来源:机器之心
还在为不断的 debug 代码烦恼吗?
本地化 Bug 并修复程序是软件开发过程中的重要任务。在本篇论文中,来自微软 Cloud+AI 部门的研究者介绍了 DeepDebug,一种使用大型预训练模型 transformer 进行自动 debug 的方法。
首先,研究者基于 20 万个库中的函数训练了反向翻译模型。接下来,他们将注意力转向可以对其执行测试的 1 万个库,并在这些已经通过测试的库中创建所有函数的 buggy 版本。这些丰富的调试信息,例如栈追踪和打印语句,可以用于微调已在原始源代码上预训练的模型。最后,研究者通过将上下文窗口扩展到 buggy 函数本身外,并按优先级顺序添加一个由该函数的父类、导入、签名、文档字符串、方法主体组成的框架,从而增强了所有模型。
在 QuixBugs 基准上,研究者将 bug 的修补总数增加了 50%以上,同时将误报率从 35%降至 5%,并将超时(timeout)从 6 小时减少到 1 分钟。根据微软自己的可执行测试基准,此模型在不使用跟踪的情况下首次修复了 68%的 bug;而在添加跟踪之后,第一次尝试即可修复 75%的错误。为评估可执行的测试,作者接下来还将开源框架和验证集。

论文链接:https://arxiv.org/pdf/2105.09352.pdf
引言
自动程序修复中的主要范例是「生成和验证」方法。研究者遵循该方法,假设存在可以识别 bug 存在的一组测试函数,然后本地化 bug 并考虑候选的修补程序,直到找到满足测试的补丁程序为止。
在整个实验过程中,研究者使用了错误已被本地化为单个 buggy 方法的合成 bug,将其与其他上下文(例如函数文件中的上下文以及暴露 buggy 函数的栈追踪)作为输入,并将该输入提供给尝试生成修复好的函数的序列到序列 transformer。
研究者在部署方案中还尝试使用了栈追踪来本地化 bug。目前,研究者基于来自开发人员自己的代码行的栈追踪来应用一种简单的启发法,因为最近调用的行是最可疑的。在未来,作者还有兴趣使用可以对给定栈追踪的方法进行重新排序的编码器 transformer 来改进启发法。
如下图所示,利用了经过广泛预训练的 transformer,研究者使用了用于微调 PyMT5 的相同的 DeepDev-py 序列到序列模型。他们首先使用 commit 数据来训练基线 bug 修补程序模型和 bug 创建模型。Bug 创建(bug-creator)模型向 DeepDebug(反向翻译)提供的数据量是原来的 20 倍。最后,研究者针对具有可执行测试并产生追踪的函数中的神经错误微调了此模型,从而获得其最终的 DeepDebug(追踪)。
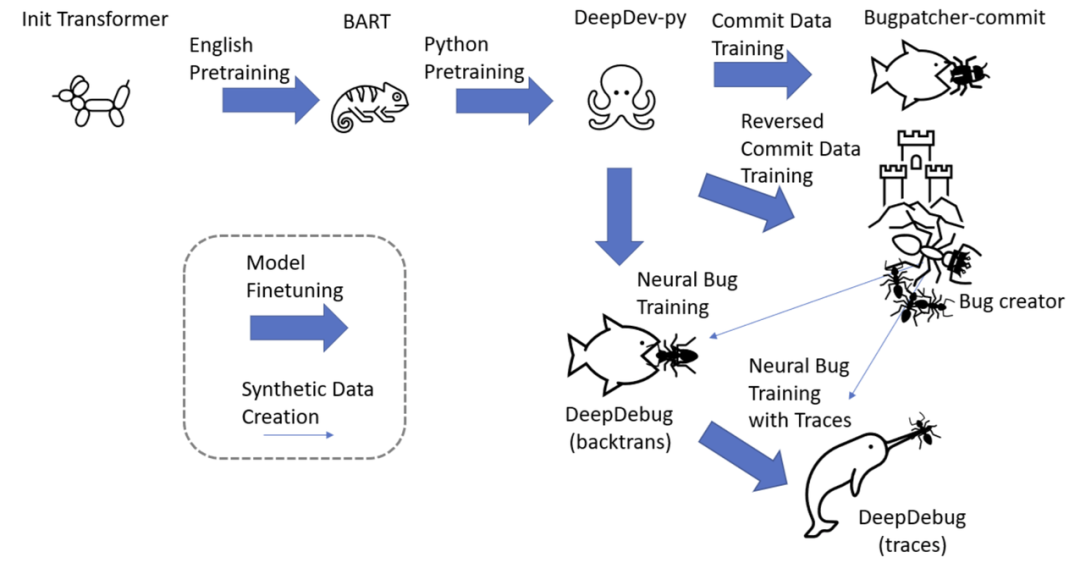
训练pipeline。
模型
研究者重复使用了具有 12 个编码器层和 12 个解码器层的 4.06 亿参数的序列到序列 transformer。在实验栈追踪时,他们为代码框架分配了 1024 个 token,为追踪分配多达 896 个 token,并且为了适应这个规模更大的上下文,还需要扩展 transformer 的位置嵌入矩阵。为此,研究者受 reformer 的启发使用了轴向嵌入,复制了已有 1024 个位置嵌入中的前 896 个,生成一个随机的轴向向量,并将该向量添加到所有 896 个重复嵌入中。在初步实验中,此方法的性能优于随机初始化的嵌入。
数据
研究者使用四个不同的训练数据集:
用于预训练的原始 python 代码;
用于训练神经 bug 创建和 bug 修补程序的 commit 数据;
从原始代码中提取的方法,其中插入了神经 bug 以训练更强大的 bug 修补程序;
通过可执行测试的方法。
对于最后一个数据集,研究者还获得了每个测试执行的行列表,并通过再次插入合成 bug 并重新运行通过测试来获得另一个 bug 补丁程序数据集,使得他们可以在栈追踪、错误消息、打印语句上对 bug 补丁程序进行微调。研究者还实验了为 bug 修补程序模型提供焦点 buggy 方法或整个文件的「骨架」(skeleton),以优先考虑数据(例如函数签名)的优先级。
