雷峰网(公众号:雷峰网)消息,GPU明星初创公司壁仞科技,选在公司创立即将三年之际正式发布首款通用GPU芯片BR100。BR100采用7nm工艺,集成770亿晶体管,使用Chiplet(芯粒)技术,2.5D CoWos封装技术,芯片面积达到1000平方毫米。
BR 100 通用GPU 16位浮点算力达到1000T以上、8位定点算力达到2000T以上,单芯片峰值算力达到PFLOPS级别,FP32算力超越英伟达在售旗舰GPU一个数量级。
 壁仞科技创始人、董事长、CEO张文
壁仞科技创始人、董事长、CEO张文壁仞科技2019年9月9日注册成立,在成立后的短短18个月,融资额超过47亿元,创下了国内芯片创业公司融资的记录,也成为了业界关注的焦点。
今天的发布会上,壁仞科技创始人、董事长、CEO张文也谈到,大算力芯片创业至少要15亿元起。而且,芯片行业本来就是资金密集、人才密集和资源密集的行业,壁仞科技经过了1065天研发,正式发布的首款GPU,打破了全球通用GPU算力记录,这是该记录第一次由中国企业创造,中国的通用GPU芯片正式迈入“每秒千万亿次计算”新时代。

喊出响亮的口号显然不能回应业界的一些质疑,只有真正强大的产品可以。

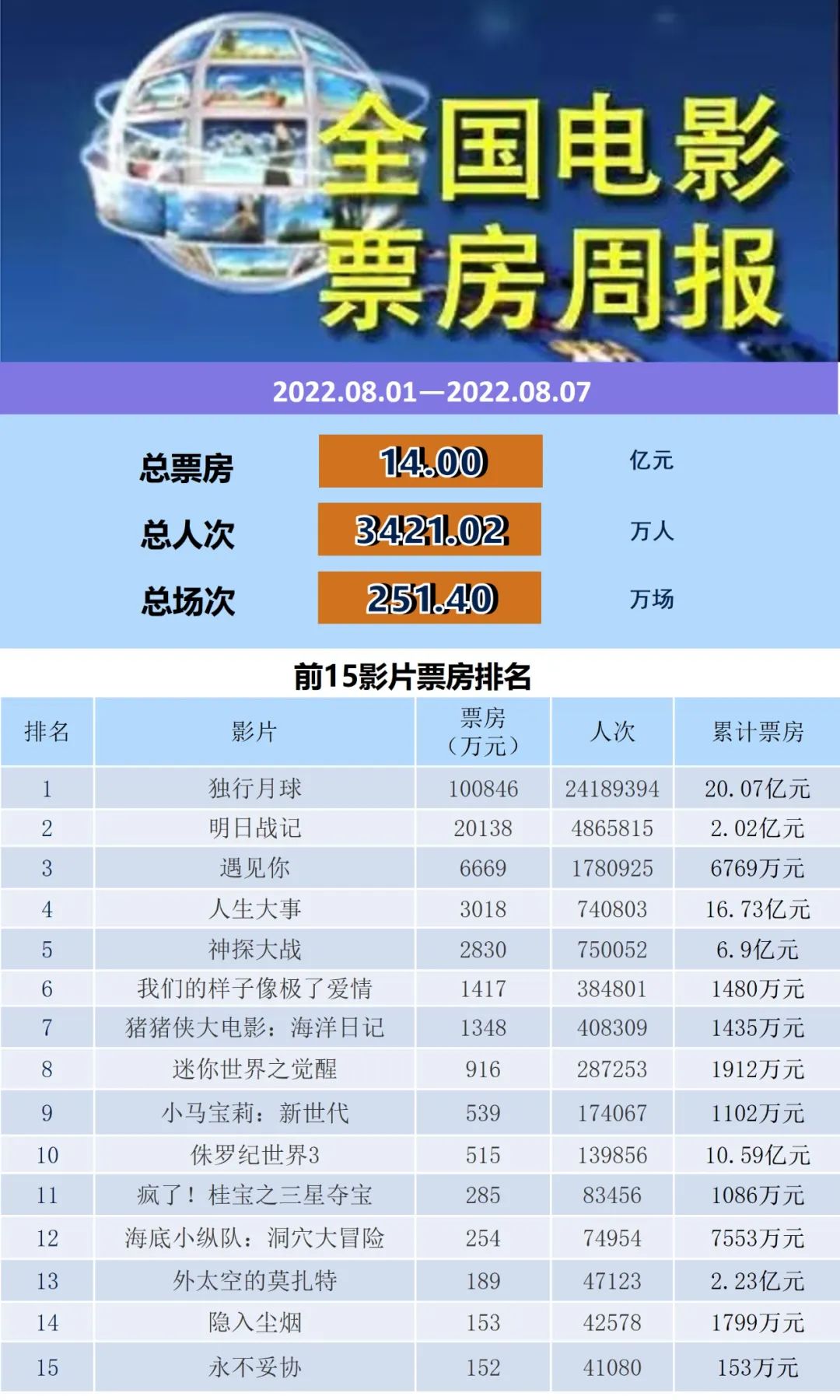
壁仞科技给出的数据显示,其首款旗舰产品BR100对比英伟达在售的旗舰GPU峰值算力在Int8、BF16、TF32/TF32+、FP32数据格式下最少有3.3倍的峰值性能优势,在FP32数据格式下性能优势更是达到了13.1倍。
