因为上一代用骁龙 765G 的骚操作,在大家心目当中,Google Pixel 系列算是断更一代。而 Pixel 6 系列就不同了,有 Google 自研 SoC——Google Tensor(Tensor 是张量的意思,名字就很 AI,很 ML)、追上时代的相机硬件,也有相对厚道的价格。

重回旗舰市场的计算摄影大佬,终于肯用现代的 CMOS 了!机圈立即奔走相告,直到国外用户拿到真机,Anandtech 放出 Google Tensor 的测试成绩和分析……
在不改变 Anandtech 原意的情况下,我们对这颗如此重要和有趣的 SoC 的内容进行整理和编译,原文 https://www.anandtech.com/print/17032/tensor-soc-performance-efficiency
全自研还是魔改(半定制)?
Google 表示 Google Tensor 是迈向新型工作负载探索之旅的起点,现有芯片方案无法实现他们说的目标。凭借多年来的机器学习研究经验,Google 把 Tensor 做成一款以机器学习作为差异化的 SoC,据说其让 Pixel 能实现很多独特的新功能。
关于 Google Tensor 的第一个争议是,它是全自研?还是魔改(半定制)?这里主要看你对“自研”的定义,Google 和三星看似密切的合作,模糊了传统的自研和半定制之间的界限。
在 Google 内部,Google Tensor 代号是 GS101,可能是 Google SoC 或 Google Silicon 的意思。而之前爆料说的 Whitechapel(白教堂),还没有任何证据表明其是真实存在的芯片。
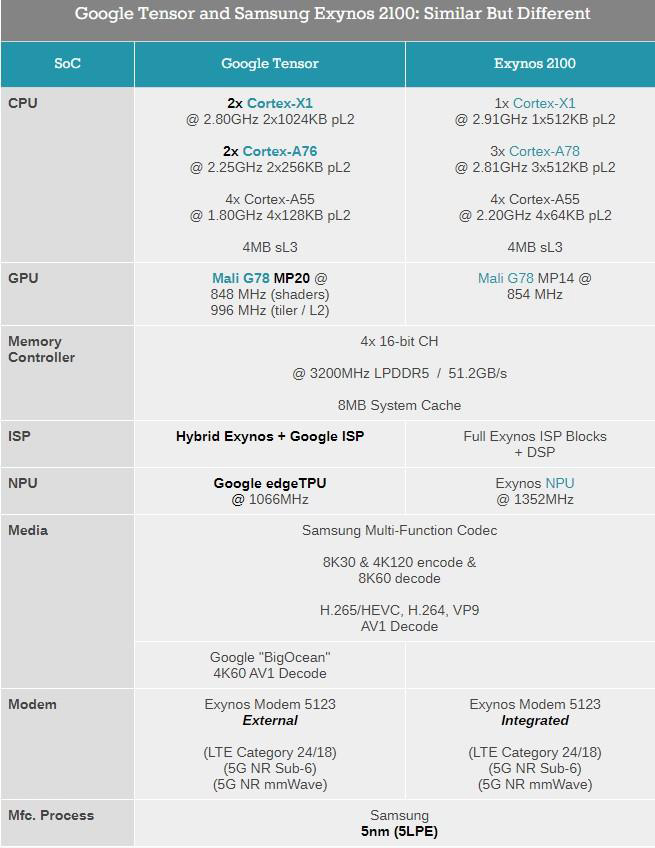
而 Google Tensor 基本遵循三星 Exynos 的命名规则,其 ID 是“0x09845000”,拆解后能看到丝印是 S5P9845(编者:原文发布之初,认为 ID 对应 S5E9845,但经 TechInsights 拆解,确认是 S5P9845)。作为参考,三星 Exynos 2100 的 ID 是 S5E9840,Exynos 1080 是 S5E9815。
几年前就有报道说三星开始提供半定制的芯片服务,当时就有三星与思科、Google 的合作消息。ETNews 在 2020 年 8 月的文章中提到,三星会根据客户需求提供“定制”技术和功能,甚至从芯片设计阶段就开始提供。
