今天,分享一篇把Transformer当通用计算机用,还能执行in-context learning算法,这项研究脑洞大开,希望以下把Transformer当通用计算机用,还能执行in-context learning算法,这项研究脑洞大开的内容对您有用。
机器之心报道
编辑:romerome、张倩
一个 13 层的 Transformer 能干什么用?模拟基本计算器、基本线性代数库和使用反向传播的 in-context learning 算法都可以。
Transformer 已成为各种机器学习任务的热门选择,并且取得了很好的效果,那它还能怎么用?脑洞大开的研究者竟然想用它来设计可编程计算机!
这篇论文的作者来自普林斯顿大学和威斯康星大学,标题为《Looped Transformers as Programmable Computers》,旨在探索如何用 Transformer 来实现通用计算机。
具体来说,作者提出了一个将 transformer 网络用作通用计算机的框架,方法是使用特定权重对它们进行编程并将它们置于循环(loop)中。在这个框架中,输入序列充当穿孔卡片,由指令和用于数据读 / 写的内存组成。
作者证明了恒定数量的编码器层可以模拟基本计算块。使用这些构建块,他们模拟了一个小型指令集计算机。这使得他们能够将迭代算法映射到可以由循环的(looped)13 层 transformer 执行的程序。他们展示了这个 transformer 如何在其输入的指导下模拟一个基本的计算器、一个基本的线性代数库和使用反向传播的 in-context learning 算法。这项工作突出了注意力机制的多功能性,并证明即使是浅层 transformer 也可以执行成熟的通用程序。
论文概述
Transformer (TF) 已成为各种机器学习任务的热门选择,它在自然语言处理和计算机视觉等领域很多问题上取得了最先进的成果。Transformer 成功的一个关键原因是能够通过注意力机制捕捉 higher-order 关系和 long-range 依赖关系。这使得 TF 可以对上下文信息进行建模,并使其在机器翻译和语言建模等任务中更加有效,在这些任务中 Transformer 的表现一直优于其它方法。
