今天,分享一篇让多个模型达成迭代共识,MIT &谷歌新方法激发模型「群体智慧」,希望以下让多个模型达成迭代共识,MIT &谷歌新方法激发模型「群体智慧」的内容对您有用。
选自arXiv
机器之心编译
编辑:rome rome
在给定一组大型预训练模型的情况下,如何利用来自不同模型的专家知识来解决零样本多模态任务,并能同时解决图像生成、视频问答、小学数学和机器人操作等任务?来自 MIT CSAIL 和谷歌大脑的研究者在这篇论文中给出了他们的解决方案。
目前大型预训练模型已经在不同领域显示出了显著的零样本泛化能力:从零样本图像生成、自然语言处理到机器推理、动作规划。这些模型使用来自互联网的大型数据集进行训练,这些数据集的规模通常达到数十亿。
单个预训练模型会攫取互联网知识的不同方面,其中语言模型(LM)挖掘新闻、文章和维基百科页面中的文本信息,视觉语言模型(VLM)对视觉和文本信息之间的映射进行建模。虽然希望建立能够捕捉互联网数据所有可能模式的预训练模型,但这样一个全面的模型很难获得和维护,需要大量的内存、大量的精力、数月的训练时间和数百万(或千万)美元。
在这种情况下,一种扩展性更强的替代方法是将不同的预训练模型组合在一起,利用来自不同专家模型的知识来解决复杂的多模态任务。构建用于组合多个模型的统一框架面临很大的挑战,Alayrac 等人之前的工作已经探索了构建预训练模型的两种主要方式:在大型数据集上联合微调模型或者使用通用接口(如语言)组合不同的模型。
