来源:机器之心
作者:Hanna Mazzawi等
机器之心编译
编辑:魔王、杜伟
为了帮助研究者自动、高效地开发最佳机器学习模型,谷歌开源了一个不针对特定领域的 AutoML 平台。该平台基于 TensorFlow 构建,非常灵活,既可以找出最适合给定数据集和问题的架构,也能够最小化编程时间和计算资源。

神经网络的成功通常取决于在多种任务上的泛化性能。然而,设计此类神经网络很有难度,因为研究社区对神经网络如何泛化仍没有充分的了解:对于给定问题,什么样的神经网络是适合的?深度如何?应该使用哪种层?LSTM 层就可以了,还是使用 Transformer 更好一些?抑或将二者结合?集成或蒸馏会提升模型性能吗?
近年来出现的 AutoML 算法可以帮助研究者自动找出合适的神经网络,无需手动试验。神经架构搜索 (NAS) 等技术利用强化学习、进化算法和组合搜索等算法,基于给定搜索空间构建神经网络。在恰当的设置下,这些技术找到的神经网络架构优于手动设计的网络架构。不过,这些算法计算量较大,在收敛前需要训练数千个模型。而且,它们探索的搜索空间是域特定的,包括大量先验人类知识,无法很好地实现跨域迁移。例如,在图像分类领域中,传统 NAS 技术搜索两个不错的构造块(卷积和下采样),然后遵循惯例创建完整的网络。
为了克服这些缺陷,并将 AutoML 解决方案扩展到更广泛的研究社区,最近谷歌开源了一个自动、高效构建最优 ML 模型的平台 Model Search。该平台不针对某个特定域,因而足够灵活,并且能够找出最适合给定数据集和问题的架构,同时最小化编程时间和计算资源。该平台基于 TensorFlow 框架构建,既可以单机运行,也可以在分布式机器设置上运行。

GitHub 地址:https://github.com/google/model_search
Model Search 平台概述
Model Search 系统包含多个训练器、一种搜索算法、一种迁移学习算法和一个存储多种评估模型的数据库。该系统能够以自适应和异步的方式运行多种机器学习模型(采用不同架构和训练方法)的训练和评估实验。当每个训练器单独执行训练时,所有训练器共享从实验中获得的知识。
在每个轮次开始时,搜索算法查找所有已完成的试验,并使用集束搜索(beam search)来决定接下来要尝试的部分。之后,该搜索算法在目前发现的最佳架构之一上调用突变,并将生成的模型分配回训练器。
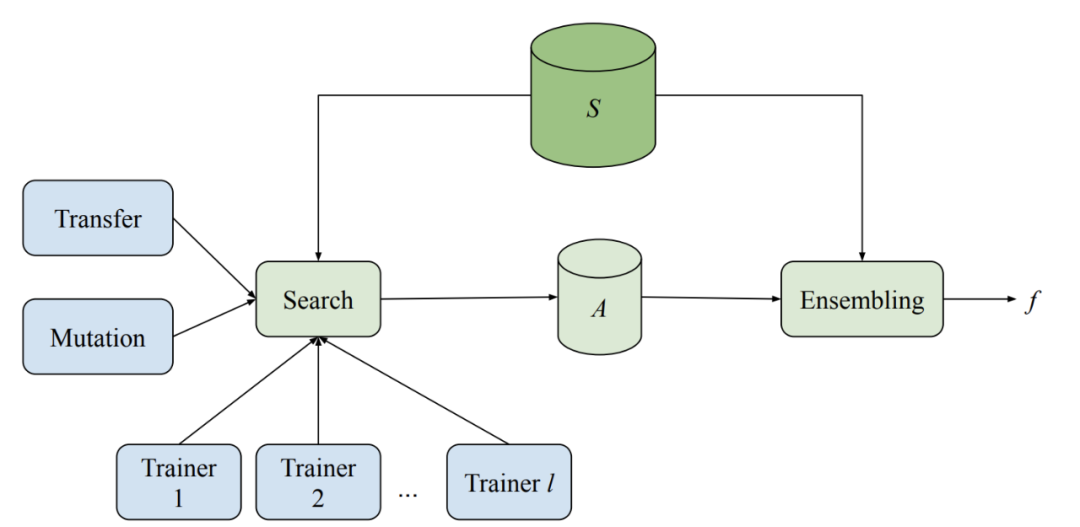
该系统使用一组预定义的块来构建神经网络模型,其中每个块代表了一种已知的微架构,如 LSTM、ResNet 或 Transformer 层。通过使用这些预先存在的架构组件,Model Search 可以利用跨领域 NAS 研究中现有的最佳知识。这种方法更加高效,因为它探索的是结构,而非更基础和更细化的组件,从而降低了搜索空间的规模。