GPT-3(175B 参数)和 PaLM(540B 参数)等具有上千亿参数的语言模型在许多自然语言处理任务上都取得了最先进的性能。有趣的是,这些大型语言模型 (LLM) 中的一些还可以执行 in-context learning (ICL) ,根据简短 prompt 和一些示例即时适应和执行特定任务。LLM 的 ICL 能力是在没有可以训练的情况下就具备,并允许这些大型模型有效地执行新任务而无需更新权重。
令人惊讶的是,通过 ICL,LLM 可以执行算法任务和推理,并且 [Nye et al. [2021], Wei et al. [2022c], Lewkowycz et al. [2022], Wei et al. [2022b], Zhou et al. [2022]] 等人的工作已经证明其可行性。[Zhou et al. [2022] ] 等的工作证明,当给出多位加法算法和一些加法示例的 prompt 时,LLM 可以成功地对未知用例进行加法运算。这些结果表明,LLM 可以根据算法原理并在推理时对给定输入执行 pre-instructed 的命令,就好像将自然语言解释为代码一样。
有证据表明,Transformer 可以模拟具有足够深度的图灵机或 Attention 层之间的递归链接 [Pérez et al. [2021], Pérez et al. [2019], Wei et al. [2022a]]。这证明了 Transformer 网络精确遵循输入指定的算法指令的潜力。然而,这些构造相对笼统,无法深入理解如何创建能够执行特定算法任务的 Transformer。
然而更专业的设计可以让 TF 执行更高级的程序。如 [Weiss et al. [2021]] 设计了一种计算模型和一种编程语言,可将简单的选择和聚合命令映射到索引输入 token。这种语言可用于创建多种有趣的算法,例如 token 计数、排序、创建直方图和识别 Dyck-k 语言。然后可以将用受限访问序列处理语言 (RASP) 编写的程序映射到 Transformer 网络中,Transformer 网络的大小通常会随着程序的大小而变化。
