来源:机器之心
编辑:张倩
一篇强化学习的论文,投了三年都没中,期间实验室都倒闭了。最后,作者抱着试试看的心态投了 Nature,结果:中了。

Nature 论文链接:https://www.nature.com/articles/s41586-020-03157-9
arXiv 链接:https://arxiv.org/pdf/1901.10995.pdf
这篇论文来自 Uber AI Labs,作者是原 Uber 研究科学家 Adrien Ecoffet 和高级研究科学家 Jeff Clune 等人。他们曾在 2018 年的一篇博客中介绍了这篇论文。

博客原文:https://eng.uber.com/go-explore/
在论文中,作者提出了一类名为 Go-Explore 的算法,旨在解决探索困难(hard-exploration)的问题。通过一系列算法设计,Go-Explore 在 Montezuma's Revenge(蒙特祖玛的复仇)和 Pitfall 两款雅达利游戏中取得了出色的成绩,这两款游戏之前难倒了大部分强化学习算法。具体来说,在不提供任何领域知识的情况下,Go-Explore 在 Montezuma s Revenge 上的得分超过 43000 分,几乎是之前 SOTA 水平的 4 倍;在 Pitfall 上,具有领域知识的 Go-Explore 是第一个得分高于零的算法。它的平均表现是近 6 万分,超过了人类专家的表现。
虽然表现非常惊艳,但这篇论文一直没被机器学习领域的顶会接收。两年之后,也就是 2020 年,Uber 宣布裁员,Uber AI Labs 也在这波裁员潮中服从「战略性选择」,没逃过被关闭的命运。同年,几位作者先后加入了 OpenAI。
在文章即将被埋没之际,《Nature》带来了好消息:你们的论文被接收了。
在文章发出的当天,Jeff Clune 难掩激动之情,通过推特分享了团队的喜悦和成果。
同样深耕强化学习的香港中文大学信息工程系助理教授周博磊感叹道:强化学习方向的论文有多难发,从这篇文章就可以看出来。

甚至有人从中get 了发文章的「小窍门」,你学会(fèi)了吗?

Go-Explore是一种什么算法
智能探索(intelligent exploration)是强化学习面临的一大挑战,尤其是在奖励稀疏或有误导性的情况下。在探索困难问题中,Montezuma’s Revenge 和 Pitfall 是两项重要基准,现有的强化学习算法在这两款游戏中的表现都难以令人满意,即使是那些具有内在动机的算法也不例外。
为了解决这一问题,Jeff Clune 等研究者提出了一种名为 Go-Explore 的新算法。该算法遵循以下原则:
1. 记住之前访问过的状态;
2. 首先回到一个有希望的状态(没有探索),然后再从中探索;
3. 通过穷尽(exploit)所有可能的方法(包括引入确定性)来解决模拟环境问题,然后通过模仿学习进行 robustify (即创建一个能够可靠执行 solution 的策略)。
这些原则的综合运用帮助 Go-Explore 算法在探索困难问题上取得了显著性能提升。
为了理解 Go-Explore 做出的改进,我们先来了解一下为什么之前的内在动机(IM)方法表现不好。
在 Go-Explore 出现之前,解决奖励稀疏问题的典型方法是 IM,它会为强化学习智能体提供鼓励探索的内在奖励(增强或替换来自环境的外部奖励)。IM 通常由好奇心、novelty-seeking 等心理学概念驱动,这些概念在人类探索和学习的过程中发挥着重要作用。尽管 IM 在解决稀疏奖励问题上取得了很大的进展,但在很多领域,IM 表现依然欠佳,如 Montezuma’s Revenge 和 Pitfall。Jeff Clune 等人假设,这种失败源于两个原因:detachment 和 derailment。
detachment 指的是,算法虽然鼓励智能体去探索未知的状态空间,但是当前状态到被探索状态空间的边界之间隔着很多被探索过的状态,算法并不能激励智能体越过这些 IR 很小的状态走到边界上再去探索。因此,当前状态到未被探索过的状态之间是「分离」的,这限制了有效的探索。那么自然有一个想法就是让智能体先走到已被探索过的状态的边界上,然后再去探索新的状态,但是现有的算法会在走到边界的半路上「边走边探索」,最后偏离轨迹,无法到达边界,这就是 derailment 所描述的问题。(引自知乎用户 @张楚珩)
Go-Explore 针对 detachment 和 derailment 这两大问题进行了改进,其算法结构如下图 2 所示:首先,用一种可能比较脆弱(brittle)的方式来解决问题,如解决问题的确定性版本;然后 robustify。
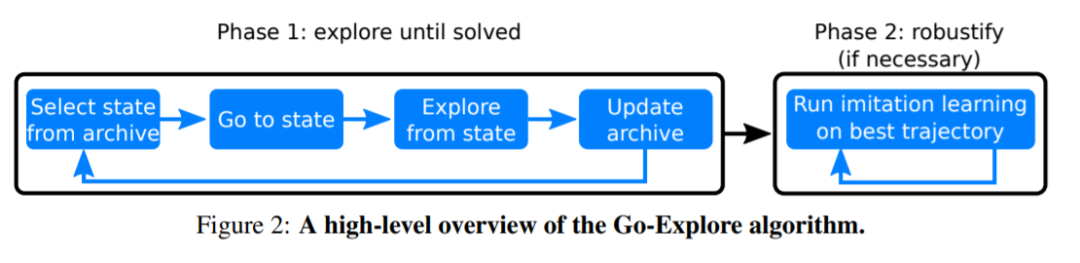
和 IM 算法类似,Phase 1 专注于探索不经常访问的状态,这构成了处理稀疏奖励和误导性问题的基础。与 IM 算法相比,Phase 1 通过积累状态档案和通过两种策略达到这些状态的方法来解决 detachment 和 derailment 问题。这里提到的策略包括:a)将迄今为止访问过的所有有趣的不同状态添加到档案中;b)每次从档案中选择一个状态进行探索,首先回到(Go back)那个状态(不加探索),然后从那个状态继续探索(Explore),寻找新的状态(所以算法的名字叫「Go-Explore」)。
算法的更多细节参见原论文。
Go-Explore 的效果有多好?