各种神经网络微架构块都能运行良好,如ResNet 块。
此外,由于 Model Search 框架基于 TensorFlow 构建,因而各个块可以实现任意以张量作为输入的函数。例如,如果我们想要提出一种基于一系列微架构构建的新搜索空间,那么 Model Search 框架会吸收新定义的块并将它们合并至搜索过程,从而确保算法可以根据所提供的组件构建最佳的神经网络。这里的构建块甚至可以是能够解决某些特定问题的完全定义神经网络。在这种情况下,Model Search 可以作为一种强大的集成机器。
Model Search 中实现的搜索算法具有自适应性、贪婪性和增量性,因此这些算法的收敛速度快于强化学习算法。但是,这些算法也会模拟强化学习算法中的「探索与利用」(explore and exploit)特性,具体操作是首先分离搜索找出优秀的候选对象(即探索步骤),然后通过集成这些发现的候选对象来提升准确率(即利用步骤)。
在对架构或训练方法做出随机变更之后(如增加架构的深度),主搜索算法做出自适应修改,执行效果最好的 k 项实验之一(其中 k 由用户指定)。

网络在多个实验中不断演化的动态展示图。
为了进一步提升效率与准确率,不同内部实验之间也可以使用迁移学习。Model Search 以两种方式实现迁移学习,分别是知识蒸馏和权重共享。知识蒸馏通过添加一个与高效模型的预测相匹配的损失项,提升候选对象的准确率。权重共享则通过复制先前训练模型中的适当权重并随机初始化其余权重,从先前训练的候选对象中(经过突变)bootstrap 一些参数。这种方式不仅可以加速训练过程,还有可能发现更多更好的架构。
实验结果
Model Search 用最少的迭代次数来改进生产模型。谷歌研究者在近期一篇论文《Improving Keyword Spotting and Language Identification via Neural Architecture Search at Scale》中展示了 Model Search 在语音领域的性能,它能够发现关键词检测与语言识别模型。只用了不到 200 次的迭代,Model Search 得到的模型就优于专家设计的内部 SOTA 生产模型,并且前者的训练参数少了大约 13 万个(184K 参数 vs. 315K 参数)。
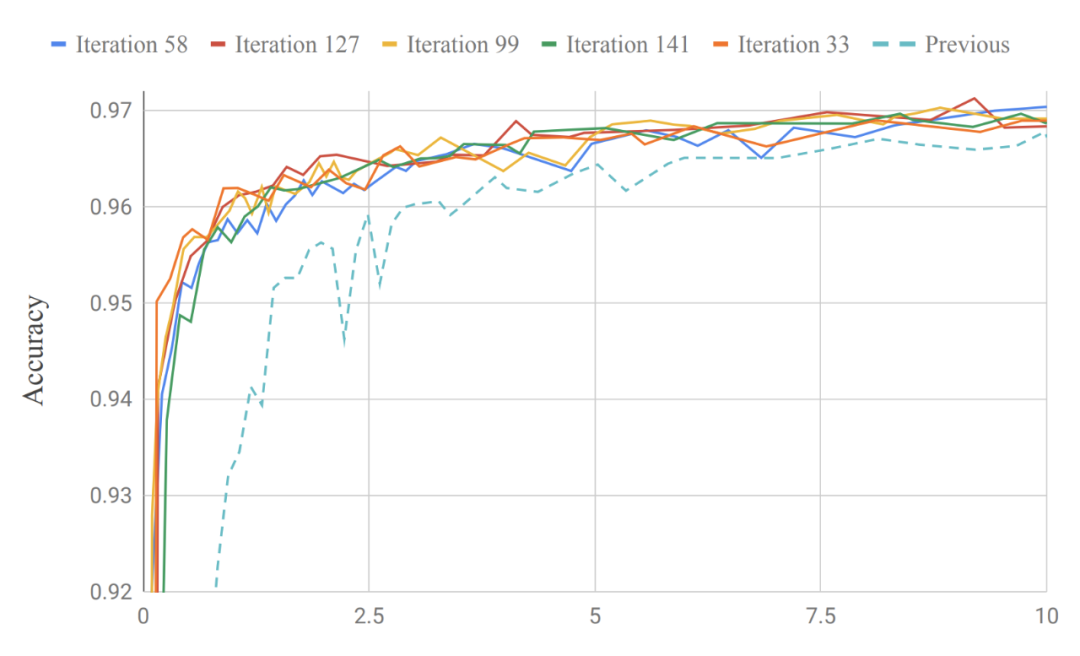
Model Search 经过给定迭代次数后得到的模型准确率与之前的关键词检测生产模型性能对比。
谷歌研究者还使用 Model Search,在 CIFAR-10 图像数据集上寻找适合的图像分类架构。使用一组已知卷积块(包括卷积、resnet 模块、NAS-A 单元、全连接层等)后,Model Search 能够在 209 次试验(即只探索了 209 个模型)后快速实现基准准确率——91.83。而之前的顶级架构达到相同准确率需要的试验次数要多得多,例如 NASNet 算法需要 5807 次试验,PNAS 需要 1160 次试验。
目前,Model Search 的代码已开源,研究者可以使用这个灵活、不受领域限制的框架发现 ML 模型。