来源:机器之心
作者:Chris Van Pelt
机器之心编译
机器之心编辑部
有工程师用 M1 版 Mac Mini 训练小架构深度学习模型,结果好像还可以。
众所周知,大多数 Mac 产品都是生产力工具,你甚至可以用它们训练神经网络。去年 11 月推出的,搭载 M1 芯片的 Mac 更是将这种生产力水平提到了一个新的高度。
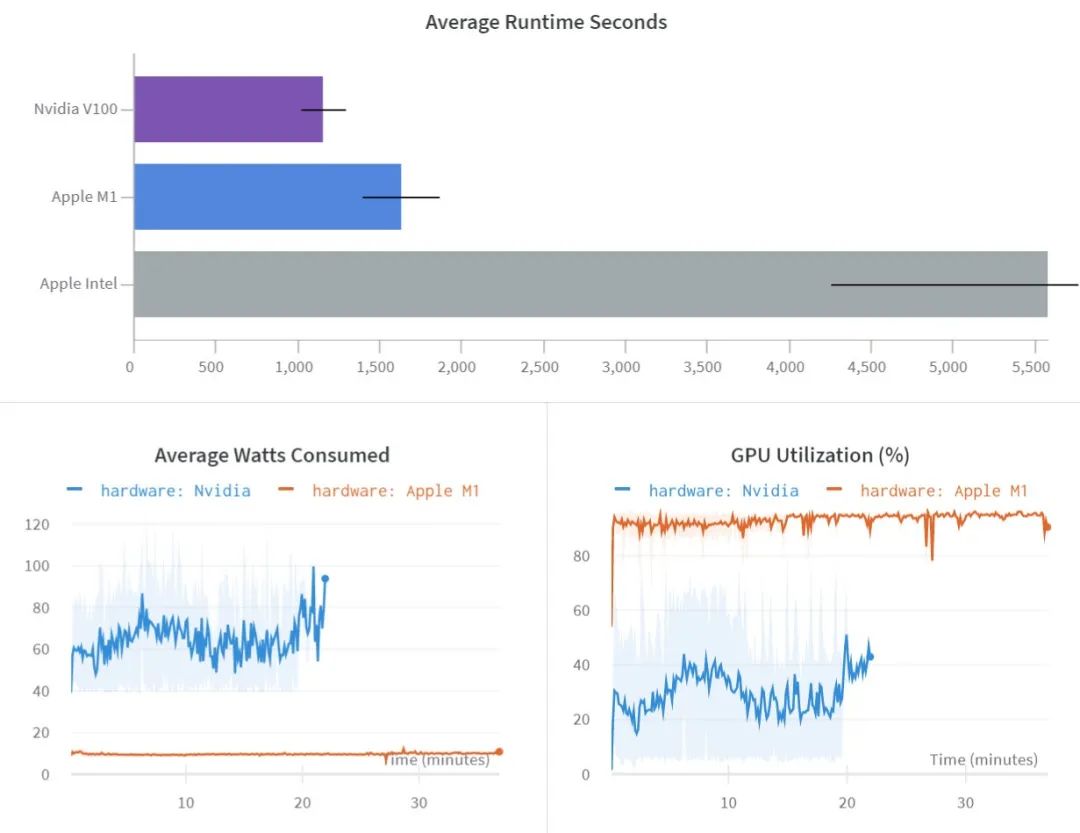
那么,如果拎出来和专业的比一下,M1 版的 Mac 在训练模型方面是个什么水平?为了解答这个疑问,最近有人将 M1 版的 Mac Mini 与 Nvidia V100 放到一起比了一下。
M1 版 Mac Mini 的售价最低是 5000 元左右。此前,国外知名硬件评测网站 anandtech 发布了对这款产品的详细测试,结果显示,在 CPU 性能测试中,M1 版 Mac Mini 的单线程和多线程都很优秀。在 GPU 性能测试中,它在多个基准测试中超越了之前的 Mac 系列产品,在某些情况下还能超越独显产品。
Nvidia V100 则是专业的 AI 训练卡,单精度浮点性能达到 15 TFLOPS,双精度浮点 7.5 TFLOPS,显存带宽 900GB/s,售价高达五位数。当然,你可以选择在 Colab 上租用。

评测者是「Weights and Biases」公司的联合创始人 Chris Van Pelt。Weights and Biases 简称 W&B,是一家致力于机器学习工具开发的公司。
为了进行这次测试,作者设计了 8 种不同的训练设置。结果显示,对于较小的架构和数据集,苹果 M1 的性能与 Nvidia V100 的差距并没有想象中那么大,而且在能效等方面表现要更为出色。
注意:本文中的图均为交互图,可以根据文末的参考链接查找原图。
测评方法