三星不再是简单的芯片制造商,而是完全参与芯片设计,这都可以和 ASIC 设计服务相提并论了。但这是个很特殊的情况,毕竟三星不但有台积电那样的芯片代工业务,它也有自己的自研 SoC。
Google Tensor 和三星 Exynos 高度同源,除了大家常说的 CPU、GPU、NPU 等高级结构外,芯片中的基本结构很多都是同源的。虽然纸面上,三星、联发科、海思,甚至高通(只有 CPU 方面),用的都是 arm 的 Cortex CPU 和 Mali GPU 公版架构,但它们的底层架构还是非常不同的。
Google Tensor 使用的是三星 Exynos 的框架,不但有相同的时钟和电源管理架构,它们的存储控制器、外部接口的 PHY IP 等高级块,甚至连 ISP 和媒体编解码器等较大的 IP 功能块都很相似。有趣的是,Github 上已经有 GS101 的公开信息,可以 1:1 地比较它和 Exynos 的结构组成。
不过,虽然用了 Exynos 的基础模块和框架,但 SoC 的定义确实由 Google 控制,结构和 IP 块之间的连接设计上,Google Tensor 和三星 Exynos 都是不同的。
例如 Exynos 上,CPU 是用总线连起来的,而 Google Tensor 的 CPU 集群是被集成在一个更大的 CCI 里面。从外部看,可能是用了不同的总线设计,也可能是完全不同的 IP。另外,像内存控制器的连接方式,它们也是不太一样的。
性能规格分析
单看 CPU 就知道 Google Tensor 的特殊之处,2x X1 + 2x A76 + 4x A55,这个“2+2+4”结构在三星 Exynos 9820 和 Exynos 990 都出现过。但当今 Android 旗舰 SoC 中,1+3+4 才是绝对的主流。而且敢堆 2 颗 X1 的,仅 Google 一家。

理论上有两颗 X1 超大核,其 CPU 多核性能会比单颗 X1 的产品更强。而频率上,Google Tensor 的 X1 都是 2.8GHz,略低于骁龙 888 的 2.84GHz 和 Exynos 2100 的 2.91Hhz。此外,Google 还和骁龙 888 一样给了 1MB L2 缓存,比 Exynos 2100 的 512KB 残血 X1 更猛。
