来源:量子位
够黄了吗?
够黄就能和谐了。
但平台不为所动,反手夹走了真正身体外露的“正确选项”:
挂图,实在是门玄学。

可在这个虽自但医的现代网络里,谁又能定义什么才是真正的GHS呢?
无法明确定义,后续的鉴定工作就无从开展。
欣赏人体艺术的精神需求,以及教育未成年人的现实需求,如何统一这两者,就成了一个亟待解决的问题。
为了大家的身心健康,我们有必要来探讨一下,如何才能科学有效地鉴黄。

人类鉴黄行不行?
评判一个人类鉴黄师行不行,首先要考虑知识渊博程度。
毕竟对于人类来说,鉴黄是个经验驱动型工作。
简单来说,就是要综合考虑一张图片中人物皮肤裸露、肢体动作和表情神态等特征,然后以个人经验来判断是否涉黄。

虽然鉴定结果难免会受个人喜好个体差异的影响,但总体来说,只有拥有长期高速驾驶的经验,才能对色情和性感拿捏自如。
好,再来康康鉴黄师们的身体够不够结实。
冷知识:我们常说的“鉴黄”,在国内更多是“内容审核”或“内容安全”部门的工作。
所以广大审核员们每天要面对的不仅是小黄图,还有互联网上时刻都在爆炸式增长的各类内容。

有调查显示,审核员们平均8个小时要看超过600部视频,听4000条语音,看上万张涉黄图片,处理近10亿条不良信息。

高强度、低工资和轮班制更是工作常态:
在这样的一杯茶一包烟,一万图片看一天的996生活下,有人的心态慢慢失衡。

也有人因为长期面对大量低俗、猎奇的垃圾信息,甚至是暴力、血腥的违法内容,而产生了心理阴影。
还有更多或是因为受够了每天几千条的黄暴图片选择转行,或是因为长时间的高强度压抑工作患上了抑郁症,甚至最终自杀的审核员。
 纪录片《网络审查员》剧照
纪录片《网络审查员》剧照那么对于不堪重负的人类鉴黄师,计算机能来帮帮忙吗?
当然可以!机器学习算法早在2018年就已经赶来助力了。

那能不能取代人类?
不能。
很遗憾,AI鉴黄在一开始,就遇到了重重困难。
AI鉴黄难在哪?
简单来说,AI鉴黄的过程是这样的:
最开始,由算法工程师给AI模型喂入大量已标注性感/色情的图片。
然后,AI会在图像数据的特征空间上学习一个决策面,将色情及性感两类数据划分开来。
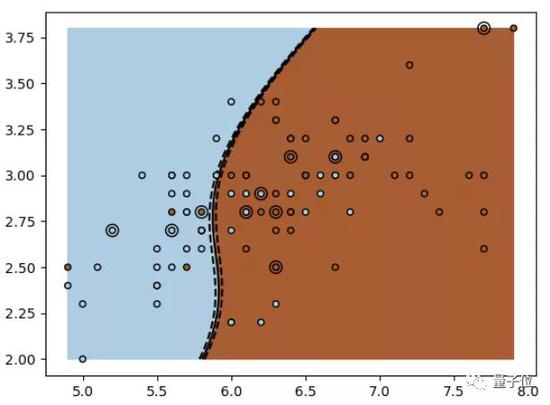 分类器完成决策面
分类器完成决策面完成这种“分类”,也即AI学习一个鉴黄分类函数的过程。
到最后,通过这一分类函数,使AI模型达到输入一张图片,就能正确输出一个“正常/色情”标签的效果。
听起来容易,但要让AI真正学会检测小黄图,却是难上加难。
第一个问题,就是目前没有行业统一的标准。
虽然可以参考《暂行规定》相关文件中提出的关于淫秽信息的标准,但对于色情内容,不同行业总是有自己的管控标准和接受程度。
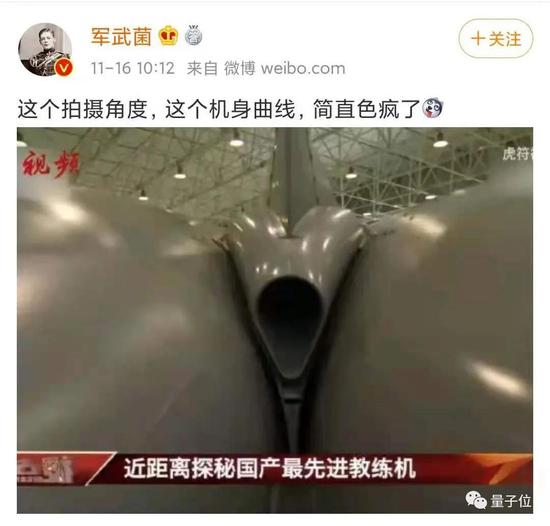
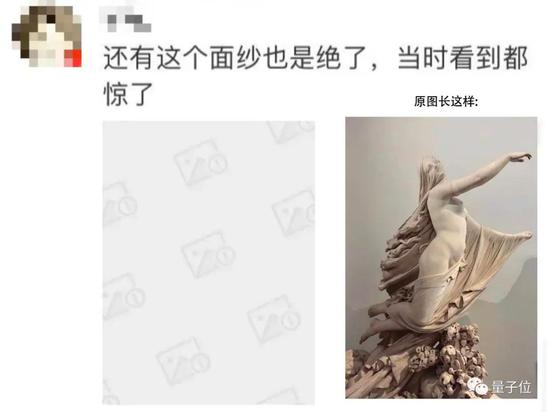
比如下面这四张图,它们在各自的领域可能是人体雕塑的艺术、学前科普的教育、沙雕网友的智慧,以及呃……GHS了,但又没有完全搞的神奇图片。

