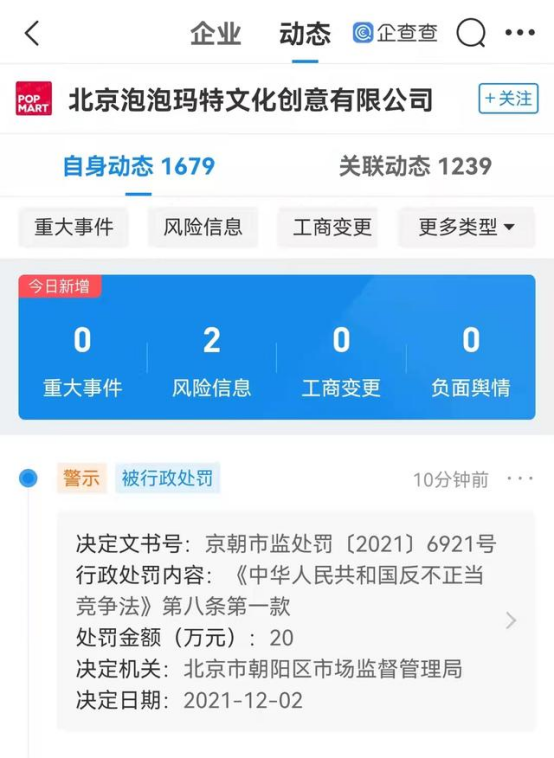
原标题:亚马逊云科技是如何造Serverless数据库的?
 作者 | 杨丽
作者 | 杨丽何为Serverless数据库?
简单来讲,就是基于Serverless架构下的数据库,无需用户创建实例,能够极快完成部署。用户使用数据库具备Serverless的使用特征,即按需计费,成本会极大地得以降低。
Serverless对于亚马逊云科技而言,也并非一个新事物,最早的产品如S3对象存储、SQS消息队列服务,就是Serverless形态的。事实上,业界对Serverless的认知,也是因AWS的另一款产品Lambda计算服务而带起来的。2014年,亚马逊云科技推出了Lambda,此后多年间,各家云供应商都开始了不同维度的实践和产品落地。
如今,在线化、数字化浪潮的席卷下,企业用户需求的逐渐成熟,使得Serverless与其他云服务及生态的配合更加紧密,进一步帮助企业降低使用云服务的成本。
先看一组客户案例:
嘉谊互娱是一家专注海外休闲游戏市场,集产品研发、运营和发行于一体的游戏公司。在此之前,嘉谊互娱面临的挑战是,爆款游戏带来的短期内全球玩家数量突增,导致传统服务器根本无法弹性扩容。如果单台虚拟机CPU负载过大,会有停机的风险。
为此,嘉谊互娱希望充分挖掘来自数百万玩家所积累的海量日志数据,从而发现业务数据背后的商业价值,为游戏服务的创新、玩家的体验与精准化营销提供支持。
Amazon Aurora Serverless数据库架构的上线,使得企业开发人员将大量精力集中在游戏开发和业务层面,而无需考虑底层数据库的管理和运维。
一项结果数据显示,嘉谊互娱的产品开发和测试周期从5-6个月缩减至3-4个月,游戏上线前的服务器配置测试由30分钟提升至秒级。
客户需要Serverless做什么?
为什么客户现在会越来越多地考虑使用Serverless构建应用?
