原标题:让机器说话的背后,智能语音数据还需要做出哪些努力?
人类对机器语音识别的探索始于20世纪50年代,迄今已逾70年。2016年,在深度神经网络的帮助下,机器语音识别准确率第一次达到人类水平,意味着智能语音技术落地期到来。
智能语音即实现人与机器以语言为纽带的通信。完整的人机对话包括声音信号的前端处理、将声音转为文字供机器处理、在机器生成语言之后,用语音合成技术将文本语言转化为声波,从而形成完整的人机语音交互。
目前,智能语音已广泛应用于智能手机、智能音箱、智能车载等场景。
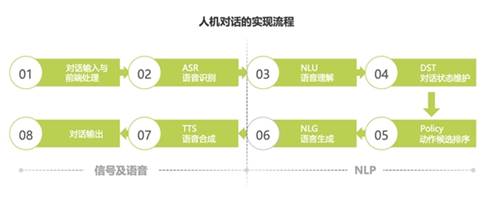 图源《2020年中国智能语音行业研究报告》
图源《2020年中国智能语音行业研究报告》在这些智能应用实现的背后,是数据对模型的训练发挥的巨大推动作用。目前,主流的方式以有监督模式为主。在该模式下,算法训练需要依靠标注数据进行反馈,对于数据有着强依赖性需求,这也带动了AI基础数据服务行业的繁荣。
作为AI数据采集标注服务头部企业,云测数据致力于为人工智能提供场景化、高质量的AI数据服务。通过严格控制前端采集标准、专业精准化标注、数据质量审核把控等流程,大幅提升AI数据交付质量与效率。
1、云测数据拥有语音场景的还原搭建能力
随着智能语音应用在多个垂直场景领域实现落地,人工智能对于场景化数据的需求量也越来越高。
云测数据的“场景化”服务模式,可以在语音类型的数据采集上满足特定人物(年纪、性别等)、特定场景(家居、办公、商业等)、不同方言的声音/文本数据采集;在数据标注上进行需求的梳理,通过先进的标注平台工具根据规则性的规范指导(如:同样一句话在不同交流目的中可能需要标注不同的内容)进行标注作业。
以目前广泛应用的语音助手为例,为了提高语音助手在不同场景下的识别能力,需要采集特殊场景下语音数据,比如“室外对话”、“室内对话”、“情感语音”、“嘈杂环境下对话”、“ 车载噪音”、“ 远场语音”等场景下的数据,这对数据服务企业的语音场景搭建能力提出了新的要求。
2、云测数据拥有丰富的语音数据备采资源
从业务流程角度来看,数据采集是人工智能数据服务行业全流程服务中的“第一步”,纯净、贴合AI应用场景的数据源可解决数据训练中90%的问题,之后将这些非结构化的数据经过精准的标注,才能被用于机器训练。
以云测数据为例我们了解到,单是语音采集,按照语种的不同,可细分为普通话采集、方言采集、英语采集、小语种采集等,这对数据采集服务企业的备采资源能力提出了极高的要求。
3、云测数据拥有对语音数据预处理的能力
为了产出更专业高效的语音数据,在语音等类型的数据生产过程中,云测数据通过严格的条件限制从根源上确保数据的质量。
如在音频类数据采集工具中的设置:
·静默时长:开始录音前后保留静音区域
·底噪:环境的嘈杂程度
·录音音量:录音音量的小大
·其他:不允许出现多字/少字
云测数据在进行语音采集时,会通过自动检测静默时长、底噪、录音音量等条件,对数据的质量进行严格控制,不满足录制要求的数据不允许通过。
4、云测数据拥有专业领域知识积累,可进行更精准的标注
以智能客服业务场景为例,当客服询问用户是否购买此商品时,各种用户会给出不同回答:“我要和家人商量一下”;“我会考虑”;“我现在不方便,你一会儿再打过来”等等,背后的意图有很多种,可能是暂不购买,暂不考虑,拒绝购买或者兴趣较大。那么,语音数据标注就需要对这些对话背后的意图进行标注和分类。
在云测数据,以智能客服单个场景的意图标注,就分为10-20个大类,上百个子类,根据业务需求可能还会有进一步的标注细分。除了对语音数据进行对话意图标注之外,语音数据的标注还包含对领域、槽位的识别标注、多角度泛化等。
从整体看来,目前智能语音应用整体还处于的发展中阶段,并不算真正意义上的“智能”。 随着技术的不断突破,智能语音将更加深入垂直场景,若想提高人们对智能语音相关应用的依赖和认可,首先要解决的就是人机交互的流畅性,而核心解决办法正是更高质量的AI训练数据。
但可以肯定的是,未来搭载更多、更成熟AI技术的智能语音应用将更加人性化,真正成为智能生活中的语音助手。