在测评中,作者用 Cifar 10 数据集训练了一个 MobileNetV2 架构的计算机视觉模型。V 100 的测评是在 colab 上进行的,16GB M1 Mac Mini 的训练所用框架来自苹果的 tensorflow_macos 库。他们使用 W&B Sweeps(一款超参数搜索和模型优化工具)来设置以下超参数:
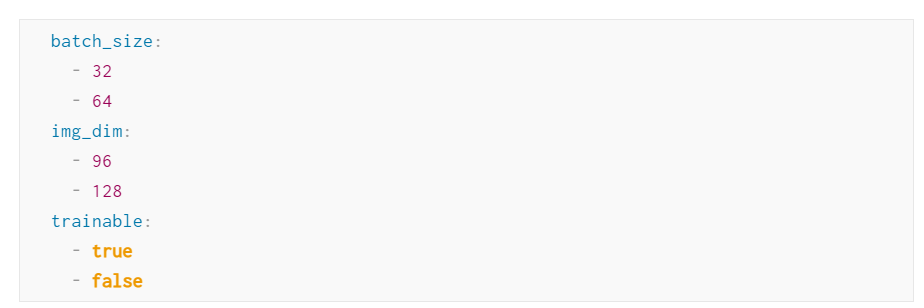
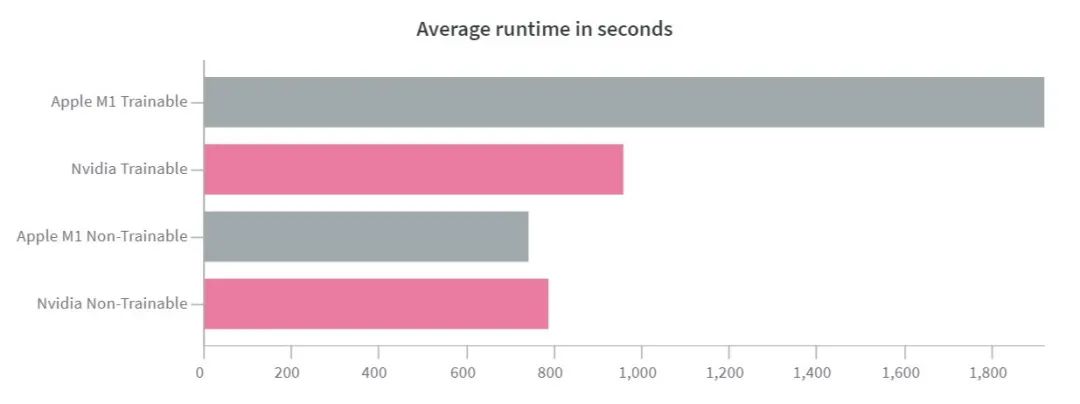
当「trainable」为「false」时,他们只训练网络中的最后一层。当「trainable」为「true」时,他们会更新 MobileNetV2 中的所有权重。
可以看到,当要训练的权重减少时,M1 的性能提升更为明显,这可能是因为 M1 的内存架构比较好。
能耗
本次测评所使用的 M1 Mac Mini 是 16GB 版本。在测试期间,作者表示没有听到风扇的声音,机箱也很凉。值得注意的是,要达到相同的计算量,M1 的能耗要小得多。不过两款芯片不是一个年代的产品:M1 是 5nm 制程的,2017 年推出的 V100 采用 12nm,虽然存在制程上的差距,但即使考虑到这点,后者的能耗也非常惊人,几乎达到了前者的 6 倍。

说明
设置 Mac Mini 来运行新的加速 Tensorflow 包并不容易。作者发现,获得各种需要编译的包最简单的方法是从 Miniconda 的 arm64 分支(https://conda-forge.org/blog/posts/2020-10-29-macos-arm64/)。默认情况下,这个 TensorFlow 库应该选择最佳加速路径,但作者却发现了一些段错误,除非利用以下代码明确告诉这个库使用 GPU。
from tensorflow.python.compiler.mlcompute import mlcompute
mlcompute.set_mlc_device(device_name="gpu")
