来源:机器之心
机器之心发布
机器之心编辑部
百度正式发布基于飞桨的生物计算平台 - 螺旋桨 PaddleHelix,进军生物计算领域。
在本月 20 号召开的 WAVE SUMMIT+2020 深度学习开发者峰会上,百度正式发布了基于飞桨的生物计算平台 - 螺旋桨 PaddleHelix,进军生物计算领域。本次发布的螺旋桨 PaddleHelix 生物计算开源工具集,提供了包括 RNA 二级结构预测、大规模的分子预训练、药物 - 靶点亲和力预测、以及 ADMET 成药性预测等一系列算法和模型,重点满足生物医药,疫苗设计和精准医疗方面的 AI 需求。
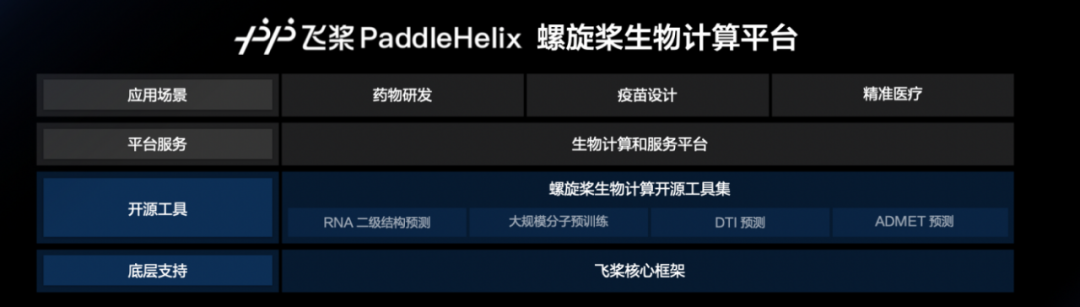
螺旋桨 PaddleHelix 官网地址:https://www.paddlepaddle.org.cn/paddle/paddlehelix
螺旋桨 PaddleHelixGitHub 地址:https://github.com/PaddlePaddle/PaddleHelix
生物医药
在生物医药领域,小分子化合物的筛选是非常关键的环节。为了设计出某种疾病的特效药,一方面要找到能够和疾病靶点结合、具有足够活性的小分子药物;另一方面又要保证药物在人体内能够正常发生作用,以及满足一系列额外性质(药物的吸收,分布,代谢,排泄,毒性,统称 ADMET)。
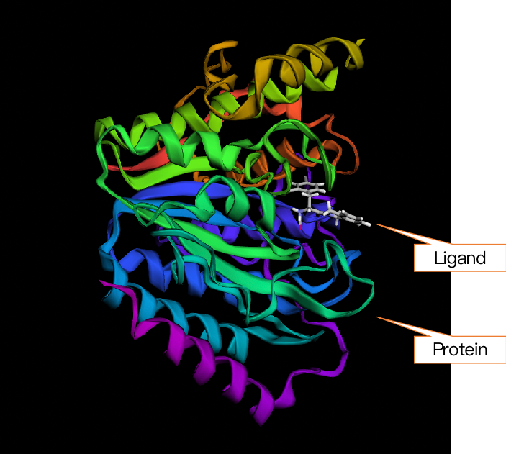
靶蛋白(Protein)- 药物配体(Ligand)复合物 (来源:PDBBind-cn.org)
传统的药物发现方法包括基于靶点结构的药物设计(Structure Based Drug Design, SBDD),基于碎片的药物设计(Fragment Based Drug Design, FBDD),老药新用 (Repurposing),以及计算机虚拟药物设计(Computational-Aided Drug Design, CADD)等等。这些方法均存在依赖体内(in vivo)体外 (in vitro) 实验验证,或者消耗大量计算资源等问题。