另一项研究展示了选择 Transformer 模型权重的方法,以用作动态学习线性回归模型的优化算法,在给定训练数据作为输入时在推理时执行隐式训练。这些方法通常需要与学习算法的迭代次数成比例的层数,并且仅限于一个损失函数和模型集合。
对 Transformer 模型进行编程以模拟图灵机的抽象计算的能力、RASP 等语言的专用命令以及 ICL 的特定算法,突出了 Transformer 网络作为多功能可编程计算机的潜力。
本文作者的研究旨在研究探索这一充满希望的前景,揭示 Attention 机制如何能够模拟受指令集架构启发的通用计算机。
将 Transformer 作为可编程计算机
在本文中,作者展示了 Transformer 网络可以通过使用特定权重对它们进行硬编码并将它们置于一个循环中来模拟复杂的算法和程序。作者通过对 Attention 进行逆向工程来模拟基本计算块来做到这一点,例如对输入序列的编辑操作、非线性函数、函数调用、程序计数器和条件分支。作者的论文证明了使用单个循环或递归将 Transformer 的输出序列连接回其输入的重要性,从而避免对深度模型的需要。

论文地址:https://arxiv.org/pdf/2301.13196.pdf
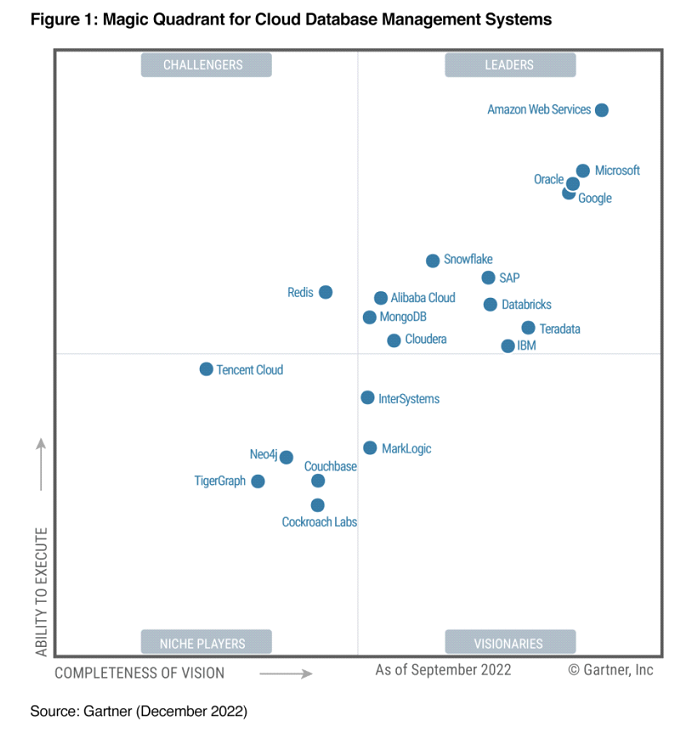
作者通过设计一个 Transformer 来实现这一点,该 Transformer 可以执行以单个指令的通用版本编写的程序,称为 SUBLEQ (A,B,C),即如果小于或等于零,则相减并分支。SUBLEQ 是一种单指令语言,定义了单指令集计算机(one-instruction set computer,简写为 OISC)。SUBLEQ 由 3 个内存地址操作数组成,执行时用存储器地址 B 的值减去存储器地址 A 的值,结果存入 B。如果 B 的结果小于等于 0,则跳转到地址 C,否则继续执行下一条指令。但这条指令能够定义通用计算机。