大核(编者:你喜欢叫中核也行)这边,Google 选择了古老的 A76 架构,这是件很有争议性的事(2.25GHz,256KB 的 L2 缓存)。毕竟这并不合理,因为 A77 和 A78 的性能和能效比都更高。连 Anandtech 都没从 Google 那里得到明确的解释。
他们猜测可能是几年前设计芯片的时候,三星手上也没有更新的 IP 供 Google 选择。也可能是在超大核换成 X1 的时候,没有时间连大核也一起换了。但 Google 应该不是特意选用 A76 的,因为从下面的测试可以发现,A76 真的是跟不上时代了。
小核这边,4 个 1.8GHz 的 A55。Google 选择了 128KB 的 L2 缓存,而不是三星 Exynos 自己用的 64KB,这让这个 CPU 更像骁龙 888 了。但比较奇怪的是,Google 把集群的 L3 缓存频率和 A55 绑定,这会导致延迟和功耗问题。另外,这也和 Exynos 2100 的 L3 频率是不同的。
Google Tensor 的 GPU 是 Mali- G78 MP20,规模仅次于麒麟 9000 的 G78 MP24(编者:G78 的极限)。大家最开始以为 Google 会用低点的频率来提升能效比。但结果 Google 竟然把着色器频率推到 845MHz,把 tiler 和 L2 频率推到 996MHz,简直癫狂。另外,它也是第一个用上 G78 分离频率特性的产品。
作为参考,Exynos 2100 的 G78 MP14 也“只是”854MHz,后者的峰值功耗已经很高了。结果 Google 增加 42% 的核心,却依然维持高频。因此它的峰值性能很让人期待,但峰值功耗也会很猛。而内存控制器似乎和 Exynos 2100 相同,支持 4x16bit 的 LPDDR5,理论带宽 51.2 GB/s。
它也用了 8MB 的系统缓存,但还不清楚是否用了和三星 Exynos 2100 一样的 IP,因为它们的架构和行为方式都不太一样。Google 大量使用 SLC 来提升 SoC 性能(包括他们自己的定制模块)。这个 SLC 允许自分区,将 SRAM 专门分给 SoC 上特定的 IP 块,使它们在不同用例下,能对全部或部分缓存进行独占访问。
ISP 与 TPU
大家说 SoC 集成的 ISP 时,经常把它们描述为单个 IP。但实际上,ISP 是不同的专业 IP 块的组合,每个 IP 块处理成像管线中的不同任务。而 Google Tensor 非常有趣,因为它将三星用在 Exynos 芯片上的一些片段整合到了一起,同时还将自己开发的定制模块整合到了流水线中 —— 正如 Google 在展示 SoC 时所说的那样。