过去大家的印象可能是主要通过Lambda构建一个IT自动化运维的程序,或数据预处理的程序。
但现如今,Serverless最近几年比较火,已经不是技术概念上火了,而是在真实的用户市场中,客户已经在通过Serverless在构建具体的应用。
关于这一点,亚马逊云科技大中华区产品部总经理顾凡告诉雷峰网,如今越来越多的客户会考虑应用Serverless,一是在于(供应商)技术的成熟度,二是对于客户自身对业务的弹性和不确定性也有一定的顾虑。
“一方面与供应商技术的成熟度相关,如计算相关的Lambda、存储、数据库等,都是基于Serverless的组件。
另一方面,客户对Serverless构建的应用场景会比原来更宽广,不仅仅是计算,而是横跨云计算服务场景里的多个层面。对于客户自身而言,他也不确定自己的业务会在某个确定的节点爆发起来,但他不希望闲置太多的IT成本。因此,业务的不确定性也需要厂商能够有充足、丰富经验的自动化弹性扩展功能来完成。”
总结来讲,企业需要根据自身的业务峰值去规划数据库的存储容量和计算资源,这势必会对业务的连续性带来一定的妥协和挑战。
通过将自建的数据库选择上云,已经帮助开发人员解决了运营上的挑战,如故障修复、补丁、软件升级等问题。但在Serverless模式下,当企业想要依据业务流量自动扩展数据库规模时,都能够做到自动设置扩展的相应规则。
理解到这里,就能基本明白Serverless与云计算本身所具备的属性是一致的,但相比1.0时代的云,Serverless架构下的计算、存储,将具备更加极致的弹性伸缩能力,将有效降低企业用户使用成本。
亚马逊的Serverless数据产品方法论
亚马逊云科技秉持专库专用的理念,针对不同的数据类型,利用目标构建数据库应用。目前已发布Amazon Aurora Serverless关系型数据库,Amazon DynamoDB键/值数据库,Amazon Timestream时序数据库,Amazon Keyspaces宽列数据库,Amazon QLDB分类账数据库等一系列Serverless数据库相关的产品矩阵。
针对键值型数据、时序型数据、文档类数据的存储,都可以Serverless的形式对外开放给企业客户,客户无需管理或配置服务器,可以按量进行缩放,真正为价值付费。
亚马逊云科技数据领域产品专家王晓野指出,
“Serverless背后所代表的与云计算的概念是非常接近的。也就是说,将云厂商多年对于大规模数据库运维、伸缩扩展的经验,以及团队整个技术能力最大化开放给客户,让客户受益。”
不久前,亚马逊云科技还发布了新一代Serverless数据库版本。
据官方资料介绍,Amazon Aurora Serverless V2,是基于Aurora的关系型数据库的Serverless模式。相比于上一版,即2018年发布的Amazon Aurora Serverless而言,能够实现瞬间扩展,更进一步将扩展能力发挥到极致。
“在不到一秒的时间里,就可以将几百个事务扩展到数万的级别;同时,扩展时每一次调整的增量都会以非常精细化的方式进行管理如果按照峰值进行数据库资源的规划,能够实现大约90%的成本节省。”
释放Serverless红利
时间回到2004年,亚马逊还是全面基于关系型数据库Oracle构建其电商业务,但团队意识到:亚马逊电商本身业务的增长,已经触碰到关系型数据库在数据体量支持上的上限瓶颈,而当时最常用的方式就是分库、分表。从那时开始,亚马逊的工程师就开始寻求一些方案,这些方案的答案最终被整理成为一篇paper。2007年亚马逊CTO沃纳·威格尔博士发表了一篇有关DynamoDB的论文。2012年,DynamoDB正式可用,发布之初就定义为Serverless架构。
如今,亚马逊将存储在7500个Oracle数据库中的75PB内部数据,迁移到多项亚马逊云科技数据库服务, 这些数据库支撑了亚马逊很多重要工作负载,涵盖客户档案、促销折扣管理、库存管理服务、分析型工作负载、缓存服务请求等。
不难发现,亚马逊自身的Serverless数据库实践,实际上是在不断提升开发、运维人员的效率,帮助他们投入到高价值生产环节中。
十五年前,亚马逊云科技掀开了云计算市场的面纱,以EC2成功席卷了企业级市场,而三年前它终于完成了去O,如今有着成熟的服务逻辑。
作为下一个云计算时代的核心产品Serverless,也因为领先者的远见卓识不断推进着进程。
(雷峰网(公众号:雷峰网))
雷峰网原创文章,未经授权禁止转载。详情见转载须知。