但换个领域,换个平台,可能就会:

毕竟,有时候人类可能都无法互相理解,AI就更不明白“什么才是真正的黄色了”。
碰到再勇一点的AI,不求准确,直接一个玄学挂图法就将所有可能一波带走。

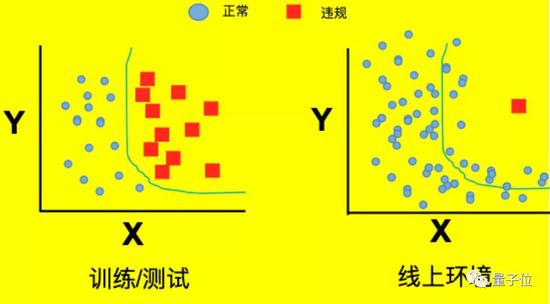
第二个难点,就是现实里样本含量极少的问题了。
不同于训练时期的大口喂图,现实里的色情内容,只是海量网络信息中极小的一部分。
所以实际上岗工作后,AI更可能面对的是“大海捞黄”的情况。
而当AI捞了半天小黄图出来,等待下一步的优化训练时,又会出现一个新的问题——
正确率越高,AI鉴黄师就更好吗?
不!
这种情况下,就算AI算法的正确率达到了99%,它也可能是不合格的鉴黄师!
因为当小黄图的比例在1%以下时,即使AI在测试中将所有图片都判断为“正常”,正确率也能轻松突破99%。
那么这时,AI鉴黄师哪怕完全不会鉴黄,也能达成“高正确率”的目标——
只需要全判断成“正常图片”就行!

这可比错夹了艺术作品严重多了。
如何让AI科学鉴黄?
先来解决最关键的问题——
如何让AI模型应对真实场景中,小黄图占比少的问题?
当然是给AI“鉴黄师”设个更合理的KPI。
AI“鉴黄师”需要明白,假阳性(正常图误判成小黄图)和假阴性(小黄图误判成正常图),其实是两种严重性不一样的错误!