但是,这些工作有几个关键限制。首先,简单地组合模型并不能充分利用每个预训练模型,因为模型之间没有闭环反馈。级联模型,如 Socratic 模型,允许单向通信,但防止后期模型处理的信息传播回早期模型以纠正错误。其次,通用接口仅限特定类型的模型。在 Socratic 模型中,语言被用作中间连接,但语言接口不足以解决许多现实世界的任务,例如需要连续表示的连续机器人控制。此外,Socratic 模型需要预先设计的语言模板用于模型之间的通信,这限制了可扩展性。第三,联合微调多个模型需要仔细优化,以确保模型行为保持稳定。这种模型还需要大量内存和大数据集,并且只能用于解决特定任务。
为了解决这些困难,来自 MIT CSAIL 和谷歌大脑的研究者提出了一个统一的框架,在没有任何训练 / 微调的情况下,以零样本方式构建模型。

论文地址:https://arxiv.org/pdf/2210.11522.pdf
他们的框架使用单个模型作为生成器和评分器。生成器迭代地生成答案,每个评分器提供反馈分数,表示它们的意见。生成器细化其输出,直到所有评分器达成共识。生成器和评分器之间的这种迭代闭环通信使模型能够纠正由其他模型引起的错误,从而大大提高性能。

下图 1 为框架。
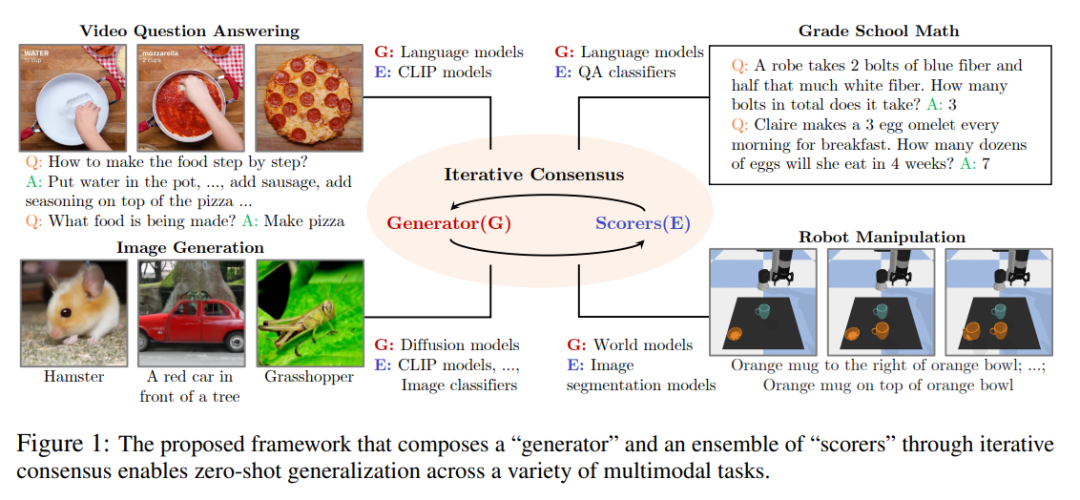
集体评分器的灵感来源于「群体智慧」的理念。每个评分器都向生成器提供反馈,以弥补其他评分器的潜在弱点,如视觉语言评分器可以纠正语言模型的偏差。当来自同一系列的不同预训练模型实例具有不同的输出,这会生成更稳健的评分器。作者已经证明,用这样一组评分器引导生成器显著优于由单个评分器指导的生成器。
这些观察结果表明,作者所提出的方法作为一个通用框架的有效性,可以用于构建解决各种零样本多模态任务的预训练模型。

方法概览
作者的目标是在给定一组大型预训练模型的情况下,利用来自不同模型的专家知识来解决零样本多模态任务。他们将预训练模型分为了两类,即生成器(G)如 GPT 和可以生成候选解的扩散模型,以及评分器(E)如 CLIP 和可以输出标量分数以评估每个生成解的分类器。
