【猎云网北京】6月10日报道
在2022年国际口语机器翻译评测比赛(简称IWSLT)中,思必驰-上海交大联合团队(AISP-SJTU)凭借卓越的技术优势,获得“英-中同声传译”(Speech-to-Text)赛道冠军。

2022年第十九届国际口语机器翻译大会(International Conference on Spoken Language Translation ,简称 IWSLT)在爱尔兰都柏林落幕。IWSLT是国际上最具影响力的口语机器翻译评测比赛之一,今年设置了同声传译、离线语音翻译等7个任务。思必驰-上海交大联合团队(AISP-SJTU)本次参加英-中同声传译任务,以优异的成绩获得Speech-to-Text赛道第一名。

论文标题:The AISP-SJTU Simultaneous Translation System for IWSLT 2022
论文链接:https://aclanthology.org/2022.iwslt-1.16.pdf
任务和背景
同声传译是仅在部分语音或文本输入的情况下,逐步生成翻译结果的任务。同声传译包含两个子任务:
1)Text-to-Text,将流式语音识别(ASR)系统的输出文本实时从英语翻译成中文普通话;
2)Speech-to-Text:将英文语音实时翻译成中文普通话文本。
目前同声传译任务主要有两种技术路线:
1)级联技术。即整个系统由ASR系统和翻译(MT)系统组成,输入源语言音频信号,先经过ASR系统转写成源文本,再经过MT系统翻译为目标语言。
2)端到端技术。即系统直接将源语言音频翻译为目标语言文本,不生成中间字符。相对于级联系统上亿的数据规模,端到端系统的训练数据极其匮乏,导致其效果远低于级联系统。

级联语音翻译

端到端语音翻译
同声传译的系统通过两种方式进行评估:
1)翻译质量,使用标准BLEU指标评估;
2)翻译延时,使用流式翻译的标准指标进行评估,包括平均比例(AP)、平均滞后(AL)、可微平均滞后(DAL)。
最后,比赛主办方根据不同延时范围的翻译质量对提交的同声传译系统进行排名。对于英-中同声传译系统,延时范围设置为:
1)低延时,AL<=2000毫秒;
2)中延时,AL<=3000毫秒;3)高延时,AL<=4000毫秒。
数据和数据处理
文本数据预处理
比赛方提供大量的双语语料和单语语料,通过规则过滤和匹配模型筛选出优质的文本数据。规则过滤包括:太长的单词,长度严重失衡的中英双语句子,过滤带HTML标签的句子,删除重复等等。另外,训练一个分类模型,过滤语义不匹配的真实双语和伪双语数据。
文本数据扩增
数据增强是提升模型效果行之有效的方案。首先使用真实双语数据训练中-英和英-中离线模型。然后这两个离线模型分别生成中文单语和英文单语的伪双语数据,用于回译和知识蒸馏。最后,让翻译模型在ASR生成的伪双语数据上进行微调,来提升翻译模型的鲁棒性。文本数据统计如下:

MT训练数据
语音数据处理
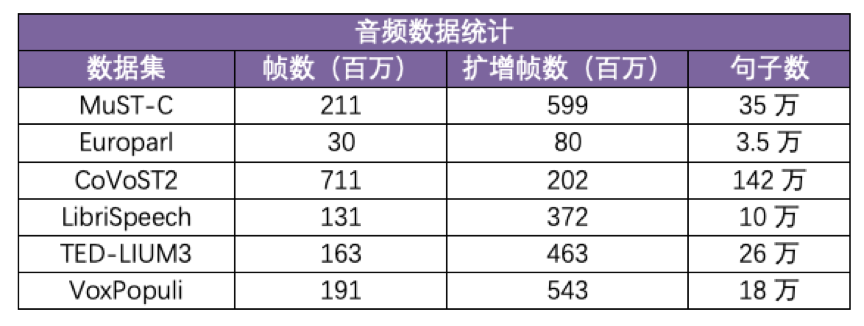
比赛主办方提供了6个英文语音数据集,共3000小时。采用传统的语音特征提取方法FBank,特征维度设置为80,每帧窗口大小25毫秒,窗口滑动步长10毫秒。
语音数据扩增
通过增加音频扰动的方法来获得扩增音频,包括声音大小、速度、基线扰动等。除了CoVoST2这个数据集扩增1/3,其他数据集的音频数据扩增3倍。音频数据统计如下:
ASR训练数据
技术解读
思必驰-上海交大团队首次参加这类语音翻译比赛,在充分总结前人经验的基础上,积极开拓创新,下面对其关键技术进行解读。
技术1:引入预训练语言模型,大幅提升ASR性能
近年来,预训练语言模型(LM),例如BERT,在NLP领域大放异彩,尤其在低资源场景,LM作用更加明显。如何将语言模型引入ASR模型呢?首先看一下ASR的模型结构,如下图:
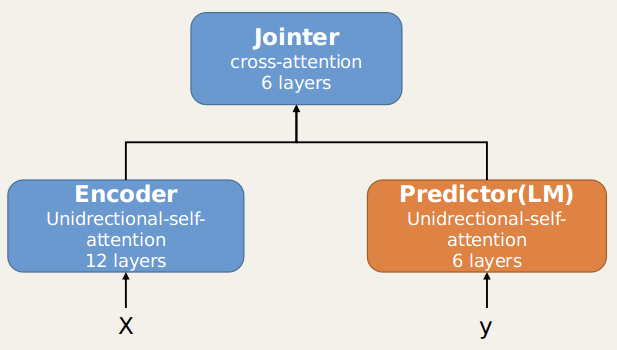
ASR模型和E2E模型结构
ASR模型整体是transformer架构,但是Decoder拆分为Jointer和Predictor,其中,Predictor仅包含6层单向自注意力机制,Jointer仅包含6层交叉注意力机制。预训练语言模型可以替代Predictor,从而ASR的解码端可以充分利用大数据的优势,提升解码能力。与传统的预训练语言模型BERT相比,这里的语言模型需要做两方面的改变:
1)将传统的双向自注意力机制改为单向注意力机制;
2)预测目标改为预测下一个token。用表1中的数据训练分别训练一个中文语言模型和英文语言模型,并分别用于端到端模型(E2E)和ASR模型,实验表明,增加LM后对二者均有大幅提升。
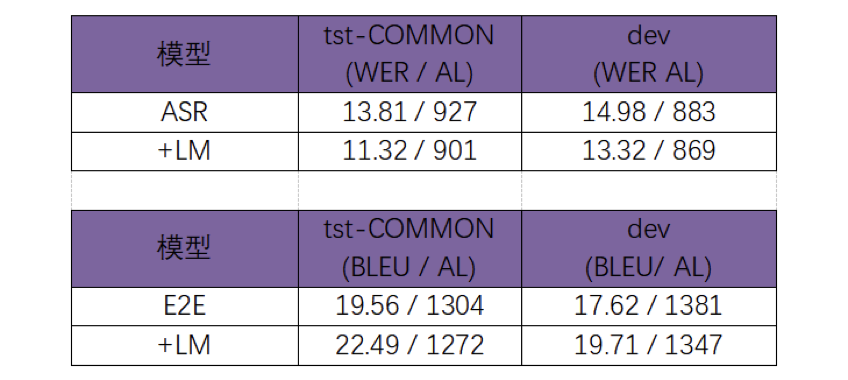
预训练语言模型效果
技术2:无限左看,随机右看