预训练
在 DeepDev transformer 平台上,研究者重用了 FaceBook 的 BART 模型热启动的 4.06 亿参数的 DeepDev Python transformer,然后使用 Spanmasking objective 对其进行了预训练。预训练数据由 20 万个五星公共 Python 库组成,在 DGX-2 盒子上进行了为期三周的预训练。DeepDev 的 token 生成器附加了空白 token,例如四空间和八空间 token,提高了吞吐量和有效上下文长度。为了最大程度地减少泄漏的风险,研究者始终将验证和测试库限制在同一范围内,尤其是 CodeSearchNet 中使用的库。
commit 的数据
研究者遍历了 10 万个被过滤为至少 10 星 Python 库的 commit 历史记录,并进一步过滤所有消息中包含「修复」一词的 commit,大约占所有 commit 的五分之一。基于对示例的检查,研究者发现了这个简单过滤器的精确度似乎与使用「补丁 bug」或「修复错误」之类语句的限制性过滤器差不多。但是,数据仍然非常嘈杂。
commit 的数据使研究者做到了以下两点:首先,允许他们训练一个偏向于建设性的、bug 修复的编辑模型,让研究人员可以直接在 bug 修复中评估这种模型,或者在过滤更进一层的 bug 数据上对其进行微调。其次,研究者可以反转输入和输出,并训练偏向于破坏性的、引发 bug 的编辑模型。研究人员可以使用此模型来创建神经 bug,以大幅度增强训练数据。这种反向翻译方法已经在 NLP 中被证明是有用的。
合成 bug
由于研究者对通过合成 bug 进行数据扩充感兴趣,所以使用了 GitHub 上的大量无 bug 代码。与仅使用从 bug 修复提交中提取的函数相比,这样做有可能使目标方法的数据集扩展二十倍。此外,研究者通过为每种方法创建多个 buggy 版本来任意地扩大规模。在本篇论文中,他们将规模限制为来自 1 万个库中的 130 万个函数(与提交数据几乎相等),并通过反向翻译扩展到了 1800 万个 bug 修复。
研究者观察到了模型注入了以下几类错误:
将点访问器替换为方括号访问器;
将截断链接的函数调用;
删除返回行;
将返回值封装在元组和字典等对象中然后忘记封装对象;
将 IndexError 等精确错误替换为 ValueError 等不同的错误;
误命名变量诸如 self.result 而不是 self._result;
错误地按引用复制而不是按值复制。研究者几乎应用了以前文献中已报道的所有启发式 bug。
「启发式 bug」一词被用来指代使用简单规则手动创建的合成 bug,例如在函数调用中删除一行或交换两个参数、替换二进制运算符(使用!= 代替 ==)、使用错误变量、忘记『self.』访问器或者删除代码。

「神经 bug」一词被用来指代使用神经编辑模型创建的合成 bug,例如训练来还原 bug 修复提交的 bug。使用神经 bug 进行数据增强具有许多吸引人的功能。灵活的神经模型几乎可以任意生成从开发人员实际犯错的分布中得出的编辑。例如,神经编辑模型可以将 get_key 与 get_value 交换,而简单的启发法可能会进行随机交换,比如从 get_key 切换到 reverse_list。而且,这种方法几乎与语言无关,因为研究者可以重用框架来进行挖掘提交,并且只需要一个解析器就可以提取类和方法,以及组成代码框架所需的部分。
上表所示是在测试集用于训练两个 transformer 的交叉熵损失,一个用于提交数据,另一个用于反向提交。在有和没有代码框架的情况下,在向前和向后编辑中对这两个模型进行评估。由于编辑任务相对容易,因此交叉熵损失比通常报告的生成 Python 代码的效果提升五倍。此外,反向编辑的损失比正向编辑的损失低三分之一。正向模型在正向编辑时比反向模型好 6%,反向模型在反向编辑时反过来又好 6%。与仅使用聚焦方法相比,使用框架的两种模型的性能都高出 2%。

