来源:机器之心
作者:魔王、杜伟
人工智能「我训练我自己」系列又有了新进展。
在机器学习领域里,Dropout 是一个较为重要的方法,其可以暂时丢弃一部分神经元及其连接,进而防止过拟合,同时指数级、高效地连接不同网络架构。
2012 年,Hinton 等人在论文《Improving neural networks by preventing co-adaptation of feature detectors》中首次提出 Dropout 技术。在这之后,Dropout 的变体大量涌现,该方法也成为机器学习研究者常用的训练技巧。
我们知道,机器学习可以让很多人们的工作自动化,而机器学习本身的自动化程度也在不断提高。近日,卡内基梅隆大学在读博士 Hieu Pham、谷歌大脑研究科学家 Quoc V. Le 提出了一种自动学习 Dropout 的方法。研究者称,通过强化学习来学习 Dropout 的规律,AutoDropout 可以提高图像识别、语言理解和机器翻译的性能。
该研究已被人工智能顶会 AAAI-2021 接收。
dropout 方法的利与弊
现代神经网络常常过参数化,因而需要适当的正则化来避免过拟合现象。Dropout 是一种常见的正则化方法,该方法从网络的一些中间层中随机选择神经元,并将这些神经元的值替换为零。换言之,这些神经元被从当前训练步中丢弃。近来更多的研究表明,为丢弃的神经元施加某些结构要比随机均匀丢弃神经元带来更显著的性能提升。但在实践中,dropout 模式为适应不同的应用需要进行调整变化。
例如在文本领域,Zaremba 等人(2014)认为,对于多层 LSTM 而言,仅丢弃垂直连接中的神经元要好于丢弃任何位置的神经元。之后,Gal 和 Ghahramani(2016b)提出了 Variational Dropout,他们丢弃了网络中任何位置的神经元,但在时间维度上共享了同一个 dropout 模式。