作者构造了实现类似 SUBLEQ 程序的显式 Transformer,作者称之为 FLEQ 的更灵活的单指令,其形式为
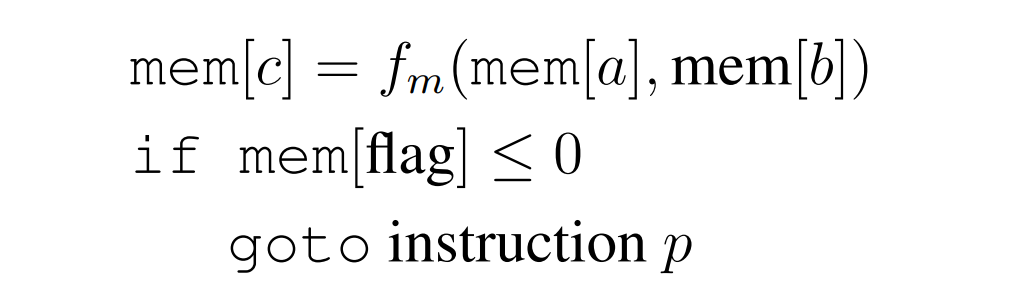
其中 f_m 可以从一组函数(矩阵乘法 / 非线性函数 / 多项式等)中选择,可以将其硬编码到网络中。可以执行 FLEQ 程序的循环 Transformer 的深度不依赖于程序的深度或代码的行数,而是取决于实现单个 FLEQ 指令所需的深度,这是不变的。这是通过在输入序列上循环运行 Transformer 来实现的,类似于 CPU 的运行方式。
作者使用这个框架,展示了在推理时模拟各种函数的能力,包括一个基本的计算器、一个基本的线性代数库(矩阵转置、乘法、求逆、幂迭代)和在隐式完全连接网络上实现反向传播的 ICL。输入序列或 prompt 可当成穿孔卡片,包括 Transformer 需要执行的指令,同时为存储和处理程序中使用的变量提供空间。用于执行这些程序的 Transformer 网络的深度都小于或等于 13,并且提供了所有这些模型的权重矩阵。下面的定理总结了作者的主要发现:
定理 1:存在一个少于 13 层的循环 Transformer,它可以模拟通用计算机(文章第 5 节)、基本计算器(文章第 7 节)、数值线性代数方法,如近似矩阵逆和幂迭代(文章第 8 节),以及基于神经网络的 ICL 算法(如 SGD)(文章第 9 节)。
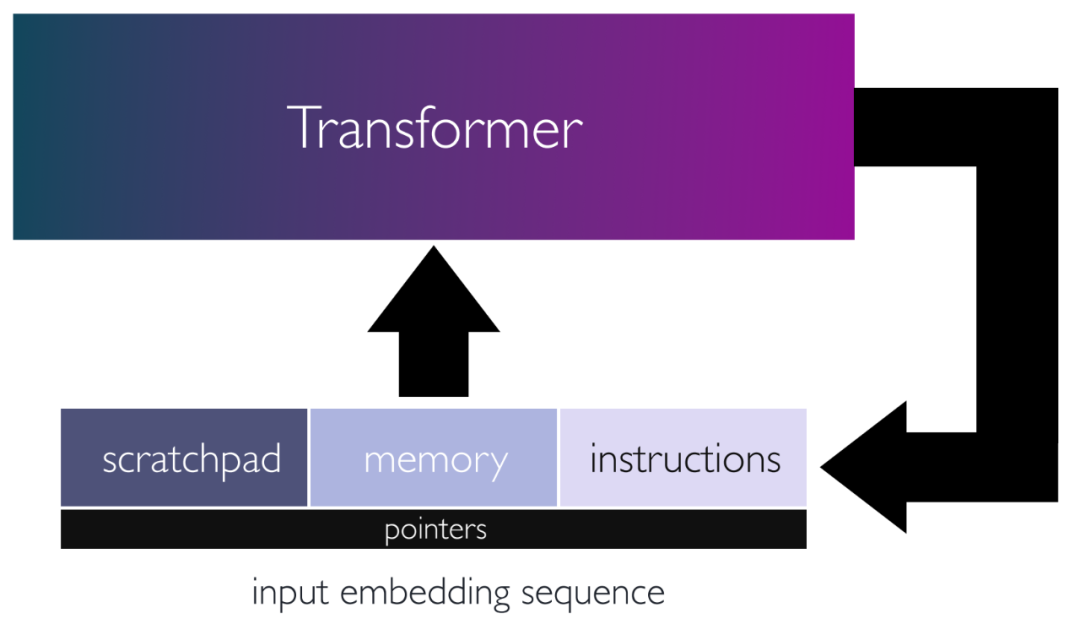
图 1:循环 Transformer 架构示意图,其中输入序列存储命令,从中读取 / 写入数据的内存以及存储中间结果的暂存器。输入由网络处理,输出用作新输入,允许网络迭代更新隐式状态并执行复杂计算。
作者的研究强调了 Attention 机制的灵活性和单循环的重要性,这使得设计可以模拟复杂迭代算法和执行通用程序的模型成为可能。并进一步证明了 Transformer 模型高效执行复杂数学和算法任务的能力。可以想象,现代 Transformer (如 GPT-3),在执行各种任务时使用类似的内部子程序。在某种程度上,当给出上下文示例和说明时,可以启发这些模型特定技巧或算法的能力,类似于函数调用。然而,应该谨慎对待这个假设,因为作者设计结构的方式与现实世界语言模型的训练方式没有任何相似之处。