为了测试 Go-Explore 的性能,研究者在 Montezuma’s Revenge 和 Pitfall 两款游戏上进行了测试。
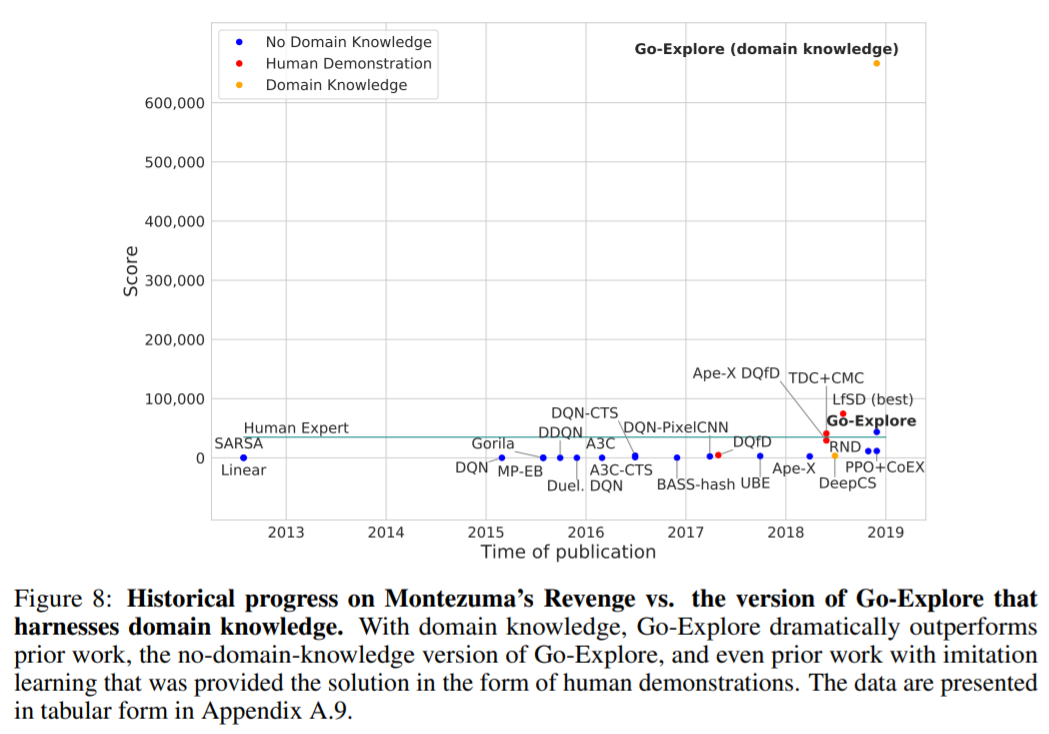
在 Montezuma’s Revenge 上的测试表明,Go-Explore 在不借助领域知识的前提下就可以超越人类得分(43,763 vs. 34,900),而且几乎达到了之前 SOTA 的四倍。
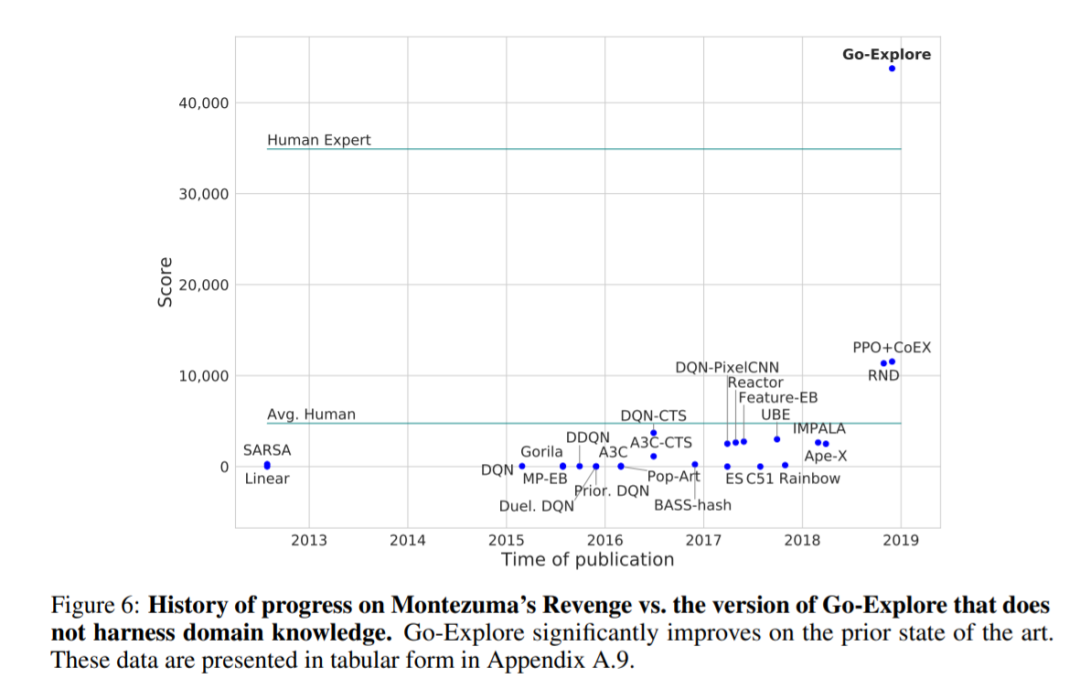
当然,Go-Explore 也可以轻松利用人类提供的领域知识,而且效果更加惊人,在 Montezuma’s Revenge 游戏中拿到了 650,000 的高分。它的最高分可以达到 1800 万,比人类得分高出一个数量级。作者表示,这一得分让 Go-Explore 达到了对「超人」水平的最严格定义。