然而,当前 Transformer 架构未使用这两种方法,仅使用了原版 Dropout。LSTM 和 Transformer 在如何实现 Dropout 方面的差异表明,dropout 模式需要根据 NLP 中不同的模型架构进行调整。
在图像领域,原版 Dropout 通常仅应用于卷积神经网络(ConvNet)中的全连接层,其他卷积层往往需要特定结构的 dropout 神经元。例如,Stochastic Depth 丢弃残差网络中的整个残差分支,DropPath 丢弃多分支卷积单元中的整个分支。Ghiasi 等人(2018)提出的 DropBlock 丢弃卷积层中的相邻神经元方块(按块丢弃)。虽然 DropBlock 在 ResNet-50 和 AmoebaNet 架构中表现良好,但它并未被证实在 EfficientNet 和 EfficientDet 等更近期架构中实现成功应用。所以,ConvNet 架构使用 dropout 模式的差异也表明需要针对不同架构进行专门调整。
谷歌:用自动化方式寻找 dropout 模式
最近,来自谷歌大脑的两位研究者通过研究以往工作中的 dropout 模式,发现这些模式不仅难以设计,而且还需要针对每个模型架构、任务和域进行专门调整。
为了解决这些难题,研究者提出了 AutoDropout,它可以实现专用 dropout 模式设计过程的自动化。AutoDropout 的主要贡献是一个新颖的结构化 dropout 模式搜索空间。在这个搜索空间中,人们可以为每个模型架构和任务找到适合的 dropout 模式。此外,该搜索空间还泛化了很多现有的 dropout 模式。

论文链接:https://arxiv.org/pdf/2101.01761.pdf