作者希望他们的研究能够鼓励进一步研究 Attention 机制的潜力,以及语言模型执行算法指令的能力。作者提出的设计可以帮助确定执行特定算法任务所需的最小 Transformer 网络规模。此外,作者还希望其发现有助于启发开发方法,从而通过利用更小的、逆向工程的 Transformer 网络来完成特定的算法任务,从而增强训练语言模型的能力。
构建面向通用计算的 Transformer 模块
要使用 Transformer 网络构建通用计算框架,需要专门的计算块。将这些块组装来创建所需的最终功能。下面重点介绍 Transformer 层可以执行的各种操作。这些操作将为创建更复杂的例程和算法提供基础。这些操作的目的是彼此可互操作,利用 Attention 执行各种任务的能力,例如生成近似置换矩阵和通过 sigmoid 函数逼近一般函数。
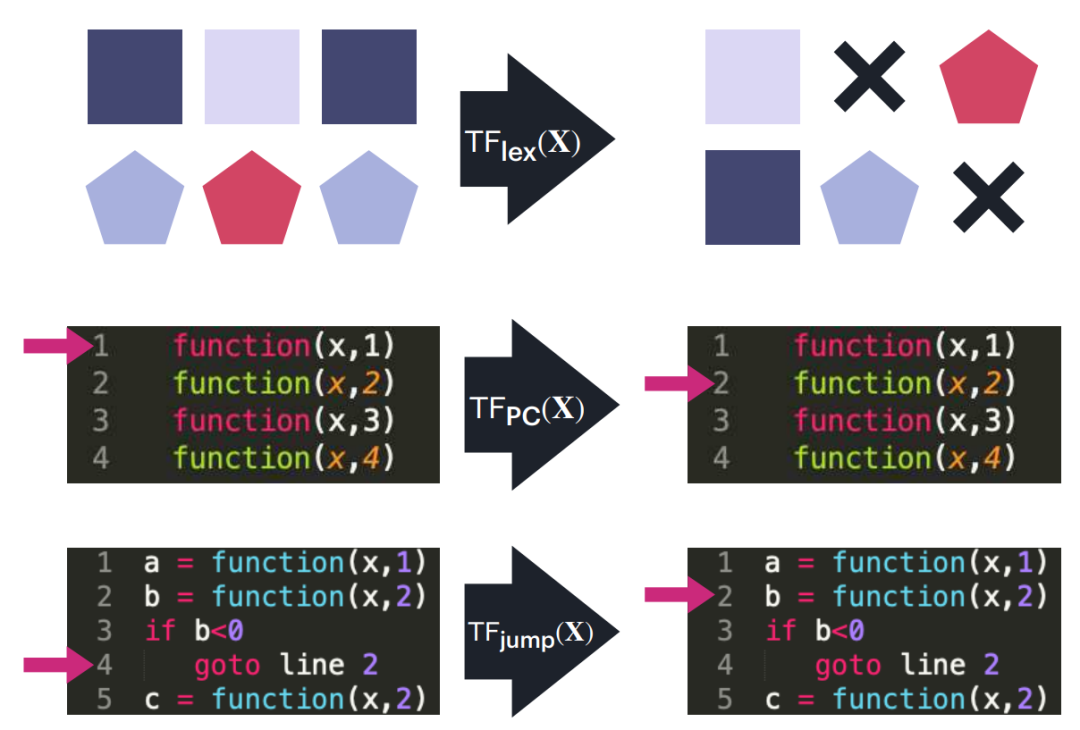
图 2: 用作实现小型指令集计算机构建块的三个 Transformer 块的示意图。这些块处理输入序列中的编辑操作(例如从一个块移动或复制到另一个块),跟踪程序计数器,并在满足指定条件时执行程序计数器跳转。
位置编码、程序计数器和数据指针
Transformer 通常需要执行迭代算法或执行一系列命令。为实现这一点,作者使用一个循环访问命令的程序计数器。计数器包含存储下一个命令的位置的编码。此外,命令可能具有指向命令需要读取和写入的数据位置的数据指针。程序计数器和数据指针都使用与前一段中讨论的相同的位置编码。

作者的位置编码方案也可用于指向特定数据位置以进行读取或写入,这将在下一节论述。这是通过使用相同的二进制向量作为程序计数器和数据指针的位置编码来实现的。此外,这种指向特定数据位置的技术使 Transformer 能够在执行算法或构建以实现的命令序列期间有效地读取 / 写入数据。
