进行口头报告。

论文链接: https://arxiv.org/abs/2201.12792
项目主页: https://jby1993.github.io/SelfRecon/
代码链接: https://github.com/jby1993/SelfReconCode
 基于 SelfRecon 生成的纹理模型
基于 SelfRecon 生成的纹理模型SelfRecon 的重建效果如下所示。基于普通智能手机拍摄的自转视频,SelfRecon 可准确跟踪三维动态几何,并有效还原宽松衣服的动态效果。得益于输入的简易性,基于 SelfRecon 将有望大幅度降低人们获取个人高保真数字化身的成本与难度。
SelfRecon: 重建展示
SelfRecon 的算法流程如下所示,SelfRecon 创新地整合了三维显式表示与三维隐式表示,并利用神经可微渲染来自动化地构建目标对象的三维数字表示。具体地,SelfRecon 一方面使用基于 MLP 的隐式函数来表示基准空间的符号距离场。同时,在优化该 MLP 网络参数的过程中,SelfRecon 会周期性地从隐式表示的符号距离场中提取显式网格,接着 SelfRecon 会利用该显式表示相关的可微遮罩 Loss 来保证显式网格能够维持和真值相近的几何形状。另一方面,SelfRecon 精巧地设计了一种非刚性射线投射算法来求解射线与隐式基准表面的精准交点。进一步地,SelfRecon 利用隐式神经渲染以及交点处的相关信息来生成该射线的渲染颜色,并将渲染结果与采集到的颜色真值进行比对,从而自监督地逐渐优化出目标对象的隐式几何表示。在该过程中,SelfRecon 也提出并应用匹配损失来保证三维显式表示与隐式表示的一致性,进而有效提升优化过程的鲁棒性。
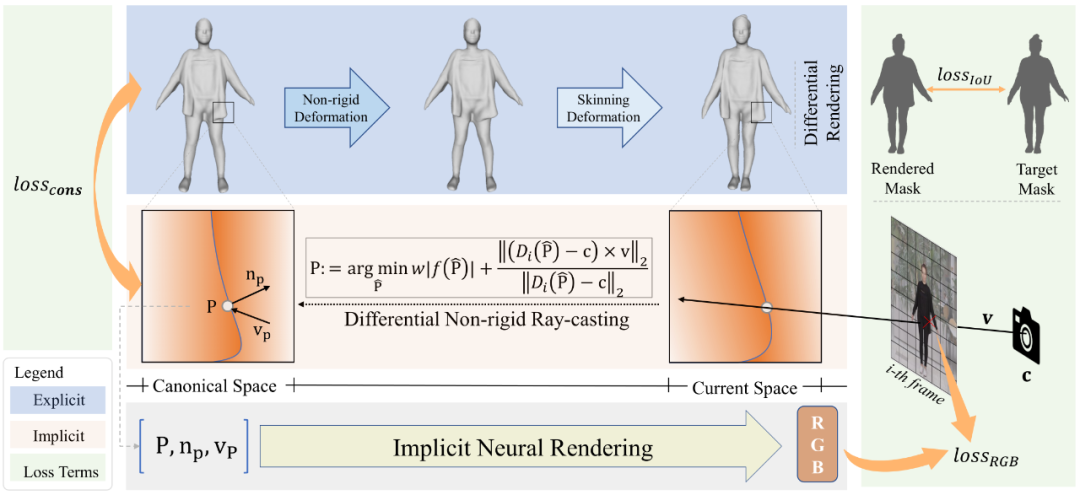 SelfRecon 的算法流程图
SelfRecon 的算法流程图如下所示,SelfRecon 通过前向变形来建立基准帧与当前帧的联系。首先,SelfRecon 会通过另一个隐式神经网络来建模人体运动带动的衣物的非刚性变形。接着,SelfRecon 会使用预生成的蒙皮变形场和当前帧的人体 Pose 信息对目标人体进行铰链变形。