因此近年来,基于分子的结构和知识来直接预测亲和性的 AI 药物设计(AIDD)逐渐被广泛认可和应用。相比于 CADD,AIDD 展现出了性能上的巨大优势,但其效果同时受到生物计算领域数据量的限制。下面的表格(表 1)展示生物计算一些重要问题的典型数据量,其中绿色的是有标注数据。我们看到,尽管这个领域有大量的无标注数据(仅有分子结构或者序列,没有性质,或者次级结构),有标注数据却非常少,难以支撑高质量的深度模型。
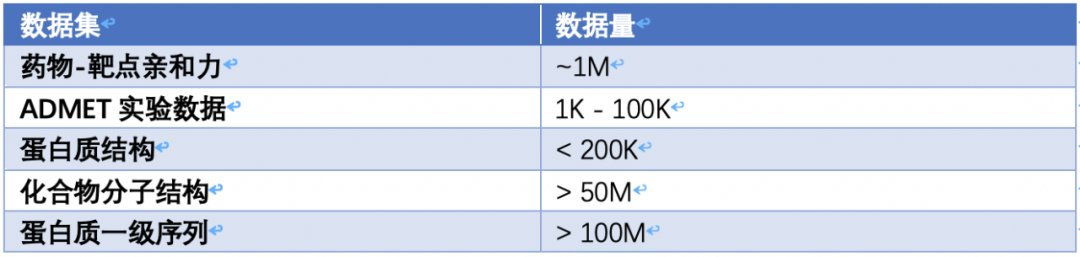
表1
在 AI 的其他领域也存在类似问题。以自然语言处理为例,这个领域存在 NER,逻辑推断,阅读理解,文本生成等等非常多的子问题。这些问题中的有标注数据量都非常少。但是人类文明中累积了大量的无标注语言文字,这些无标注语料给自然语言处理提供了表示学习(Representation Learning)的机会。在这样的背景下,BERT, ERNIE 等一系列基于自监督(Self-Supervised)学习的方法被提出。
正是基于此,螺旋桨 PaddleHelix 提出基于表示学习,多任务学习(Multi-Task Learning, MTL)和元学习(Meta Learning)来降低深度学习在生物计算中的技术和数据门槛,提升其效果。包括生物大分子(蛋白质,DNA,RNA)或者药物小分子都由原子或者亚基组成,都可以通过序列,图,或者三维结构表示。一种自然的想法,是像在自然语言处理领域一样,利用无标注数据上的自监督学习来优化分子的表示,再将其应用到下游任务。同时,生物计算领域存在大量的零散的任务,以 ADMET 为例,有 30~50 个指标需要考虑。这样的问题中,百度的生物计算团队也认为多任务学习和元学习将会发挥重要作用。
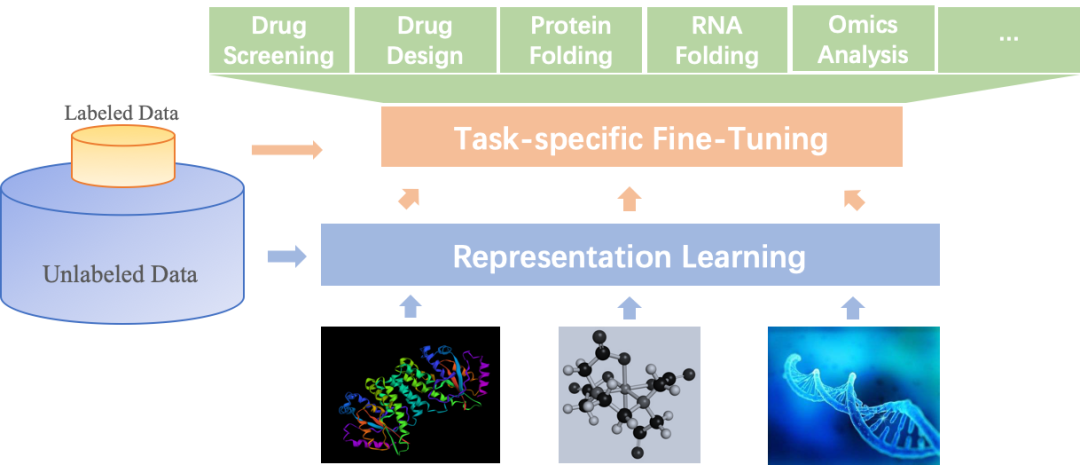
螺旋桨 PaddleHelix 复现并内置了业界主流的分子预训练模型(如表 2),以及常用的很多组网工具(CNN, Transformer, LSTM, ResNet,GNN 等等),开发者基于预训练模型实现自己的模型只需要短短几行代码。螺旋桨 PaddleHelix 也提供了一些通过了验证的,可以有效应用于下游任务的模型,效果如表 2 所示。