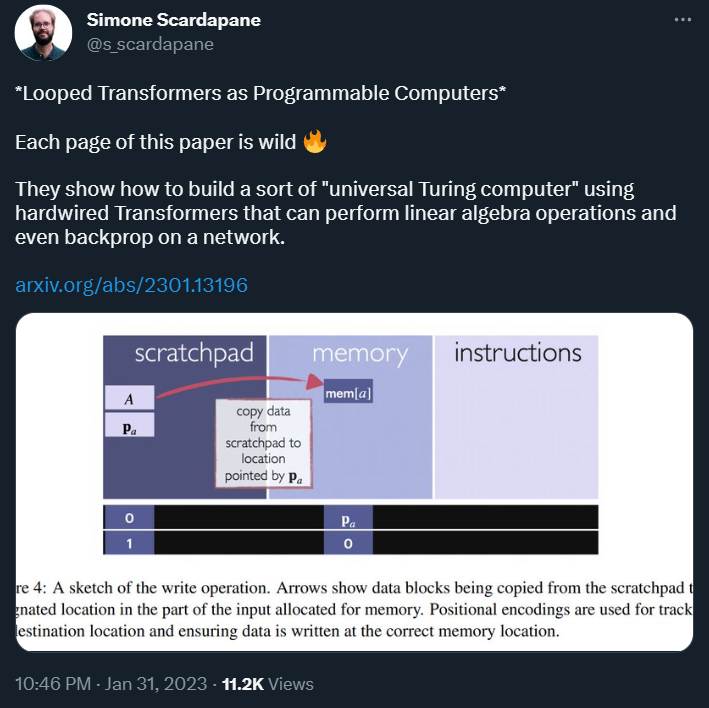
读 / 写:将数据、指令复制到暂存器或从暂存器取出
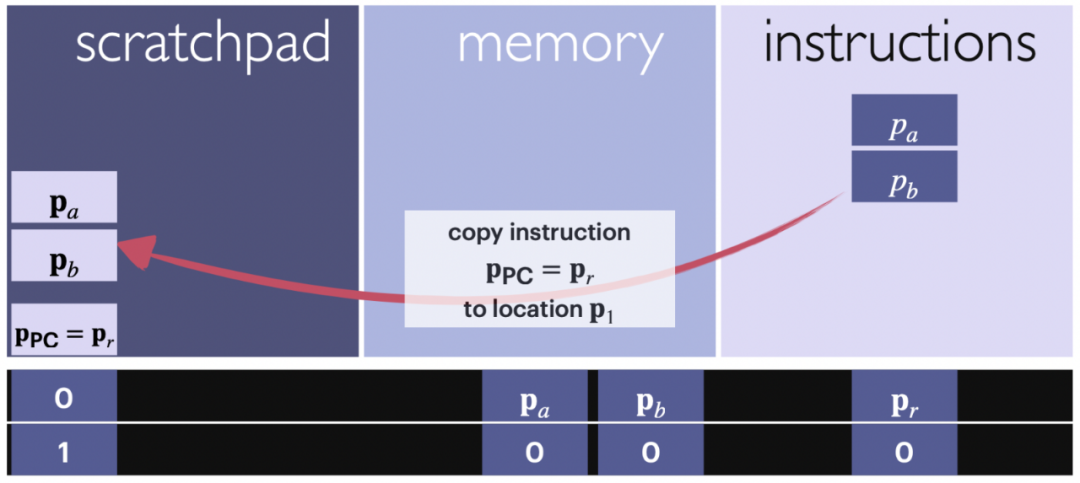
图 3: 读取操作的示意图。箭头显示从分配给暂存器命令的输入部分复制的命令块。一条指令是一组指针。位置编码和计数器用于跟踪什么内容被复制到哪里。
下面的引理说明,程序计数器指向的命令或当前命令中指定位置的数据可以复制到暂存器以供进一步计算。程序计数器的位置通常位于暂存器内容的正下方,但可以任意更改。在整个计算过程中将其保持在特定位置有助于保持结构的良好组织。

下一个引理解释了存储在暂存器中的向量 v 可以复制到存储器中的指定位置,如暂存器本身指定的那样。这允许将数据从暂存器传输到内存中的特定位置以供进一步使用或存储。
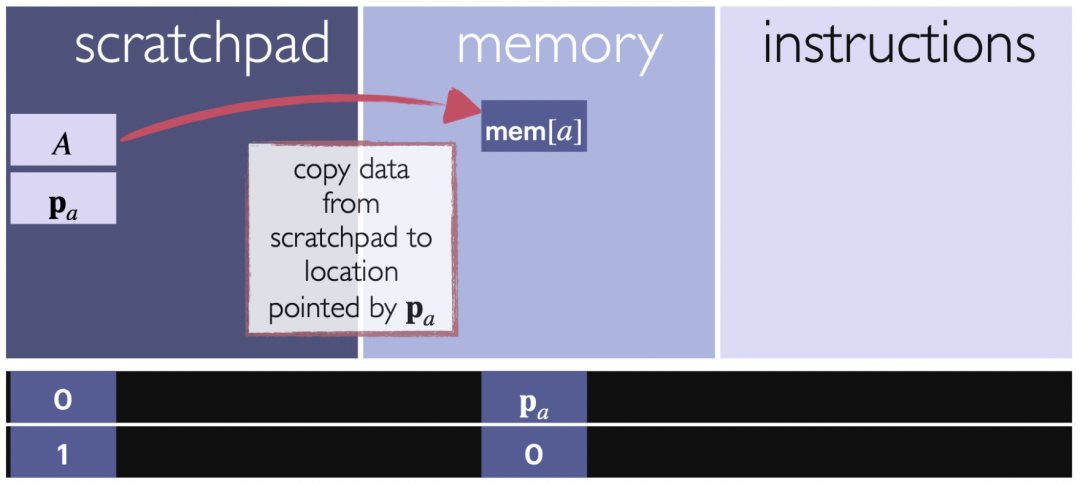
图 4: 写操作的示意图。箭头显示数据块正在从暂存器复制到分配给内存的输入部分中的指定位置。位置编码用于跟踪目标位置并确保数据写入正确的内存位置。

条件分支
在这一部分,作者实现一个条件分支指令,该指令评估条件并在条件为真时将程序计数器设置到指定位置,或者在条件为假时将程序计数器递增 1。
命令的形式如下:如果 mem [a]≤0,则转到 i,其中 mem [a] 是输入序列的内存部分中某个位置的值。该命令有两部分:判断不等式和修改程序计数器。
模拟通用单指令集计算机
SUBLEQ Transformer
Mavaddat 和 Parhami 早在 1988 年已经证明存在一条指令,任何计算机程序都可以转换为由这条指令的实例化组成的程序。这种指令的一个变体是 SUBLEQ,能访问不同的寄存器或内存位置。
SUBLEQ 的工作方式很简单。它访问内存中的两个寄存器,获取它们内容的差异并将其存储回其中一个寄存器,然后如果结果为负,则它跳转到不同的预定义代码行,或者继续执行当前行的下一条指令。为执行 SUBLEQ 程序而构建的计算机称为单指令集计算机,并且是通用计算机,即,如果可以访问无限内存,它就是图灵完备的。