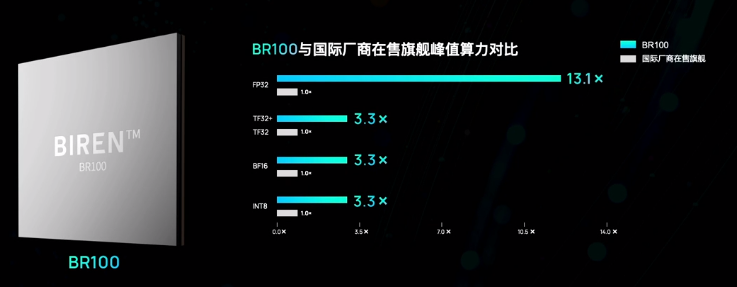
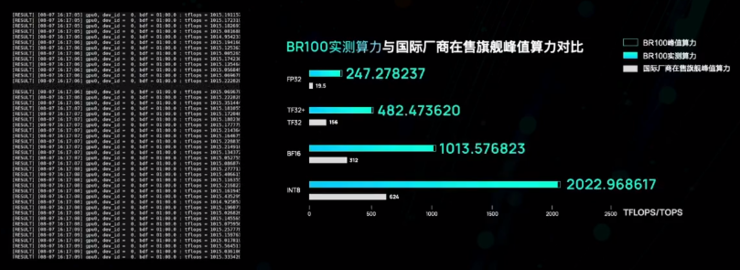
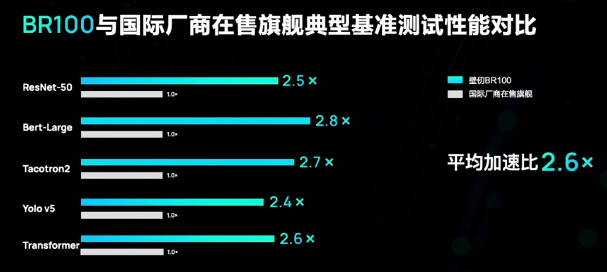
如果与国际厂商最新旗舰峰值算力对比,各种数据格式下也有性能优势。
对于一家初创公司来说,想要超越英伟达最新的H100 GPU,挑战十分巨大,抛开其它因素,仅看一些关键参数,就能看到两者之间的差距,以及想要超越的难度。
英伟达今年发布的最新GPU H100,采用的是专为英伟达加速计算需求设计优化的TSMC 4N 工艺,集成800亿个晶体管,显著提升了AI、HPC、显存带宽、互连和通信的速度,并能够实现近5TB/s的外部互联带宽。
英伟达CEO黄仁勋发布H100时表示,20个H100 GPU便可承托相当于全球互联网的流量,使其能够帮助客户推出先进的推荐系统以及实时运行数据推理的大型语言模型。
当然,壁仞科技联合创始人、CTO洪洲也给出了壁仞科技首款通用GPU能实现突破性性能的底层原因——自主原创的芯片架构壁立仞。
壁立仞架势是以数据流为中心的架构,目标就是打破当前GPU架构面临的瓶颈,实现更强大的性能。具体而言,壁立仞架构有6大特性:TF32+数据流精度、TDA数据流存取加速、C-Warp数据流并行、NME减少数据搬移、NUMA/UMA减少数据搬移、SVI数据流隔离。