下图 1 展示了 AutoDropout 搜索空间中的一种 dropout 模式,该模式通过对邻近区域铺展并进行几何转换而生成。得到的 dropout 模式可应用于卷积输出通道(图像识别模型中的常见构建块)。

AutoDropout 的实现包括一个通过强化学习(RL)进行训练的控制器。RL 的奖励是将 dropout 模式应用于目标网络后在感兴趣数据集上的验证性能。研究者设计了一种基于分布式 RL 的搜索算法,从而最大程度地利用任意计算节点集群上的所有可用机器。
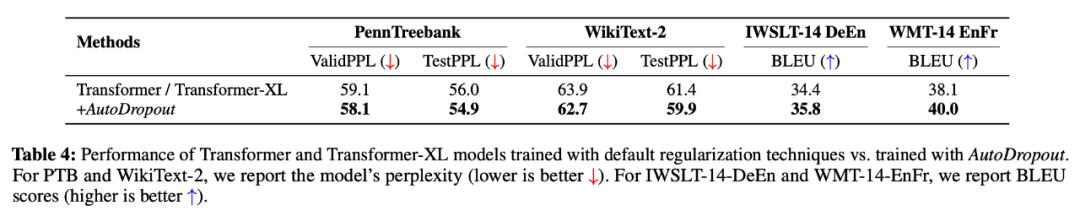
实验结果表明,AutoDropout 找到的 dropout 模式能够显著提升常见 ConvNet 和 Transformer 架构的性能。在 ImageNet 数据集上,AutoDropout 将 ResNet-50 的 top-1 准确率从 76.5% 提升至 78.7%,EfficientNet-B7 的性能则从 84.1% 提升至 84.7%。在 CIFAR-10-4000 的半监督设置下,AutoDropout 也将 Wide-ResNet-28-2 的准确率从 94.9% 提升至 95.8%。对于语言建模任务而言,AutoDropout 将 Transformer-XL 在 Penn Treebank 数据集上的困惑度从 56.0 降至 54.9。
此外,在 IWSLT 14 数据集上执行德英翻译任务时,AutoDropout 发现的 dropout 模式将 Transformer 的 BLEU 值从 34.4 提升至 35.8,实现了该数据集上的新 SOTA。在 WMT 2014 英法翻译任务上,使用迁移 dropout 模式后的 BLEU 值也比使用原版 Dropout 的 Transformer 模型提升了 1.9。