成像系统部分和 Exynos 是一样的,如相位检测处理单元、反差对焦处理单元、图像缩放器、畸变校正处理块和纹理遮挡函数处理块等。比 Exynos 少的部分,可能是三星的一些图像后处理模块。
谷歌在 ISP 中加入自己的 3AA 模块(自动曝光,自动白平衡,自动对焦) ,以及一对自己的时域降噪 IP 模块(用于对齐和合并图像)。这些很可能就是谷歌所说的那些有助于加速图像处理的模块,这些是 Pixel 系列计算摄影的一部分,毋容置疑地地代表了图像处理流水线中非常重要的部分。

TPU 是让 Google Tensor 被称为 Tensor 的地方。Google 已经用自研 TPU 好几年了,在驱动层面,Google 把 Tensor 的 TPU 称作 Edge TPU( 端侧边缘 TPU)。这是相当有趣的信号,因为它应该和 Google 2018 年发布的 Edge TPU 有关,后者是 Google 为边缘推理而设计的 ASIC 芯片(官网 cloud.google.com/edge-tpu)。
当年的 Edge TPU 宣称在 2W 功耗下可以提供 4TOPS 的算力,但 Google 并未公布 Tensor 的 TPU 性能指标,但是在一些测试中可以看到它的最大功率是 5W 左右。因此如果它们确实是有关联的,考虑到这几年的制程和 IP 上的进步,Google Tensor 的 TPU 性能应该有明显提升了。
这个 TPU 是谷歌芯片团队的骄傲,它正在使用最新的机器学习处理架构,这个架构针对 Google 内部运行机器学习的方式进行过优化,并且表示它可以允许开发新的、独特的用例,这是 Google 做定制 SoC 的主要目标和出发点之一。在后面的测试中,这个 TPU 的性能指标确实也是令人印象深刻的。因为 TPU 的信息不多,我们只能基于它的驱动程序做简单猜测,它可能包含四核心的 Cortex-A32 CPU。
其他模块
在媒体编码器方面,Google Tensor 使用了三星的多功能编解码器(与 Exynos 系列同款),还有一个看起来像是用于 AV1 解码的自研 IP 块。这有点奇怪,因为三星的宣传中,Exynos 2100 是有 AV1 解码功能的,而且这个功能貌似也在内核驱动程序里面。但在 Galaxy S21 系列中,这个 AV1 解码功能从未在 Android 的层面实现过。