如上图所示,bug 创建模型将 kwargs.pop 替换为了 kwargs.get、将. startwith(self.name) 替换为了 ==self.name、并删除了 break。
可执行测试的方法
实际上,有很多机会可以调试可以实际执行的代码,尤其是在有附带测试验证执行正确的情况下。典型的调试会话包括在栈追踪的帮助下查找可疑的代码块、在近似二进制搜索中插入打印语句和断点、修改并执行代码片段、在 StackOverflow 中搜索错误消息的解释以及 API 使用示例。相比之下,基线神经模型是机会更少的,在每次写入一个 token 之前,只能盯着一段代码几秒钟。
而由可执行测试启用的「生成并验证」方法可以有多次机会提高性能。例如,在短 Java 方法领域,研究者见证了 top-20 精度是 top-1 精度的三倍。尽管先前的工作已经表明这些编辑可能会过拟合,真正的随机编辑仍能确保足够多的尝试次数以通过测试组。
研究者主要运用的方法有三种:
追踪法:除了使用测试对不正确的编辑进行分类之外,还以三种不同的方式将来自测试的信息整合到训练中:将错误消息附加到 buggy 方法中,另外附加了栈追踪,并进一步使用测试框架 Pytest 提供了故障处的所有局部变量值;
收集通过测试法:为了以训练规模收集可执行的测试,从用于预训练的 20 万个库开始,过滤到包含测试和 setup.py 或 requirements.txt 文件的 3.5 万个库。对于这些库中的每一个,都在唯一的容器中执行 Pytest,最终从 1 万个库中收集通过的测试;
合成 bug 测试法:在过滤通过可执行测试的函数并插入神经 bug 之后,重新运行测试以收集 Pytest 追踪,并滤除仍通过测试并因此实际上不是 buggy 的已编辑函数。
实验及结果
研究者对训练反向翻译数据、添加框架以及添加 Pytest 栈追踪进行了实验,并得到了如下结果。
反向翻译数据
在首个实验中,研究者比较了通过前向提交数据进行的训练与通过反向翻译产生的合成 bug 进行的训练,并对保留数据上使用交叉熵进行评估。如下表所示,比起前向提交数据,DeepDebug(反向翻译)的损失降低了 10%。令人惊讶的是,反向翻译模型实际上在反向提交数据上的表现较差。

总体而言,DeepDebug 比以前的技术要强大得多。QuixBugs 挑战是带有小合成 bug 且 Python 和 Java 版本几乎相同的 40 个经典算法的基准,最初的 QuixBugs 挑战是让开发人员在一分钟的时间内修复尽可能多的 bug。下表报告了模型挑战 QuixBugs 的结果。

研究者将模型限制为通过随机采样生成 100 个补丁,这大约是在一分钟跨度内可以生成和评估的数量。随后将现有的 bug 数量提高了 50%以上,同时将误报率从 35%降低到了 5%。值得注意的是,由于此任务的复杂性较低,因此所有的模型都会生成许多重复的编辑,这表明在采样上仍有改进空间。鉴于先前模型的超时以及额外信息提供,这些结果更加令人印象深刻。例如,CoCoNuT 被明确告知哪一行包含该 bug,并被允许六个小时来找到补丁;五个非神经工具找到了 122 个补丁程序,用于最长的递增子序列算法,还进行了数千次的尝试。
添加框架
在第二个实验中,研究者比较了仅使用焦点函数作为输入以及使用整个框架作为输入的训练和评估。如下表所示,当对神经 bug 进行评估时,使用框架时,神经 bug 补丁损失减少了 25%。而实际上,当对提交数据使用框架时,神经 bug 补丁的表现更差,因为提交通常会编辑多个函数。

Pytest栈追踪
在第三个实验中,研究者将 Pytest 栈追踪附加到 buggy 输入中,使用轴向嵌入来扩展上下文窗口,以适应其他的 token。在计划进行开源的验证集中筛选了 100 个库中的 523 个神经 bug 的基准。他们观察到了令人印象深刻的表现,与交叉熵结果相反,使用追踪大大提高了性能。如下表所示,DeepDebug(反向翻译)的前 10 个修补程序成功率为 90%,而 DeepDebug(追踪)的前 10 个修补程序成功率为 97%。








![[图]苹果TikTok账号更新:邀请Olivia Rodrigo宣传iPad和Apple Pencil](http://f.sinaimg.cn/spider20210811/89/w320h569/20210811/af7f-59115dcc4f7cfb1dba5b924fcd835cdb.gif)