为此,来自中科院的专家,提出了一种名为局部AUC优化的方法,用2个指标对AI模型进行约束。
AUC(Area Under Curve)全称曲线下面积,通常这里的曲线指ROC(Receiver Operating Characteristic Curve),即受试者工作特征曲线。
当我们画一条ROC曲线时,其Y轴为真阳性率(True Positive Rate, TPR),而X轴则为假阳性率(False Positive Rate, FPR),曲线为ROC,被包裹的蓝色面积就是AUC。
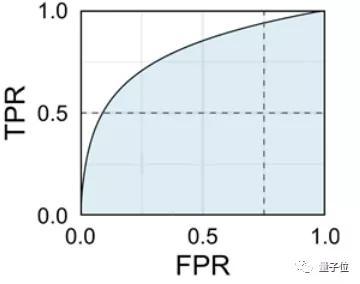
真阳性率:所有真·小黄图中,被正确判断成小黄图的比率;
假阳性率:所有真·正常图中,被错误判断成小黄图的比率。
如果AI“鉴黄师”胡乱分类(未经训练,随机分类),那么真阳性率和假阳性率基本持平。
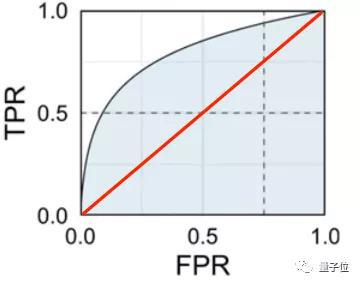
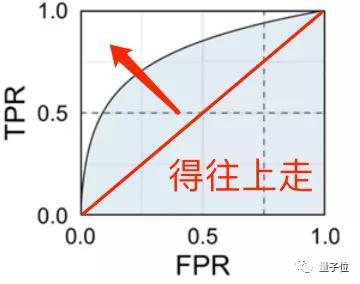
因此,有效的AI“鉴黄师”,真阳性率必须比假阳性率高,(最理想的状态是真阳性率为1,不出错),测出来的蓝色面积就更大,这也是它的KPI了。
而且为了让AI“鉴黄师”符合岗位要求,真阳性率(TPR)和假阳性率(FPR)还必须符合一定的阈值,就像下面这样:
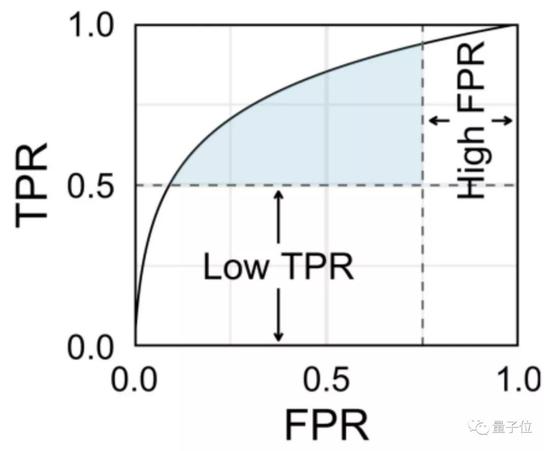
可别小看这个指标,它会让AI“鉴黄师”专注提升AUC,且不受到标签分布的影响。
这样的KPI,如何能让AI模型灵活handle不同行业的标准?
据团队介绍,这里的阈值并不是固定的,而同样会根据各行各业不同的标准,以及对风险召回率的要求和人工审核成本等因素进行调整的,最终实现风险召回和审核成本间的最佳平衡。
针对各行各业不同的认知标准,团队还会从数据集下手,对模型进行调整。
团队表示,不同场景下,对于色情风险防控的标准和认知确实有所不同。

为此,团队在做数据标记时,会用非常详细的标签对数据进行描述,也就是细粒度打标。用不同的训练集训练后,同一种AI模型,也能适应不同的行业标准了。
除此之外,在做数据标记时,也会有讲究。
如果只让一个人来对数据集进行标记,那么训练出来的AI模型肯定会带有个人偏好。为了避免这种情况,就得靠多人多次打标,用统计学对抗偏见。
这样,训练出来的AI“鉴黄师”,既能通过不同的训练集“培养特长”,也能根据合理的“KPI”激励自己做得更好。
真的减轻人类工作了吗?
减轻了!
据团队表示,还是降低了不少工作量的。
首先,AI鉴黄师在看过每张样本后,会给色情、性感等标签打个预测分,是更接近小黄图、还是更接近性感图。
根据这些分值,机器会自动对结果的可信度进行分层。
如果AI对自己很有自信——给的分数很高,那么直接输出结论就行。
这种情况下,就不需要人类鉴黄师再看一遍了。
但如果AI觉得水太深,把握不住,就还是交给人类鉴黄师来审核。

为了进一步减轻人类鉴黄师的工作量,AI鉴黄师还会“回看”自己打分低的那些图片:我到底为什么对它们拿不准?
然后,再对这些图片进行学习,进一步提升鉴黄水平。
团队介绍
这篇正经研究,目前已经登上了机器学习顶会ICML 2021,属于录用率仅3%的长文成果。

开发出这个指标的团队成员,分别来自中科院、信息安全国家重点实验室、深圳鹏城实验室等研究机构。
一作杨智勇,是中科院信息工程研究所信息安全国家重点实验室的博士生,目前已在在CCF-A类会议/期刊上发表论文20篇。
目前,这位小哥已经以一作身份,在TPAMI、ICML、NeurIPS、TIP、AAAI等顶会上发表过论文,其中ICML中的还是oral。

二作许倩倩,是中国科学院计算技术研究所副研究员。

当然,除了鉴黄以外,这个指标还能被用在更多的AI安全模型上。
据研究团队表示,除了鉴黄以外,这个指标也能应用到更多的安全场景中,包括过滤违规信息(例如诈骗广告)。










0517中国互联网游戏企业社会责任研究报告_00.png)