谷歌加入的这个专用的 AV1 解码器被他们称做“BigOcean”,它能让 Android 系统具备 AV1 硬解能力。但非常奇怪的是,它真的就只负责 AV1,其他格式编解码还是由三星的 MFC 负责。
Google Tensor 的音频子系统也不同,Google 用自己设计的 IP 块代替了三星的低功耗音频解码子系统,它们可以在无需全部唤醒 SoC 的情况下进行低功耗的音频播放。我们认为这部分也是当协处理器用的,这也是 Google Tensor 和 Exynos 不同的地方。
Google 还用了一种称为 Emerald Hill 的硬件内存压缩器,对内存页面进行 LZ77 压缩加速,反过来也可以用来加速交换中的 ZRAM 的卸载过程。现在还不确定 Pixel 系列是否已经启用这个模块,但能确认在“/sys/block/zram0/comp_algorithm”目录中有“lz77eh”。作为课外资料,三星早在 5 年前,就在 SoC 里集成了类似的硬件压缩 IP 模块。但出于某些原因,这些模块从未被启用过,也许是能效比并没有他们预想中的高。
 图源 PBKreviews
图源 PBKreviews另外,Google 还用三星的 Exynos 基带,做出了第一台非高通的毫米波手机。Pixel 6 系列用的是三星的 Exynos 5123 基带(译者:为遵循国内的习惯,这里把调制解调器称为基带)。三星在 2019 年就提到自己的毫米波射频和天线模块,说 2020 年会出现在量产机上(不知道当时是否计划让 Pixel 6 在 2020 年上市)。Pixel 6 系列的峰值速度可以达到 3200Mbps,但很多测试中,它的网速只有高通产品的一半左右。
虽然是同一个基带,但它不是像 Exynos 2100 那样集成在 SoC 里,而是外挂的。可能是因为 Google Tensor 的 GPU 和 CPU 规模太大了,而且 TPU 的规模也是未知数。毕竟就算是把基带外挂出去,Google Tensor 的规模也是相当大了,即便是和对比 Exynos 2100 的情况下。
总的来看,Google 确实设计和定义了 Tensor ,同时有很多 Google 特有的设计,是整体的芯片上的差异化。但从更底层的角度看,Tensor 和 Exynos 有很多共通之处,用了很多三星特有的基础模块,因此叫它“半定制”或许会更合适。
实际性能表现:不尽如人意