作者提出了 PIC(通过迭代共识合成预训练模型的集合),这是一个为多模态任务合成预训练模型集合的框架。PIC 的核心思想是通过迭代优化生成解,在迭代优化中利用来自不同模型的知识共同构建共识解。在 PIC 中,生成器 G 迭代并顺序地生成候选解,每个候选解都基于来自一组评分器的反馈进行细化。特别地,作者寻求一个解 x^∗,使得

其中 {En} 是评分器的集合。在每一次迭代中,作者对解进行细化,使其得分低于前一次迭代。方程(1)中描述的过程收敛到一个解,该解可使多个预训练模型的能量最小化,从而最大化生成器和评分器之间的一致性。与 Socratic 模型不同,不同的预训练模型被顺序调用,通过闭环迭代细化,可以获得 x^∗ 使生成器和评分器能够相互通信,对最终解达成一致。
接下来作者展示了 PIC 如何广泛应用于图像生成、视频问答、小学数学和机器人操作等任务。为了优化方程(1),作者考虑了两种不同的优化过程:1) 利用每个评分器 E_n(x)的梯度的连续方法;2)直接采样可能解的离散方法。

实验结果
作者对所提框架在四个代表性任务上合成预训练模型进行了评估,它们分别是图像生成、视频问答、小学数学和机器人操作。
图像生成
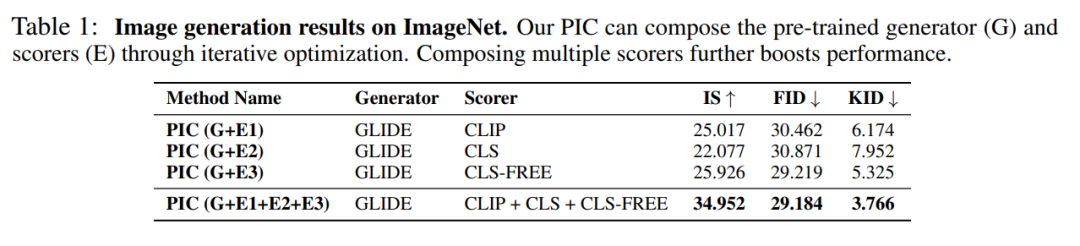
下表 1 是在 ImageNet 上的零样本图像生成的评估。合成多个评分器进一步提高了性能。
视频问答
作者在 ActivityNet QA 上将 PIC 与 SOTA VQA 方法之一 JustAsk 进行比较。在下表 2 中,JustAsk(FT)在 ActivityNetQA 上进行了微调,从而获得了最佳结果。对于零样本 VQA,作者的方法(PIC)明显优于 JustAsk(预训练)。使用多个评分器可以进一步提高性能。