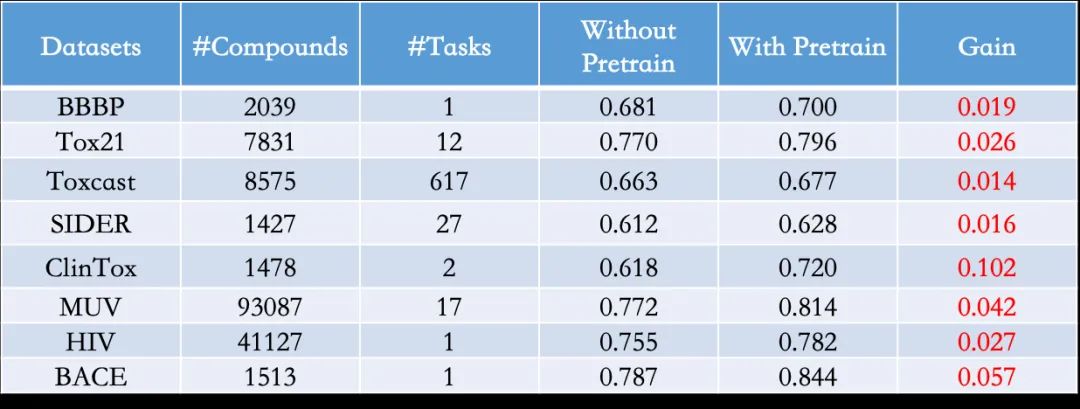
表2:使用预训练在分子性质预测中带来显著提升
疫苗设计
疫苗是通过把病毒或病菌相关的抗原(通常是蛋白)预先输入人体,引起人体免疫反应的物质。传统的疫苗需要体外制备抗原蛋白,通常效率低,难于快速大规模生产,因此可在人体自身内生产抗原蛋白的 mRNA 疫苗受到越来越多的关注。mRNA 疫苗制备速度快、无感染风险,但有一个天然劣势就是 mRNA 非常不稳定,这与 mRNA 的二级结构相关。mRNA 疫苗设计的关键就在于,在不改变翻译出的抗原蛋白的前提下,设计 mRNA 序列使其二级结构尽可能更稳定。
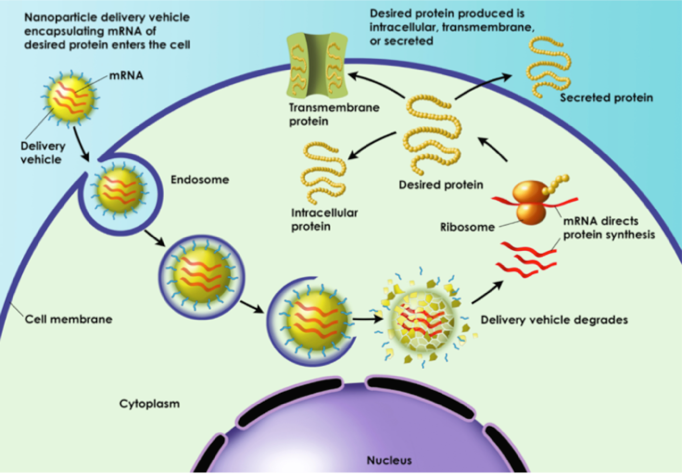 mRNA 疫苗示意图(来源:https://translate.bio/)
mRNA 疫苗示意图(来源:https://translate.bio/)百度研究院生物计算团队从 2018 年开始就开展了 RNA 结构预测和序列设计相关研究,并在 2019 年 7 月和 2020 年 7 月分别发表了 LinearFold 和 LinearPartition 算法, 将 RNA 结构预测和分析的速度大大提升。其中 LinearFold 能够在 27 秒内完成新冠病毒全基因组结构分析,比传统算法速度提升 120 倍。正是有了之前的积累,百度研究院在短短两个月就完成了 LinearDesign 的研发, 在 mRNA 疫苗设计上提出了革命性的方法。LinearDesign 能够在 11 分钟内完成新冠 mRNA 疫苗序列的设计,设计序列的稳定性和有效性大大提升。如图所示,左边是能翻译新冠 S 蛋白的野生型 mRNA 二级结构,其中存在大量易断裂的单链环。右边是 LinearDesign 设计序列的结构,断裂点更少,与野生型序列相比稳定性大大提升。百度研究院 RNA 结构预测与序列设计相关成果在美国 MIT 科技评论,以及美国消费者新闻与商业频道(CNBC)得到了高度评价,并在 2020 年全球人工智能峰会(AI Summit)上获得了 AI For Good(AI 向善)奖。