测试中,Google Tensor 的 DRAM 延迟较高,还不如 Exynos 2100,和骁龙 888 比就更差了。Google 改过了内存控制器,它会根据负载和内核的内存失速百分比来控制 MC 和 DRAM 速度,这部分是和三星不同的,其实际利用率也不如三星的内存控制器高。现在不知道是 CPU 的问题,还是整个 SoC 内部的问题,但这确切地影响了下面的测试。
它的 L3 延迟也相当高,比 Exynos 2100 和骁龙 888 高得多。Google 没有给 DSU 和 CPU L3 缓存设定特定的频率,而是把它和 A55 小核的频率关联。奇怪的是,即便 X1 或 A76 满载,A55 和 L3 却在低频“摸鱼”。同样情况下 Exynos 2100 和骁龙 888 都是会提高 L3 频率的。
在系统缓存测试中,能看到 11-13MB 的延迟情况 (1 MB L2 + 4 MB L3 + 8 MB SLC) ,在正常的内存访问中,Tensor 也是比 Exynos 要慢的,可能和被改过的个别缓存管线有关。
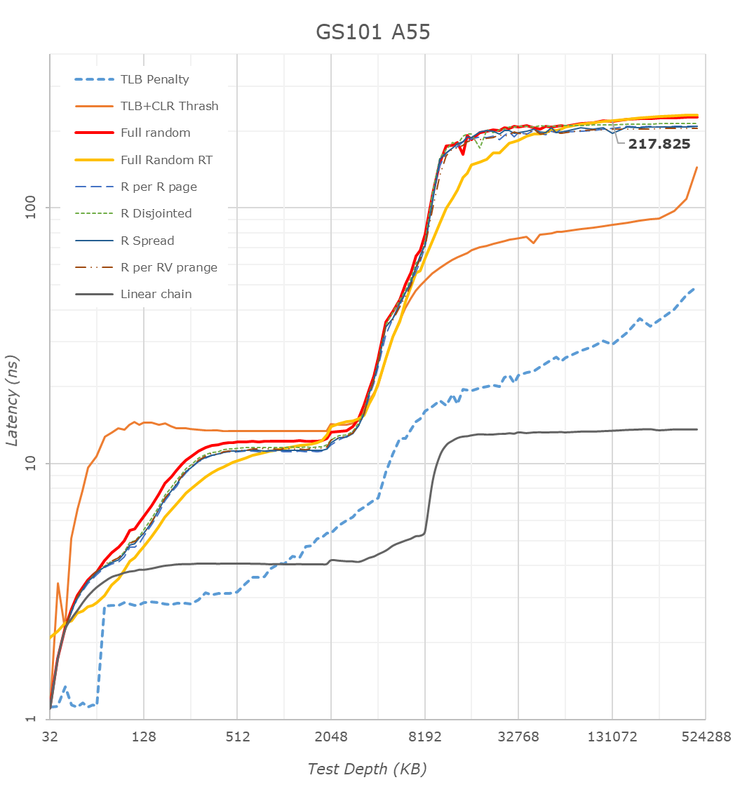
因为 L3 和 A55 的频率捆绑,且频率高,所以 Google Tensor 的 A55 小核是几个 SoC 里 L3 延迟最低的,彷如没有异步时钟桥一般。
CPU 部分,Google Tensor 更像是骁龙 888,而不是 Exynos 2100。虽然 Google Tensor 的 L2 缓存是 Exynos 2100 的 2 倍,但频率低了 3.7%(110MhHz)。
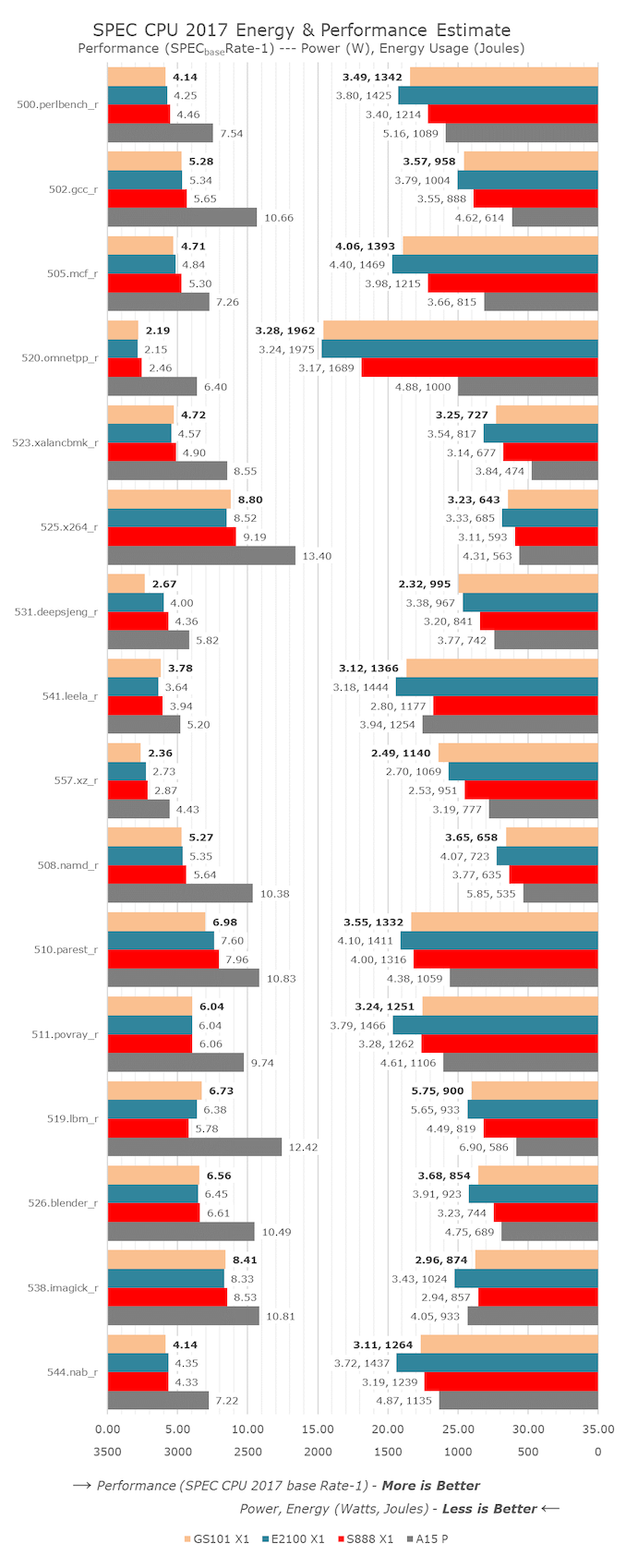
Tensor 的弱点是内存延迟,导致 SPEC 测试中很多子项目都比 骁龙 888 和 Exynos 2100 慢,但能耗却更高(CPU 在干等内存)。SPEC 总分上,Tensor 的表现比 Exynos 2100 略差,对比骁龙 888 的落后幅度达到 12.2% ,由于跑完测试的时间更长,最终耗电还多了 13.8% 。折算回来,相对骁龙 888 的差距应该是 1.4% 左右。
它也有和 Exynos 2100 一样的降频问题,只是相对没有那么严重。如果冷却得当,性能会高 5%-9% 左右(上图的测试结果是在 11 度的环境下得到的)。
可怜的 A76 大核,骁龙 888 的 A78 比它强 46%,还更省电,实际 IPC 差距在 34%,这倒符合两个构架之间的差距。如果真是为了省电,完全可以做个低频的 A78,但结果 Google 放了两颗频率又高、又耗电、性能还不行的 A76,只能推断 Google 是没得选,而不是有意而为之。