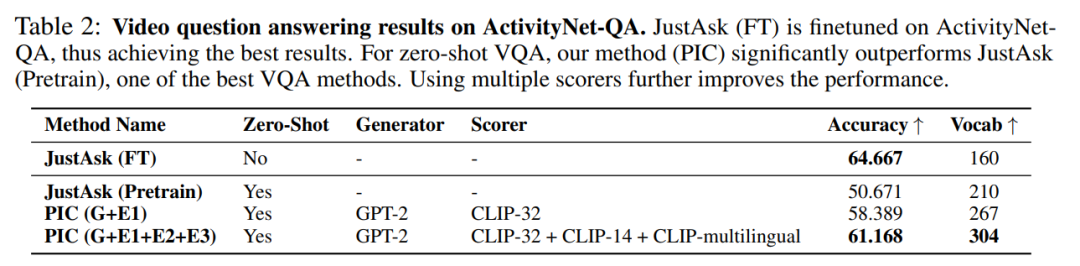
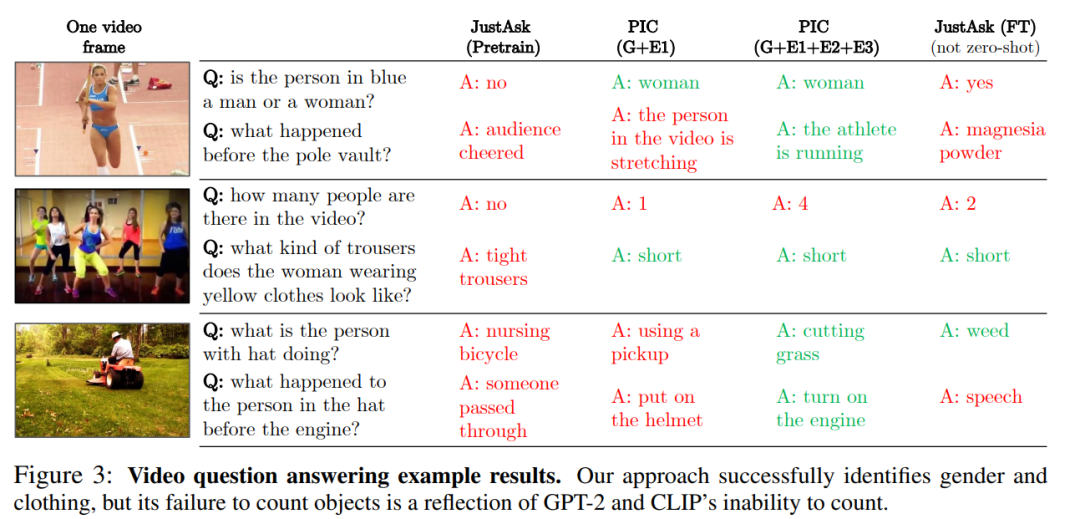
在下图 3 中,作者展示了给定视频(仅显示单个视频帧)和问题情况下不同方法生成的答案。作者的方法成功地识别了性别和服装,但在如何计算数字上所有模型都失败。
小学数学
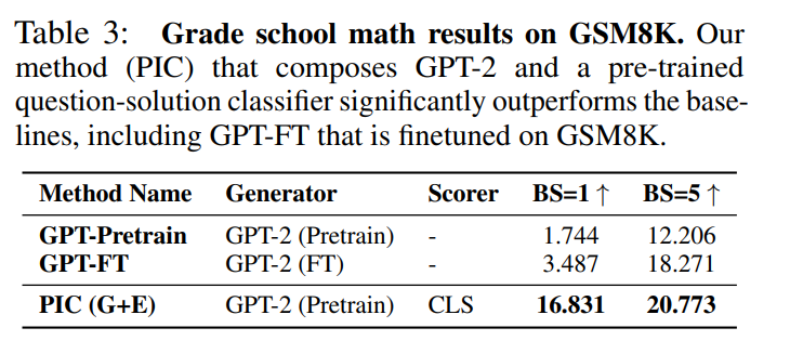
在下表 3 中,作者用 PIC、GPT-Pretrain、GPT-FT 三个模型来解决 GSM8K 上的数学问题,并做了对比。PIC 由 GPT-2 和预训练问题解分类器组成,PIC 优势明显甚至比在 GSM8K 上进行微调的 GPT-FT 也好很多。
下图 4 显示了不同方法的结果。作者的方法可以解决加、减、乘、除的数学题,甚至是三位数的解。相比之下,GPT-FT 却无法理解数学题目。

机器人操作
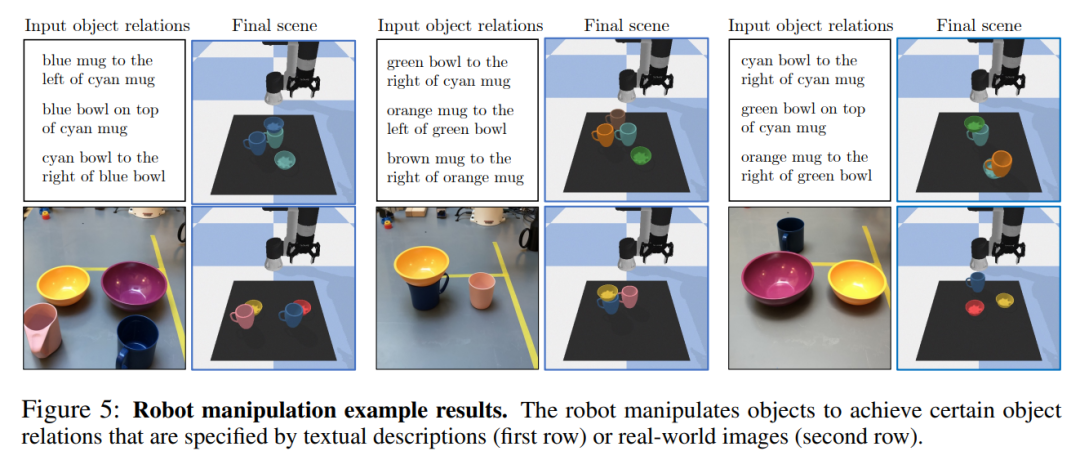
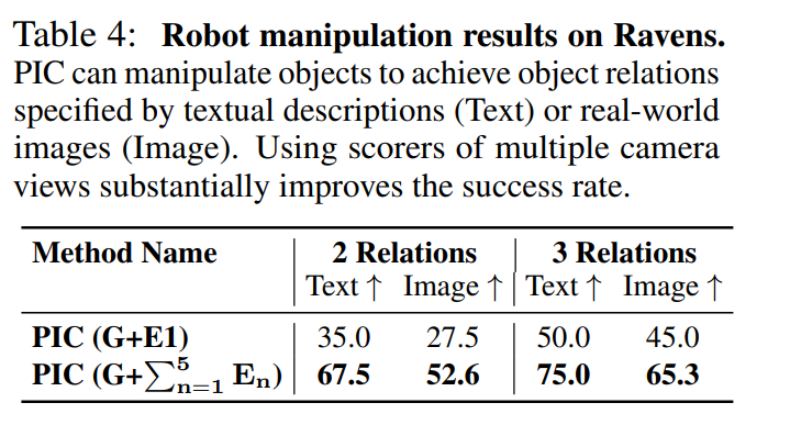
作者评估了所提的操作对象方法在实现由文本描述(Text)或真实世界图像(Image)指定的对象关系的效果。在下表 4 中,作者发现使用多个相机视角的评分器可以显著提高两种设置的准确性。
下图 5 显示了使用所提方法操作对象以完成给定任务的示例结果。作者的方法能够让机器人在给定语言目标或图像目标的情况下,对不同大小、颜色和形状的对象进行零样本操作。