洪洲说,“壁立仞架构对数据流进行深度的优化,通过六大技术特性,比较完整地解决了数据搬移的瓶颈和并行度不足的问题,使得BR100芯片在给定的工艺下实现了性能和能效的跨越式进步。”
除了架构方面的努力,壁仞科技业采用了Chiplet的设计理念,让芯片总面积可以突破光罩尺寸对单芯片面积的限制,集成更多的算力和通用性逻辑。“通过缩小单个计算芯粒的面积,还可以同时提升产能与良率,进而极大地降低硅片的成本,并支持更灵活的产品策略。” 洪洲同时表示。

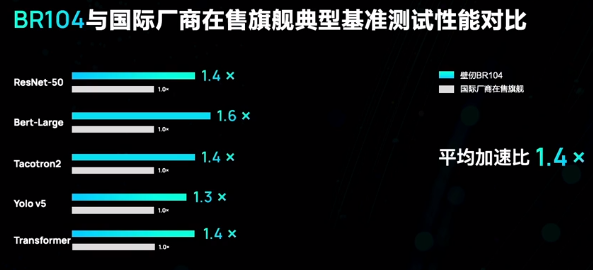
除了旗舰级BR100,壁仞科技今天还发布了BR104,同样采用壁立仞架构,拥有1个计算芯粒,性能约为BR100的一半,同样超越了国际厂商的在售旗舰产品。
 壁仞科技联合创始人、CTO洪洲
壁仞科技联合创始人、CTO洪洲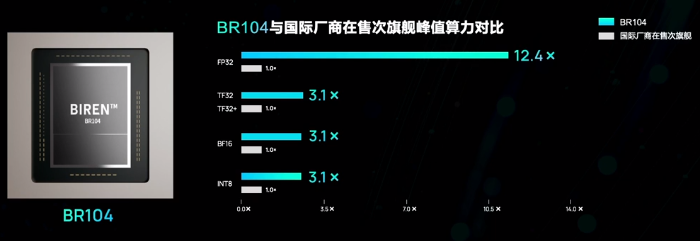
基于BR100和BR104的产品分别叫做壁砺100和壁砺104,可以构建从板卡模组到服务器的产品。

当然,壁仞科技也深知大算力芯片比拼的是软件和生态,更需要客户的支持。
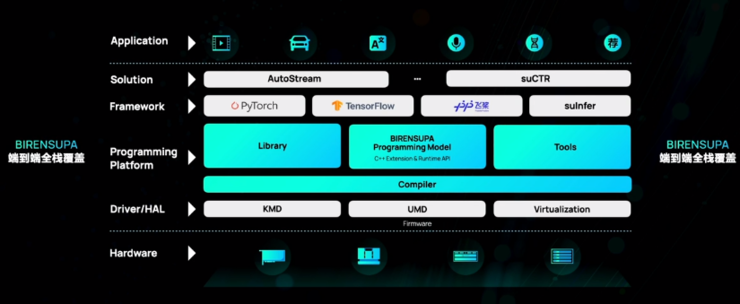
基于BR100,壁仞科技自主研发BIRENSUPA软件平台,这一平台位于软件栈的中心位置,包括BIRENSUPA编程模型、加速库、工具链、编译器等组件。开发者可以通过这些组件,发挥BR100系列硬件的算力,并开发各种应用。
发布会上,壁仞科技联席CEO李新荣与百度飞桨训练芯片适配技术负责人李琦共同宣布,壁仞科技加入由百度飞桨发起的硬件生态共创计划。

对于一家初创公司而言,建设生态的周期非常长,投入也十分巨大,所以壁仞科技也会兼容目前主流的GPU生态,与客户现有的基础设施做到高度的兼容,方便客户的迁移。
同时,壁仞也建设自己的生态,比如,壁仞科技开发者云也已经正式上线,官网上已开放邀测。
平安科技以及中国移动都在发布会上明确了与壁仞科技的合作目标。
从硬件到软件再到应用,壁仞科技已经正式交出了首款产品的答卷,接下来就要接受市场的检验了。
雷峰网原创文章,未经授权禁止转载。详情见转载须知。