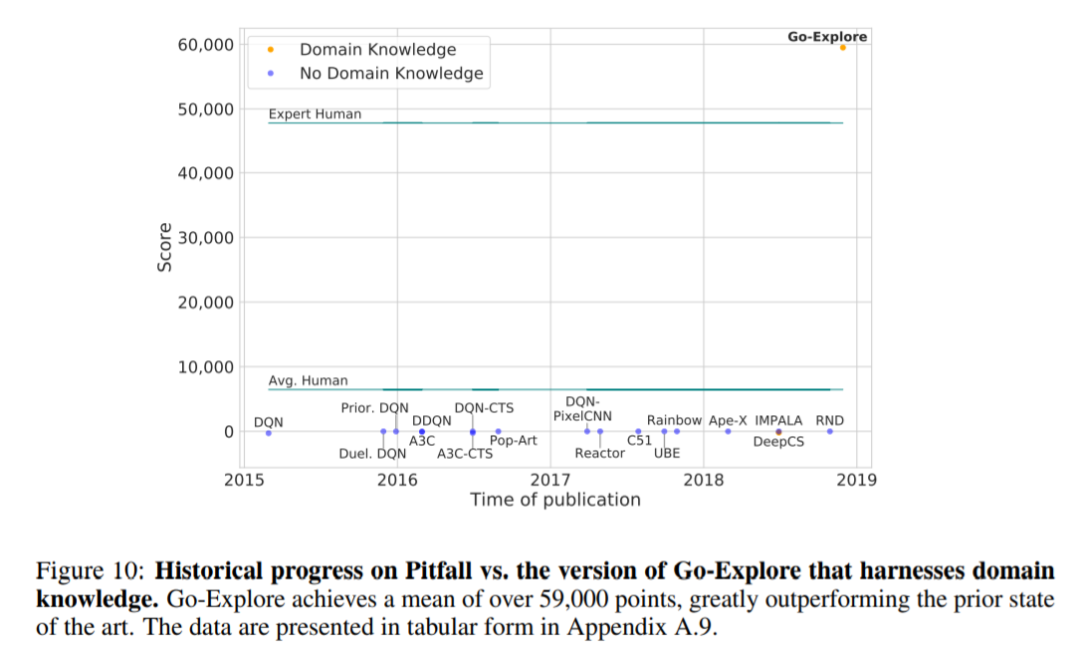
在 Pitfall 中,具有领域知识的 Go-Explore 是第一个得分超过 0 的算法。它的平均得分接近 60,000,超越了人类专家水平。
参考链接:https://zhuanlan.zhihu.com/p/58053501
https://www.zhihu.com/pin/1348290826187993088?utm_source
最佳技术实践:CV+联邦学习怎么搞?
FedVision是首个轻量级、模型可复用、架构可扩展的视觉横向联邦开源框架,基于Python 实现,内置PaddleFL/PaddleDetection插件,支持多种常用的视觉检测模型, 助力视觉联邦场景快速落地。
3月11日,微众银行联合飞桨带来实战公开课,聊聊FedVision实战与技术展望。