SelfRecon: 前向变形图
在计算射线和隐式基准曲面交点的过程中,SelfRecon 首先计算射线与当前帧显式网格的交点,接着 SelfRecon 利用当前帧显式网格和基准显式网格的拓扑一致性来获得该交点在基准显式网格上的对应点。同时,由于显式网格理论上是隐式曲面的分片线性估计,因此该交点应接近于射线与隐式曲面的准确交点。基于此,SelfRecon 将射线与基准显式网格的交点作为射线与基准隐式表示交点的初值,并迭代求解相关能量来快速生成射线和基准隐式曲面的准确交点 P。此外,SelfRecon 通过推导隐式表示关于 P 的隐式微分公式来生成 P 关于各优化变量的一阶导数,进而使得整个渲染过程可以有效反向传播梯度,并端到端地优化整个渲染过程。相关过程如下所示:
SelfRecon: 可微非刚性射线投射
下图展示了 SelfRecon 各个损失能量项的有效性。如下所示,虽然仅使用遮罩损失也能够恢复整体的人体形状,但相关结果并无法重建目标对象正确的凹凸形状。而在添加使用了神经渲染损失之后,可以发现重建结果得到明显改进,这也证明了颜色信息的重要作用。进一步,SelfRecon 也支持利用预测的法向对优化过程进行额外监督,从而进一步提高 SelfRecon 的重建质量。
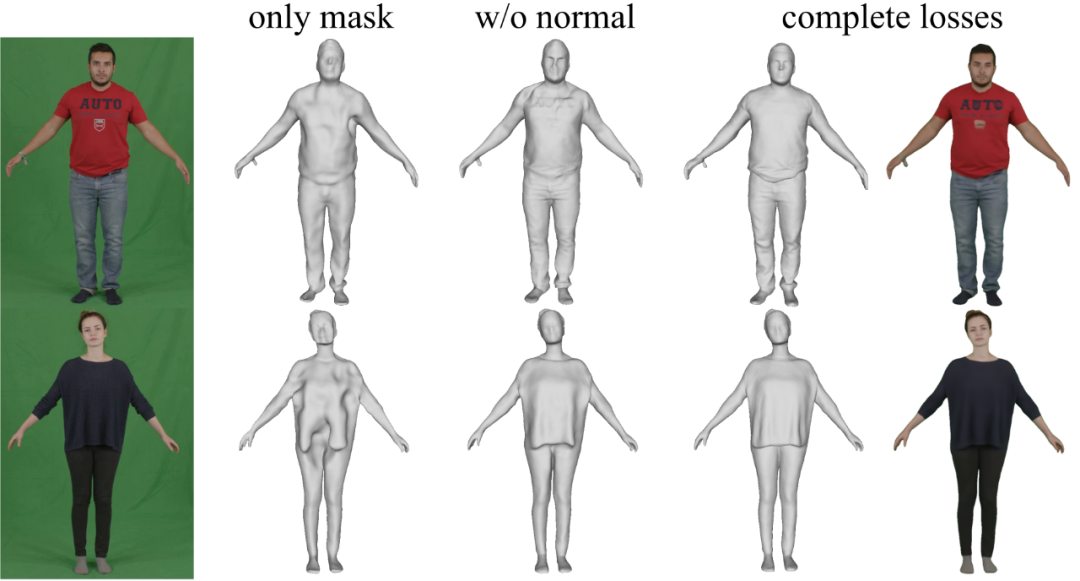 SelfRecon 各损失的作用
SelfRecon 各损失的作用下图展示了 SelfRecon 与当前最优方法的定性对比。如下所示,SelfRecon 获得了 state-of-the-art 的重建效果。效果上,SelfRecon 可以对宽松衣物进行准确建模,在得到光滑曲面的同时,还能较好地恢复一些几何细节,包括衣物的褶皱,手指和面部特征等。
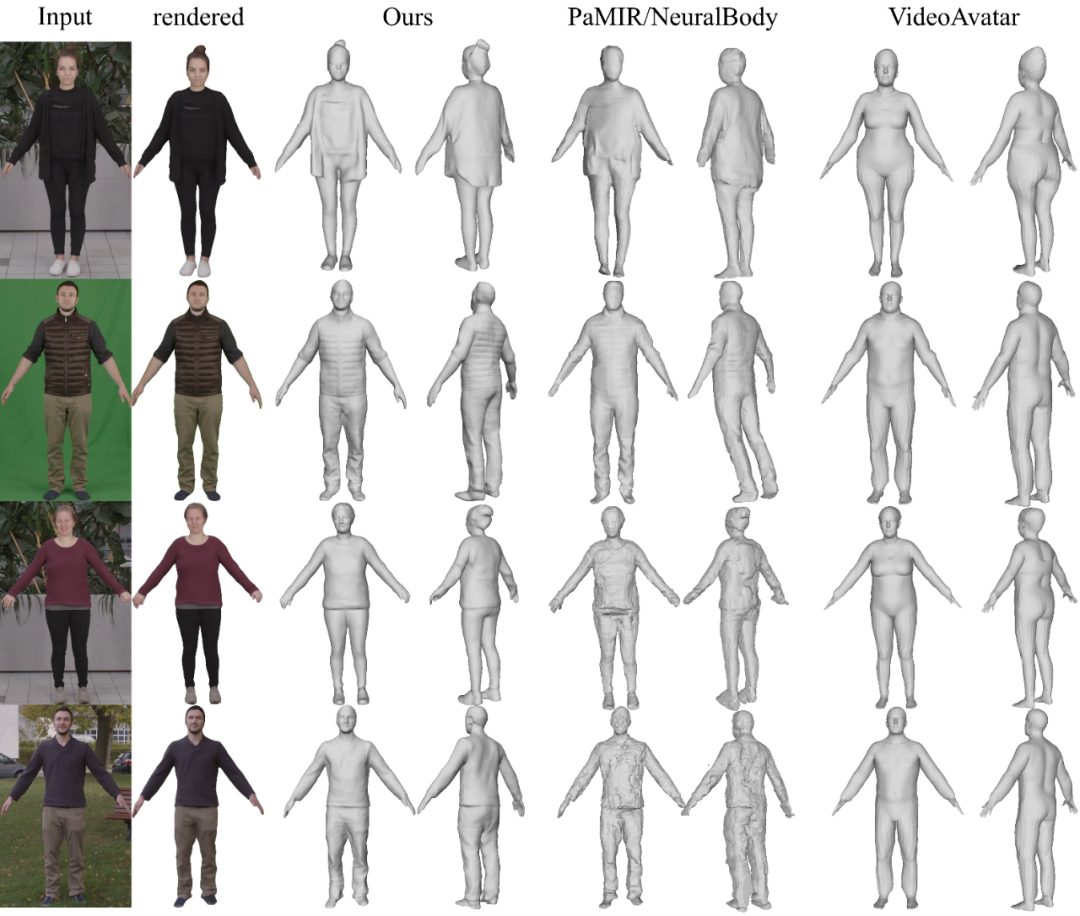 SelfRecon 与其他方法的比较
SelfRecon 与其他方法的比较另外,SelfRecon 的重建结果天然地支持高清纹理提取和姿态驱动,以下视频展示了相关驱动效果。
关于 SelfRecon 的更多算法细节与实验结果,请参考项目主页与论文。