虽然 AutoDropout 的搜索成本很高,但它具有一个简单用例,即像使用 AutoAugment 策略来提升 SOTA 模型一样,AutoDropout 发现的 dropout 模式可以被应用到现有 pipeline 中。
方法详解
和之前的很多研究一样,该研究也使用逐元素乘法掩码在搜索空间中表示 dropout 模式。为了弥补训练和推断之间的差距(训练时使用掩码,推断时则不使用),研究者在训练期间将未被丢弃神经元的值进行了恰当地缩放。具体而言,为了在神经网络层 h 应用 dropout 模式,研究者随机生成二进制掩码 m(其形状与 h 相同),然后缩放掩码 m 中的值,并替换 h:
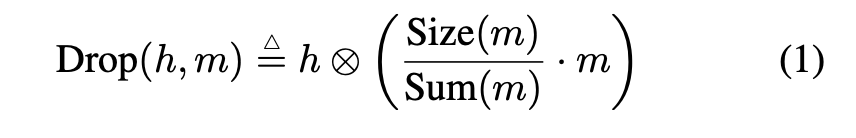
研究者表示,该研究提出的方法是通用的,能够很好地用于 ConvNet 和 Transformer。接下来就来看该方法用于 ConvNet 时的搜索空间,以及如何泛化至 Transformer。
ConvNet 中的 dropout 模式搜索空间
搜索空间中的基本模式是连续矩形(contiguous rectangle)。然后将矩形铺展开得到 dropout 模式。对于 ConvNet,定义基础矩形的超参数是高和宽的大小(size),定义铺展的超参数是步幅(stride)和重复次数(repeat),示例参见下图 2。如果有 C 个通道,则可以采样 C 个单独的 dropout 模式,或者仅采样一个 dropout 模式,然后将其沿着特征维度共享。
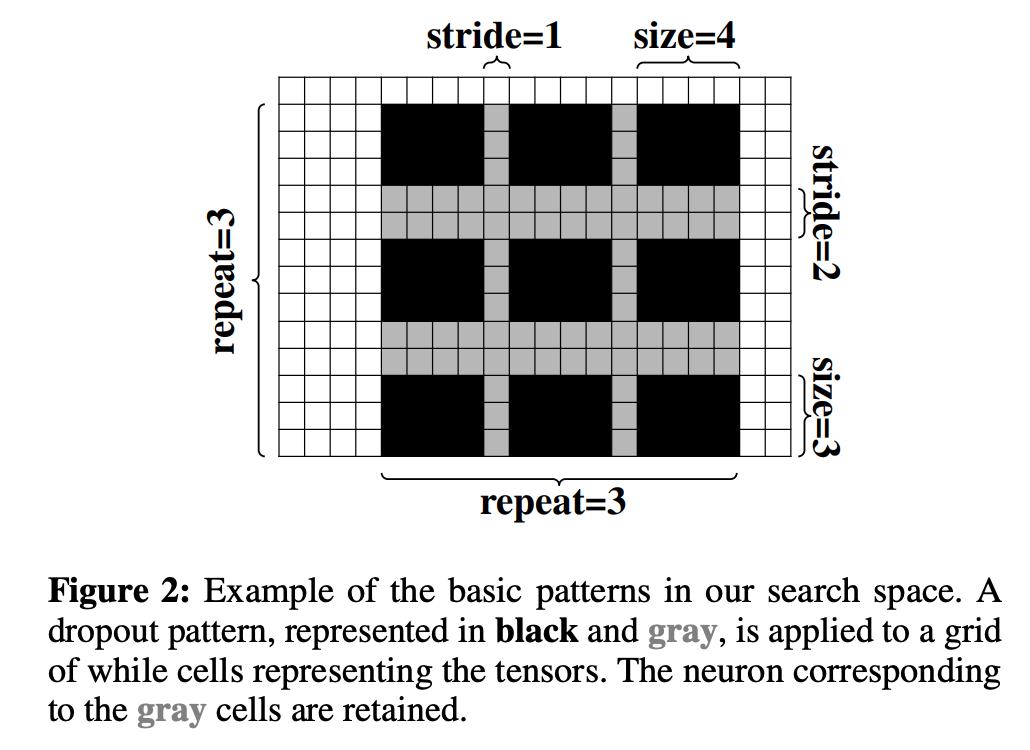
那么要在哪里应用dropout 模式呢?
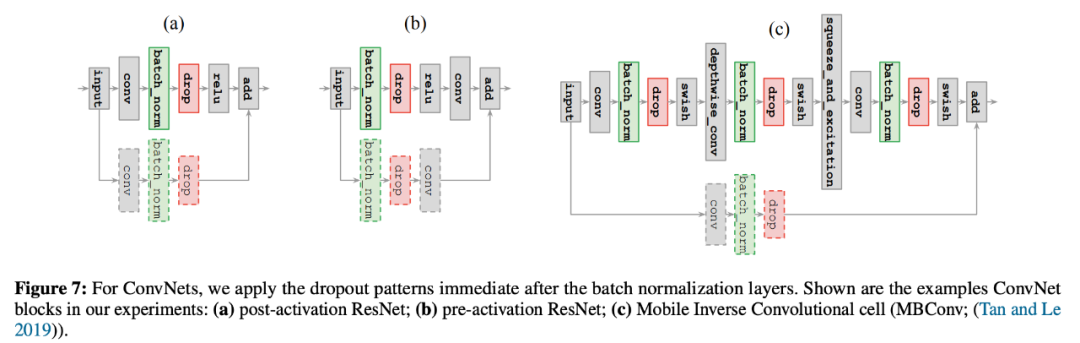