作者表示,他选择 MobileNetV2 是为了迭代更快。当尝试 ResNet50 或其他更大的模型时,M1 和 V100 的差距逐渐拉大。当输入大于 196x196 维时,他在 M1 上也经历了段错误。
总的来说,这些入门级的 Mac 还只适合较小的架构。
在训练过程中,作者还观察到,在只训练网络最后一层时,M1 上的模型没有收敛,而 V100 上就不会出现这种情况。在进一步的实验中,作者通过降低学习率解决了这个问题。但是,目前仍不清楚 M1 Mac Mini 为何对学习率如此敏感。
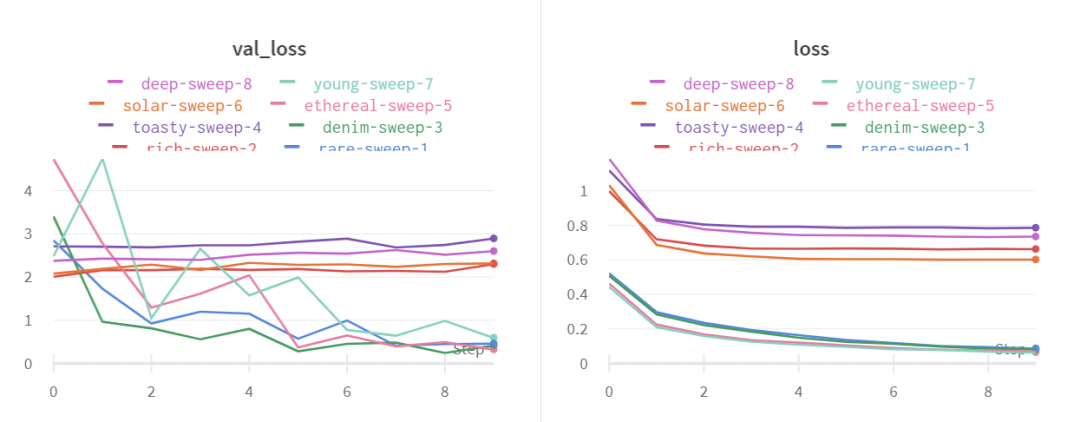
M1Mac Mini 的情况。
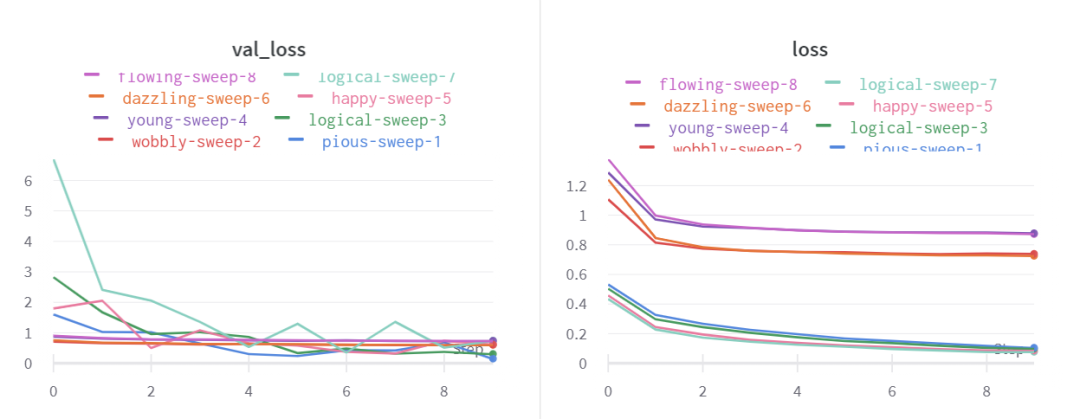
NvidiaV100 的情况。
结论
目前,苹果自研的 M 系列芯片还处在早期阶段,但初步评测看起来很有希望。当苹果发布拥有更多内核和 RAM 的 Pro 系列产品时,在苹果设备上训练机器学习模型会变得更加日常。
既然不少程序员都在使用 MacBook 写代码,那么在未来用苹果来跑深度学习是不是也应该变得流行起来呢?希望这是一个好的开始。
参考链接:https://wandb.ai/vanpelt/m1-benchmark/reports/Can-Apple-s-M1-help-you-train-models-faster-cheaper-than-NVIDIA-s-V100---VmlldzozNTkyMzg
Nature论文线上分享 |世界最快光子AI卷积加速器
世界最快光子AI卷积加速器登上Nature,该研究展示的是一种"光学神经形态处理器",其运行速度是以往任何处理器的1000多倍,该系统还能处理创纪录大小的超大规模图像——足以实现完整的面部图像识别,这是其他光学处理器一直无法完成的。
1月18日19:00,论文一作、莫纳什大学研究员徐兴元博士带来线上分享,详细介绍他们的工作以及光学芯片领域进展。
添加机器之心小助手(syncedai5),备注「光子」,进群一起看直播。