在螺旋桨 PaddleHelix 中,百度也完整开源了 LinearRNA 系列算法,目前主要包括 LinearFold 和 LinearPartition,开发者想要调用这些强大的工具仅仅需要一行代码。
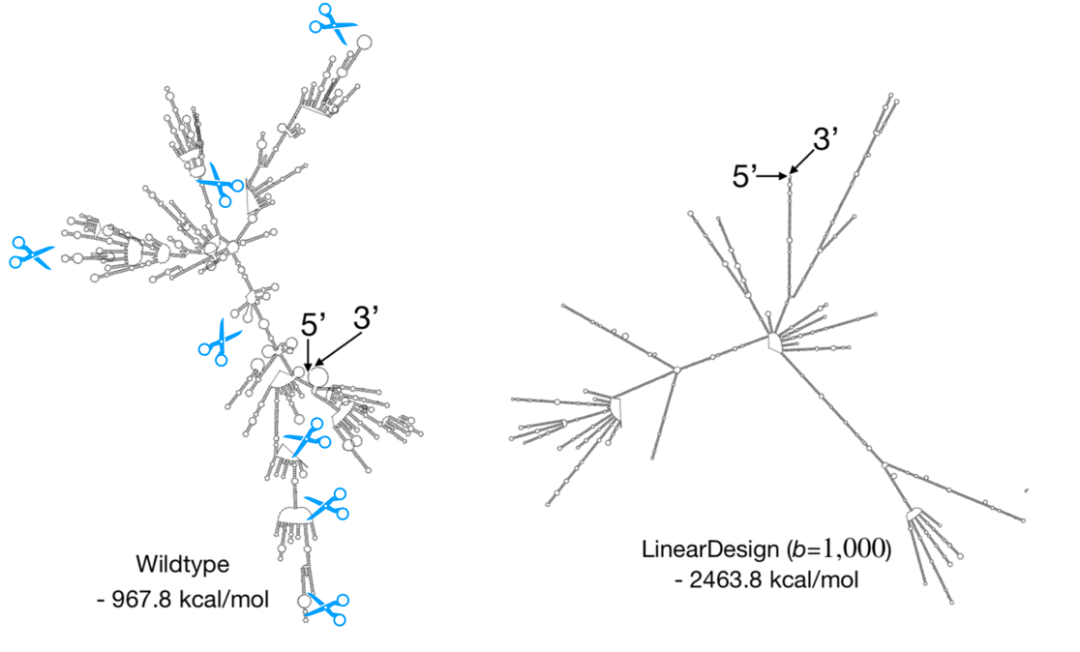
新冠S 蛋白的野生型 mRNA 结构和 LinearDesign 结构
精准医疗
精准医疗(precision medicine)的概念是指,根据患者特征(patient characteristics)实现准确的疾病诊断和分类,从而进行个性化匹配用药和跟踪治疗。相较于传统的 one-size-fits-all 治疗方案,精准医疗致力于通过临床数据、生活环境、特别是分子组学数据精确刻画个体特征,通过挖掘和探究隐含在多模态数据层面的信息进行综合分析和判断,最终提供更好更适配的药物选择和治疗方案从而提升患者的治疗效果最终提高个体的生存时间和生存质量。
部分图片素材来自网络
螺旋桨 PaddleHelix 也将提供基于多维数据(临床随访数据、蛋白组数据、基因组数据、转录组数据、甲基化组数据、小 RNA 数据、单细胞组数据)的表示学习算法模型、药物响应模型、疾病预后模型等,旨在帮助行业内的医疗专家、研究人员和从业者更好的利用组学数据和分子特征更精确的刻画个体表示做组群区分,从而在精准医疗的三个维度预防、预测、治疗(Prevention、Prediction、Treatment)构建更好更准确的医疗模型,帮助到更多的患者得到最好最适配的治疗。
结语
在 WAVE SUMMIT+2020 深度学习开发者峰会上,百度集团副总裁、深度学习技术及应用国家工程实验室副主任,吴甜女士对螺旋桨 PaddleHelix 的发展做了简短的概述,希望未来与合作伙伴共建,逐步形成一套完整的面向行业的生物计算生态和服务。
我们也期待,螺旋桨 PaddleHelix 的发布能带来更多的跨界惊喜,在生物医药、精准医疗、疫苗设计等领域发挥出更大的价值。