该研究选择对批归一化层的输出应用 dropout 模式,因为他们在实验中发现,在网络的其他位置应用 dropout 模式通常会导致搜索过程出现不稳定训练。如果 ConvNet 中存在需要正则化的残差连接,则可以选择是否对残差分支应用 dropout 模式。研究者决定将这一决策交给控制器。下图 7 展示了在 ConvNet 中,研究者在批归一化层之后应用 dropout 模式:
控制器模型和搜索算法
研究者使用 Transformer 网络对控制器进行参数化,参见下图 3:
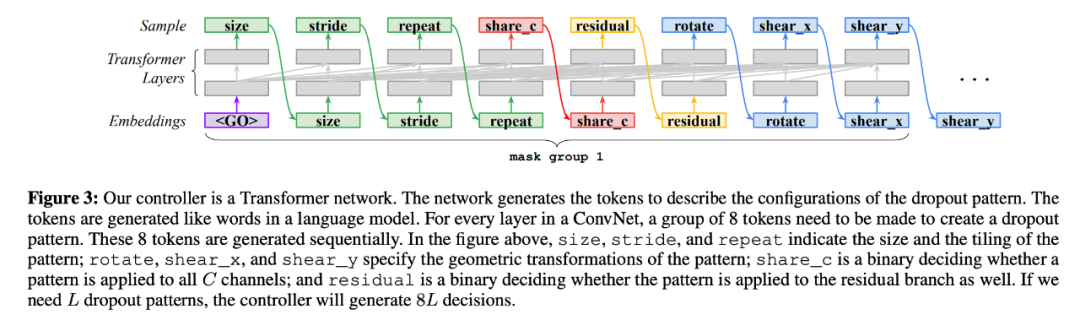
Transformer中的 dropout 模式搜索空间
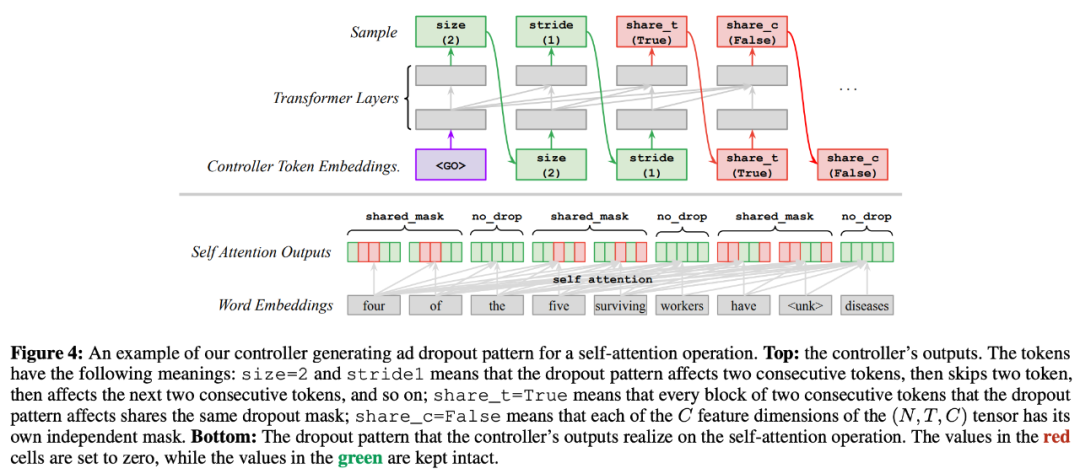
Transformer 模型中的中间层通常有三个维度 (N, T, C),其中 N 和 C 是批归一化和通道维度(与 ConvNet 类似),T 表示 token 数,如单词或子词单元。维度 T 的 dropout 模式通过生成四个超参数来实现:size、stride、share_t 和 share_c。size 表示 dropout 模式影响的 token 数;stride 表示 dropout 模式跳过的 token 数;share_t 表示使用相同的噪声掩码或单独的噪声掩码,size 覆盖的所有 token 是否设置为 0;share_c 表示 dropout 模式是否沿着通道维度 C 共享。一旦这四个参数确定了,我们就可以在每一个训练步上采样起始位置,进而应用得到的 dropout 模式。研究者一直重复该模式直到序列结束。下图 4 展示了控制器从搜索空间中采样的 dropout 模式,以及如何将其应用于词序列:
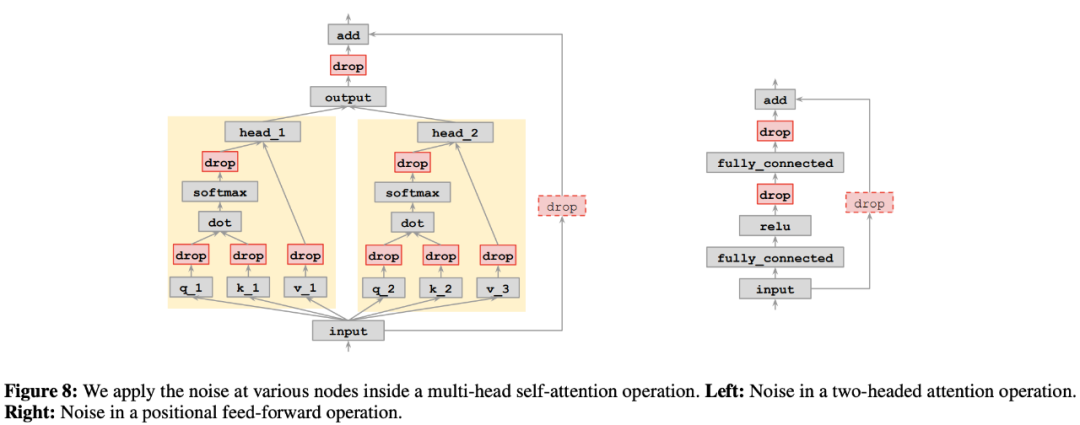
