竞赛主页:http://picdataset.com/
美图公司联合北京航空航天大学、中国人民大学、在 ACM MM 2022 上举办第四届 Person in Context (PIC)竞赛。PIC 竞赛关注以人为中心的视频内容理解,本届比赛一共包括三个赛道,涵盖视频内容时序定位、视频描述生成,视频内容时空定位等跨模态任务。这些任务需要机器理解视频中人的动作、行为、交互,并能关联视觉和文本内容进行多模态推理,富有挑战性。
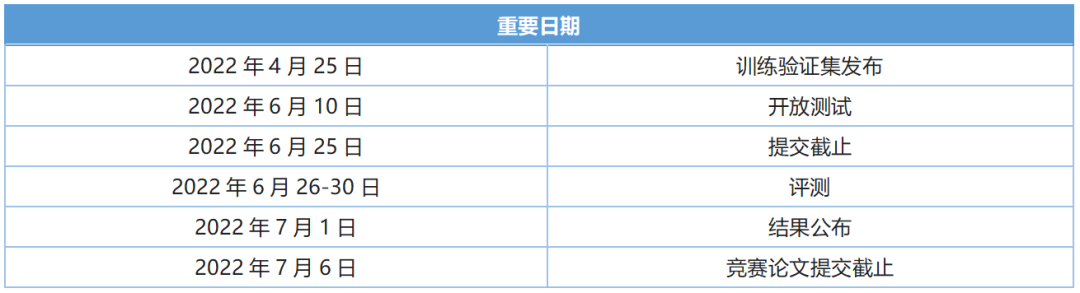
本届 PIC 竞赛同时提供了美妆场景和影视场景下的视频理解数据集 YouMakeup 以及 HC-STVG。重要日期如下所示:
三个独立赛道奖金:冠军:¥10,000 亚军:¥3,000 季军:¥2,000 (总计:¥45,000)
最佳论文奖金:¥5,000
【赛道一:美妆视频时域定位】
任务描述:给定一个美妆视频和一个文本步骤,该任务的目标是从视频中定位出步骤描述对应的时间段(包括起始点和结束点)。本赛道提供美妆场景下的 2800 个教学视频,视频长度由 15 秒到 1 小时不等,平均为 9 分钟,每个视频标注了一系列化妆步骤。本赛道具有两大挑战:1)多样的长视频标注;2)美妆领域细粒度的视觉变化。

竞赛主办者:金琴 (中国人民大学)、刘洛麒(美图公司)
主办单位:中国人民大学、美图公司
【赛道二:美妆视频密集描述生成】
任务描述:给定一个美妆教学视频,该任务需要自动定位和描述视频中的多个化妆步骤,输出预测步骤的起始位置和对应的文本描述。本赛道同样提供美妆场景下的 2800 个教学视频,视频长度由 15 秒到 1 小时不等,平均为 9 分钟。本赛道需要理解化妆步骤之间的细微差异,具有挑战性和趣味性。

竞赛主办者:金琴 (中国人民大学)、刘洛麒(美图公司)
主办单位:中国人民大学、美图公司
【赛道三:视频中的人物时空定位】
任务描述:视频中的人物时空定位任务输入为单个视频以及目标人物的描述语句,输出为目标在视频中对应描述语句的完整轨迹。本赛道提供不同电影场景的 16,000 段标注视频,每段标注视频由 20 秒左右的视频和与人相关的描述组成,输出是视频中描述所对应的开始帧和结束帧以及这段时间内描述目标的边界框。

竞赛主办者:刘偲 (北京航空航天大学)、刘洛麒(美图公司)、汤宗衡(北京航空航天大学)