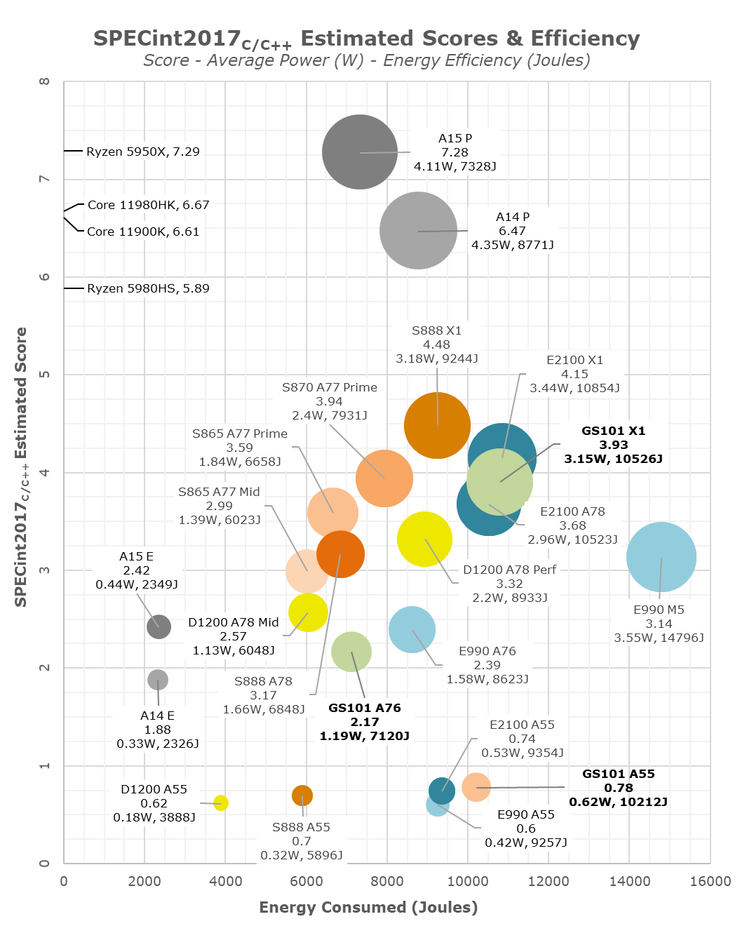
越接近右下角,能效比越低;越接近左上角,能效比越高 ↑
A55 小核这边也不行,性能只是比同频的骁龙 888 的 A55 高 11%(感谢 L3 和 SLC),但却几乎是 2 倍的功耗,俨然就是继承了 Exynos 高功耗 A55 的血统,能效比甚至比自己的 A76 大核还拉胯。看看联发科天玑 1200 的 A55,再看看 A14 的能效核心,这真是个残酷的世界。
Google Tensor 因为拉胯的 A76 性能表现,就算有 2 颗 X2 都无力回天,拖低了整体分数。X1 本身也比对手稍慢一些,大部分时间的能效比都和 Exynos 2100 的 X1 一致。但 A76 实在落后时代太多了(无论是性能还是能效比),而 A55 又继承三星低能效的传统,一言难尽就是了。
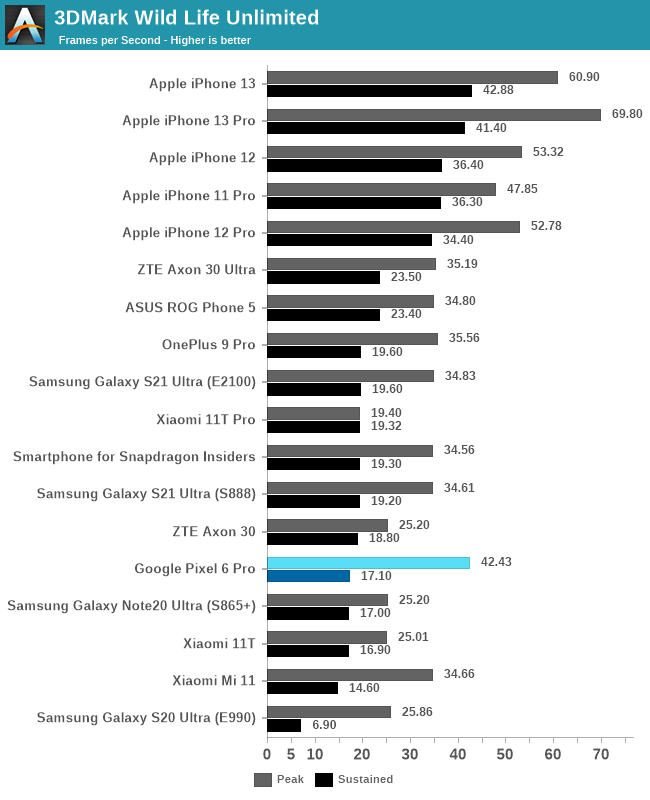

GPU 这边规模大,频率高,但 3DMark Wild Life 测试的峰值性能只比 Exynos 2100 高 21%。在 GFX Bench 的 Aztec 场景测试中,领先 Exynos 2100 14%,小幅领先骁龙 888。虽然采用了分频设计,但貌似瓶颈在 GPU 的其他地方。
Tensor 的 GPU 峰值功率高达 9-10W,手机一跑就降频(一轮测试都没跑完啊……),拖低了整体功耗,所以才会有 7.28 W 的平均功耗。Pixel 6 系列没有热管,散热配置和机身结构更像是 iPhone,而不是猛堆散热的安卓旗舰。它跑起来时,左侧的 SoC 45 度,但右侧只有 30-33 度,散热确实是弱。
让人不解的是,今年这批 SoC 都设定了高得不切实际的 GPU 频率,一跑就降频。可能是为了应对突发的 GPU 负载?或者是其他什么原因?但无论怎么样,实际能效比是受累了。
TPU:极强的推理性能
这是 Google Tensor 挽回颜面的地方。MLPerf 测试中,Pixel 是在 NNAPI 跑的,其他厂商是各自的库,高通是 SNPE(最近优化了 MLPerf 1.1,提升了成绩)、三星是 EDEN,联发科是 Neuron,而苹果没有 coreML 加速,所以吃亏。