至于在哪里应用 dropout 模式,研究者发现搜索空间中的 dropout 模式可以灵活应用于一个 Transformer 层内的多个子层,于是他们对每个子层分别应用一个 dropout 模式。下图 8 展示了在 Transformer 模型中可以应用 dropout 模式的所有位置:
实验
在实验部分,研究者将 AutoDropout 应用到了 ConvNet 和 Transformer 架构中。对于 ConvNet,研究者分别进行了监督和半监督图像分类实验。对于 Transformer,他们进行了语言模型和机器翻译应用实验。最后,研究者还将本研究的搜索方法与随机搜索进行了对比。
使用 ConvNet 的监督图像分类
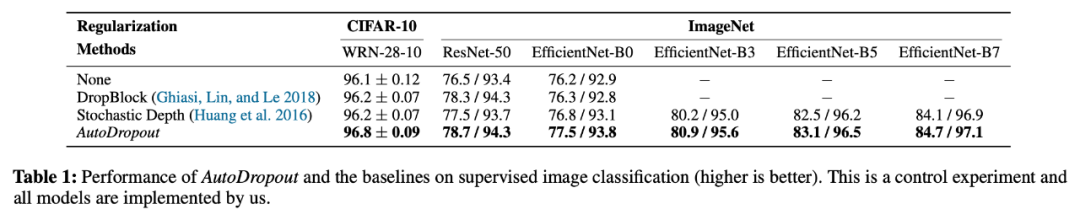
下表 1 展示了在 CIFAR-10 和 ImageNet 数据集上,在 ResNet 和 EfficientNet 模型中使用 DropBlock、Stochastic Depth 与 AutoDropout 的对照实验结果。
在 CIFAR-10 数据集上,WRN-28-10 模型使用 AutoDropout 得到的准确率比使用 DropBlock 高出 0.6%,相当于误差减少了 16%。需要注意的是,在该数据集上,与未使用任何正则化的模型相比,DropBlock 并没有出现显著提升,这表明丢弃邻近区域块的想法存在不足。
在 ImageNet 数据集上,与 DropBlock 相比,AutoDropout 将 ResNet-50 的 top-1 准确率提升了 0.4%,将所有 EfficientNet 模型的准确率平均提升了 0.7%。提升程度要高于 DropBlock 在 AmoebaNet 中提升的 0.5%,而且 EfficientNet 基线的准确率要高于 AmoebaNet。