下面描述了一个循环 Transformer 的构造,它可以执行用特定指令集编写的程序。Transformer 跟踪代码行、内存位置和程序计数器,将输入的内存部分用作内存寄存器,将命令部分用作代码行 / 指令。暂存器用于记录每条指令涉及的加法和指针,读、写、条件分支操作等。

图 5: 实现 OISC 指令块的图形表示。前两个块将数据 / 命令传输到暂存器,第二个和第三个执行减法并存储结果,而最后一个执行完成指令的 if goto 命令。
FLEQ:更灵活的基于 Attention 的计算机
在这一节,作者对 FLEQ 进行介绍,它是对 SUBLEQ 的推广,它定义了一种更灵活的精简指令集计算机。这一隐含的附加指令集基于 SUBLEQ 的更高级版本,允许在同一 Transformer 网络中实现多种功能。作者使用术语 FLEQ 来指代指令、语言和它定义的基于 Attention 的计算机。
FLEQ 的设计允许通过生成比简单减法更通用的函数来实现复杂的算法,如矩阵乘法、平方根计算、激活函数等。
基于 Attention 的计算机执行周期。在循环 Transformer 的每次迭代中,根据程序计数器从输入中的指令集中提取一条指令。然后指令被复制到暂存器。根据要实现的功能,使用不同的功能块位置在局部记录该功能的结果。一旦计算出结果,它就会被复制回指令提供的指定内存位置。
执行周期类似于上一节中的单指令集计算机 (OISC),主要区别在于,对于每条指令,可以从预先选择的函数列表中进行选择,这些函数以任意数组的形式输入,如矩阵、向量和标量。
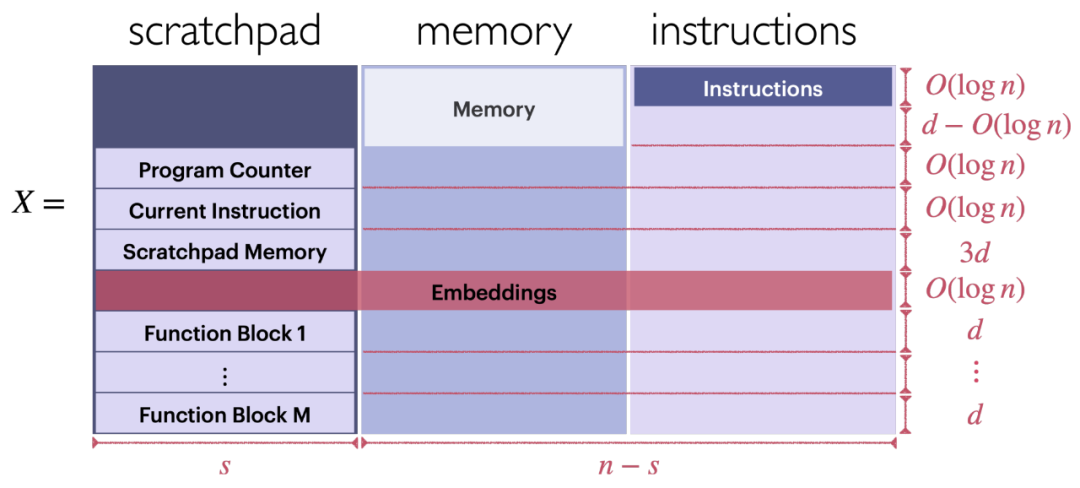
输入序列的格式。如图 6 所示,循环 Transformer 的输入 X,它可以执行一系列 FLEQ 指令构成的程序(X 由暂存器、存储器、指令等三部分构成)。
基于 Transformer 的功能块的格式。每个功能块都位于输入 X 的左下部分,如图 6 所示。
更多技术细节和示例请参阅原论文。