在图像分类、目标检测和图像分割工作负载中,Tensor 成绩低于高通,但强于三星。而在语言处理(MobileBERT 模型),Google Tensor 提供了骁龙 888 3 倍的性能,推理部分强得很。Google 在宣传里,确实也提到过实时转录、翻译等使用场景是其差异化所在。
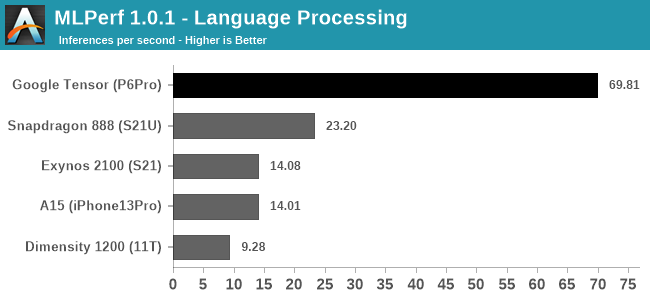
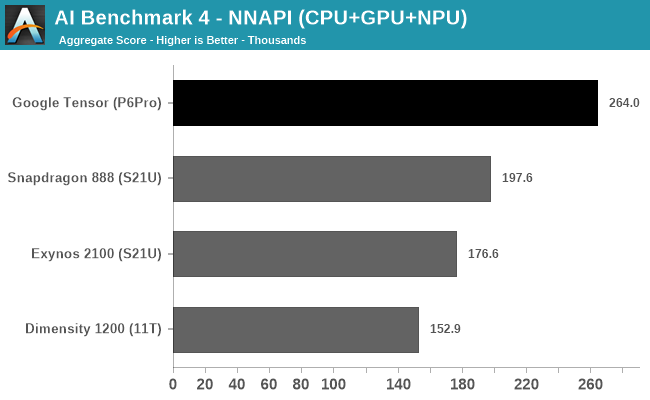

还没发布的 GeekBench ML 测试,用是 TensorFlow 模型,代表的是 GPU 的机器学习性能。这时候 Google Tensor 就弱于 Exynos 2100。如果用 NNAPI 模型,此时是 CPU+GPU+NPU 的混合工作,Google Tensor 就可以大幅领先骁龙 888。
除了绝对性能,跑 AI 测试时,Pixel 6 Pro 的整机功耗和 Exynos 2100 的 Galaxy S21 Ultra 接近。单独进行推理任务时,Exynos 2100 的爆发功率达到 14W,骁龙 888 也有 12W。但因为 Google Tensor 的 AI 性能更高,所以最终能效比要更高一些。
不过 Google 还没有计划推出相关的 SDK 让开发者去更好地利用这颗强大的 TPU 。但再看看三星,它的 NPU 发布都 2 年了,现在都没有 SDK…… 现在 TPU 的强大性能,主要集中体现在官方 App 里,像是给摄像头加入更多的机器学习功能,以及各种翻译功能。
总结

Google 表示,他们搞自研 SoC 的主要原因是现有的 SoC 在机器学习上的性能和能效比太低。而 Tensor 的机器学习性能和能效,被用来支撑新的用例和体验,例如我们在 Pixel 6 系列上看到的很多机器学习特性。像是实时转录、实时翻译和图像处理等算法,所有这些都是运行在 Tensor 的 TPU 上的。
虽然 Google 可能不想承认或者谈论,但 Google Tensor 确实就是和三星合作的产物,大部分都源自 Exynos,并继承了三星在能效比方面的弱点。CPU 被古老的 A76 拖后腿,规模庞大的 GPU 被散热拖后腿,但 TPU 确实表现很好,特别是自然语言处理方面,远远抛离所有竞品。
但总的来说,我们认为 Google 已经通过 Tensor 实现了最初的目标。我们不知道 Google 下一代的 SoC 会走什么样的路线,但我们很有兴趣等等看。