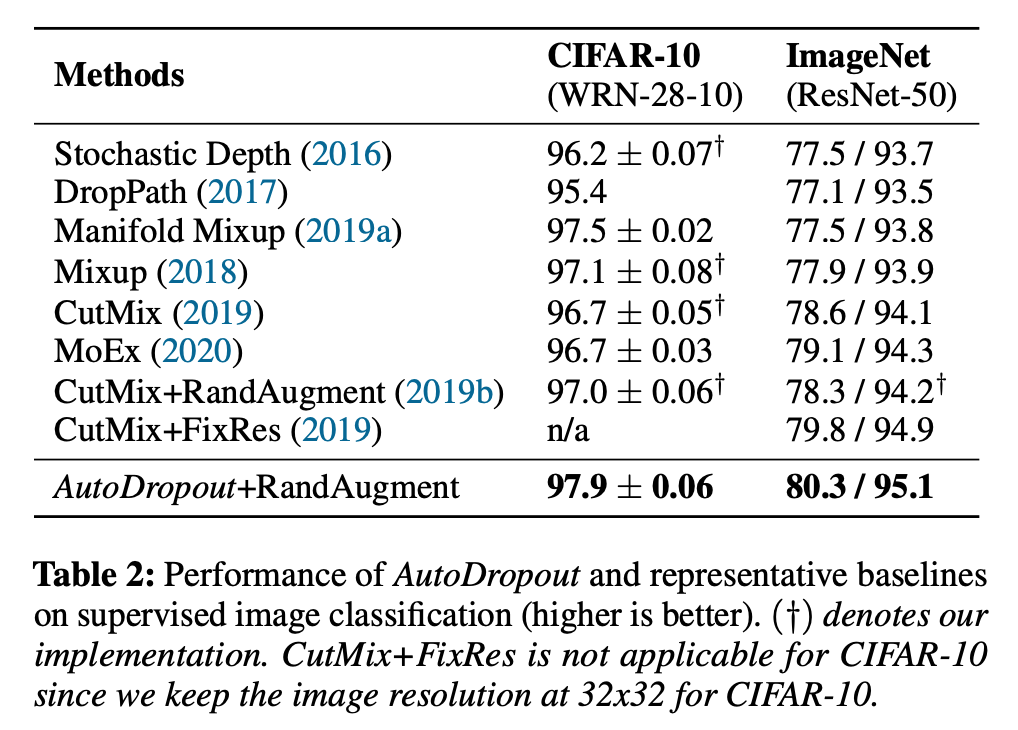
接着,研究者通过结合 AutoDropout 与其他数据增强方法,突破了 WRN28-10 和 ResNet-5 的极限。如下表 2 所示,AutoDropout+RandAugment 在 CIFAR-10 和 ImageNet 数据集上优于现有 SOTA 结果。
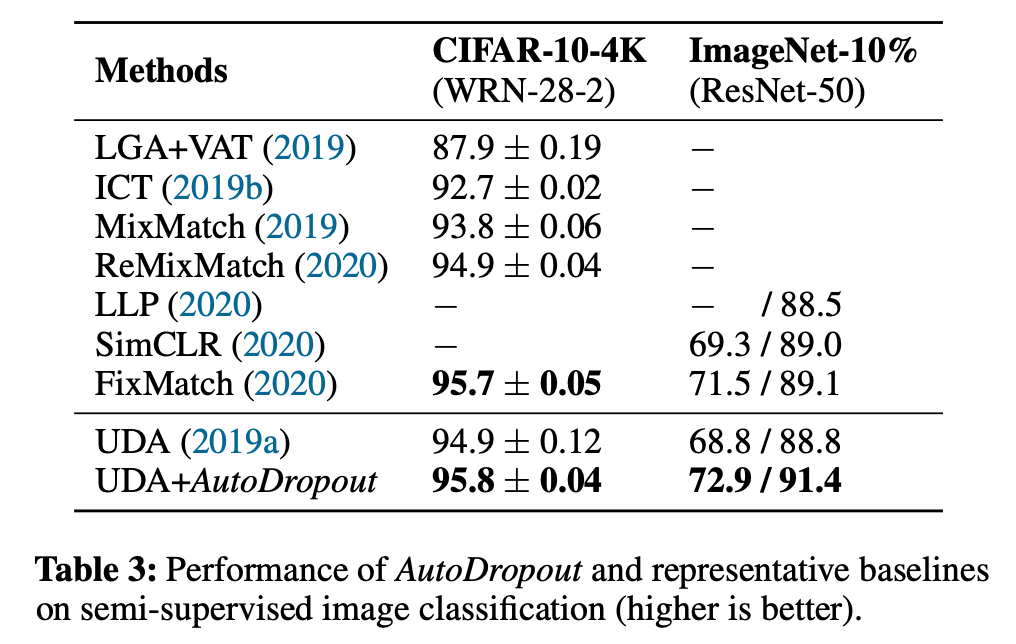
使用ConvNet 的半监督图像分类
研究者将 AutoDropout 应用于无监督数据增强 (UDA)。如表 3 所示,AutoDropout 找到的 dropout 模式使 UDA 在 CIFAR-10 数据集上的性能提升了 0.9%,在 ImageNet 上的 Top-1 准确率提升了 4.1%。
语言模型与机器翻译
研究者将 AutoDropout 应用于 Transformer 模型,结果参见下表 4。从中可以看出,使用 AutoDropout 后模型在 PTB 上获得了最低困惑度。他们还与 Transformer-XL 使用的 Variational Dropout 进行了对比,发现使用 AutoDropout 后困惑度比使用 Variational Dropout 低了 1.1,性能提升显著。
与随机搜索的对比
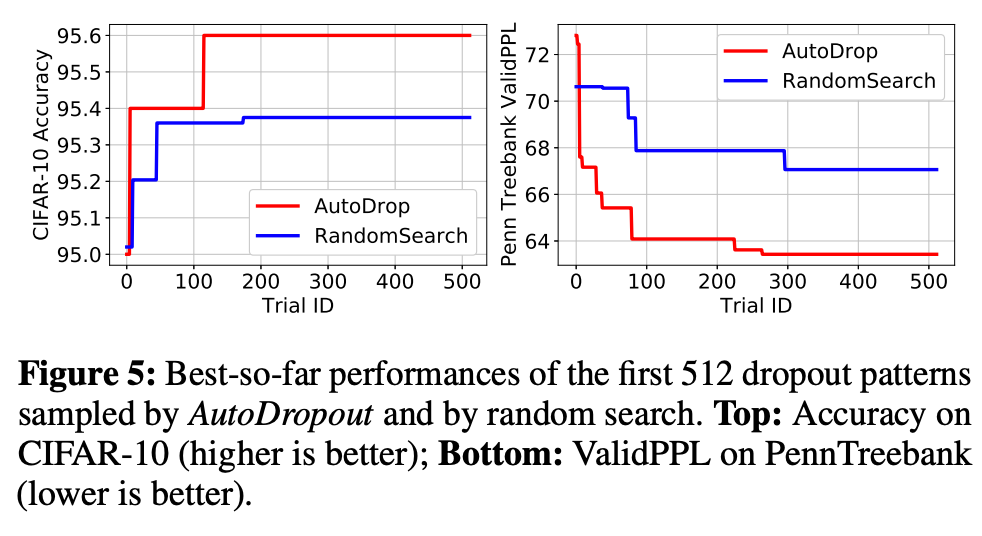
在下图 5 中,研究者绘制了这两种方法的当前最优性能,并观察了 AutoDropout 和随机搜索之间的实质差异。具体来说,在 CIFAR-10 数据集上,AutoDropout 找到的最佳 dropout 模式要比随机搜索准确率高 0.2%。