流式翻译模型的编码端一般使用单向注意力机制,进一步地,可以设定一个固定的右看窗口,实现部分双向注意力机制,来提升编码能力,如图4,每个token都可以“看”到所有左侧内容,即无限左看,但只能往右看到2个token。本次比赛在CAAT[1]模型的基础上做了更进一步的改进,提出Dynamic-CAAT,即在训练过程中,将固定的右看窗口设为随机取值,在预测过程中,当有新token输入时,使用双向注意力机制重新计算所有token编码。
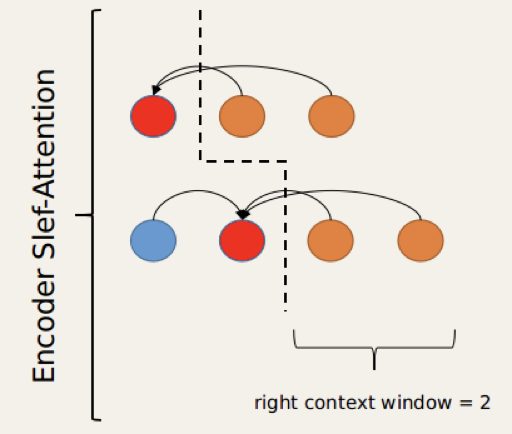
翻译模型编码端注意力机制
实验表明,Dynamic-CAAT在各类延时级别上都有效果。这样整个系统只需要一个翻译模型,而不是训练多个模型来适应不同的延时范围。
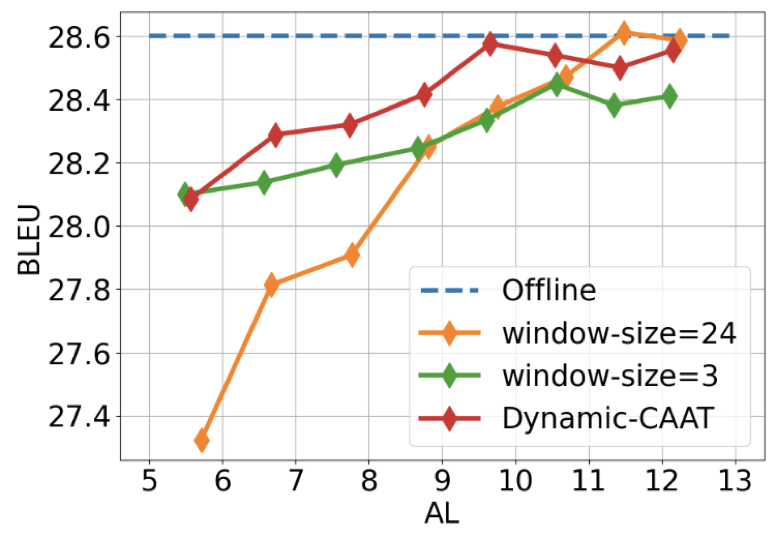
Dynamic-CAAT的效果
评测结果
IWSLT 2022综述文章中[2],主办方给出的英-中评测结果显示思必驰-上海交大团队(AISP-SJTU)提交的系统在低、中、高三个延时范围内,都超过第二名约2BLEU(具体实验数据见综述文章143页)。
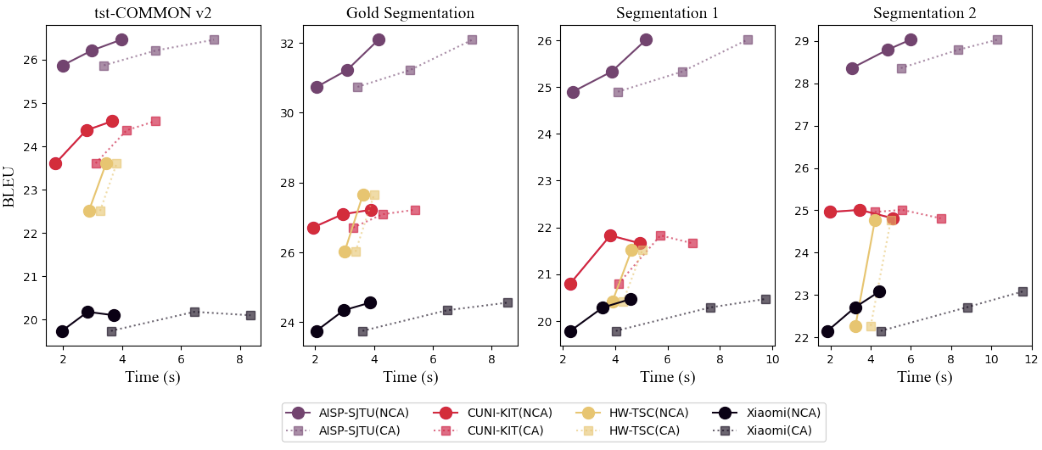
speech-to-text英-中评测结果
总结
本次比赛,结合各种技术手段打造了英-中同声传译最优基线,也对端到端模型做了初步探索。端到端模型在速度和误差传导上比级联模型更占优势,因此,未来我们希望进一步研究有效的数据扩增手段,来提升端到端模型的翻译效果。
引用
[1] Dan liu, Mengge Du, Xiaoxi Li et al., Cross attention augmented transducer networks for simultaneous translation
(https://aclanthology.org/2021.emnlp-main.4.pdf)
[2] Antonios Anastasopoulos et al., FINDINGS OF THE IWSLT 2022 EVALUATION CAMPAIGN
(https://aclanthology.org/2022.iwslt-1.10v2.pdf)