原标题:容联云发布AI Kernel 赋予企业AI应用自主建设能力

3月15日,经过多年技术沉淀与积累,依托于过硬的AI算法自研团队,容联云正式推出AI能力平台“AI Kernel(云梯)”。
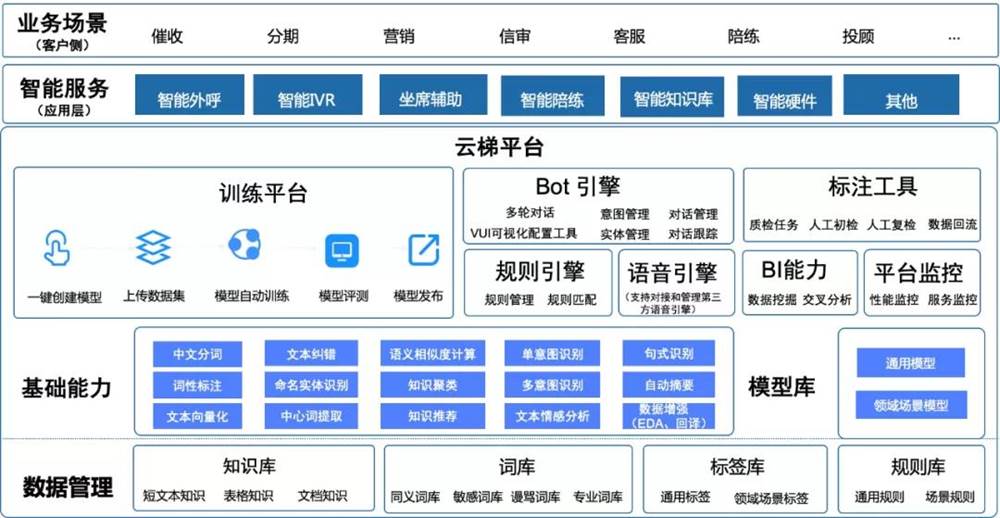
AI Kernel面向企业和集成开发商,提供基于自研算法封装的NLP原子能力、全生命周期管理的自学习平台与bot对话能能力等AI服务,帮助企业或集成开发商降低AI入门门槛,赋予其AI应用开发的自主建设能力,统筹管理企业AI能力和数据资源,实现智能化应用产品的快速落地。
云梯降低AI门槛助力企业向平台化建设转型
当下,智能化发展是大势所趋,企业在智能化进程中通常会面临许问题。首先,AI开发是复合型的系统工程,需要既精通AI又懂工程,既理解技术又理解业务的复合型人才实现融合创新。但在AI人才供给紧张的今天,企业较难招到也难留住合适的AI人才。同时,算法模型的构建及训练极其繁复、且算力要求高,技术瓶颈多,需要承担巨额的开发成本。
其次,企业传统的“烟囱式、项目制”开发模式,成本高、不易集成,过程重复,缺乏能力沉淀,缺少优化、协同、自动化辅助,业务响应缓慢。没有统一的数据访问渠道和统一的模型运行、监控平台,以及更新、维护机制,基础资源分散管理,未得到充分利用,造成浪费。
第三,随着企业AI应用的不断增加,各系统核心AI能力无法统一,大量宝贵的用户数据分散在不同系统无法复用。客户化AI应用需要依赖厂家进行定制开发,无法满足日益增长的业务对开发敏捷度的要求。
容联云AI Kernel打造更加包容、敏捷、高效的AI能力服务,降低企业AI入门门槛,帮助企业解决项目制、烟囱式AI建设存在的弊端,统筹管理NLP原子能力、模型和数据资源,同时提供可视化的线上模型训练工具,助力企业向平台化建设转型,更容易、更快速地搭建适合业务场景需求的人工智能应用。
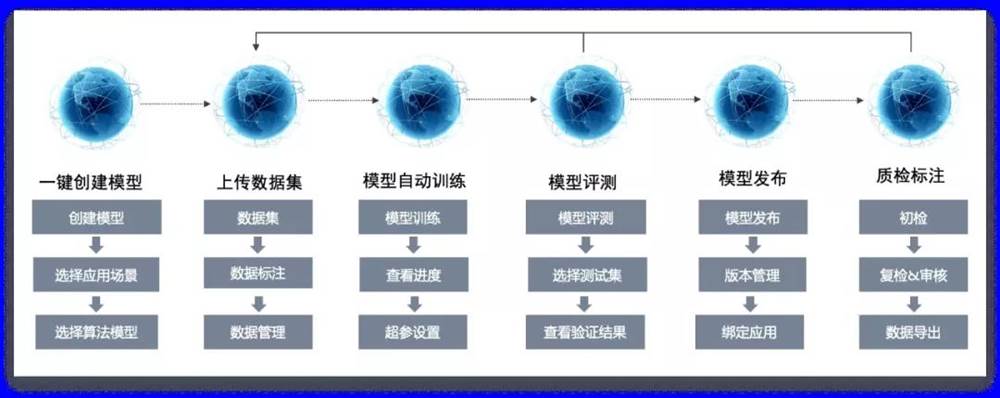
AI Kernel开放的自学习平台,打通线上数据集管理、模型训练、模型评测、模型发布等一体化流程。企业只需上传数据集,勾选平台已开放的各种算法组合,即可实现场景模型的自动训练与评测。同时,平台已沉淀和开放大量通用模型和领域模型,供平台租户直接使用,降低AI应用冷启环节的耗时。
此外,AI Kernel开放API/SDK,输出容联AI原子化能力。企业或者集成开发商可以通过调用容联AI原子能力灵活开发对话机器人、文本处理等智能化应用。开放NLP原子能力包含分词词性、文本纠错、中心词提取、语义相似度计算、意图识别、情感分息等能力。
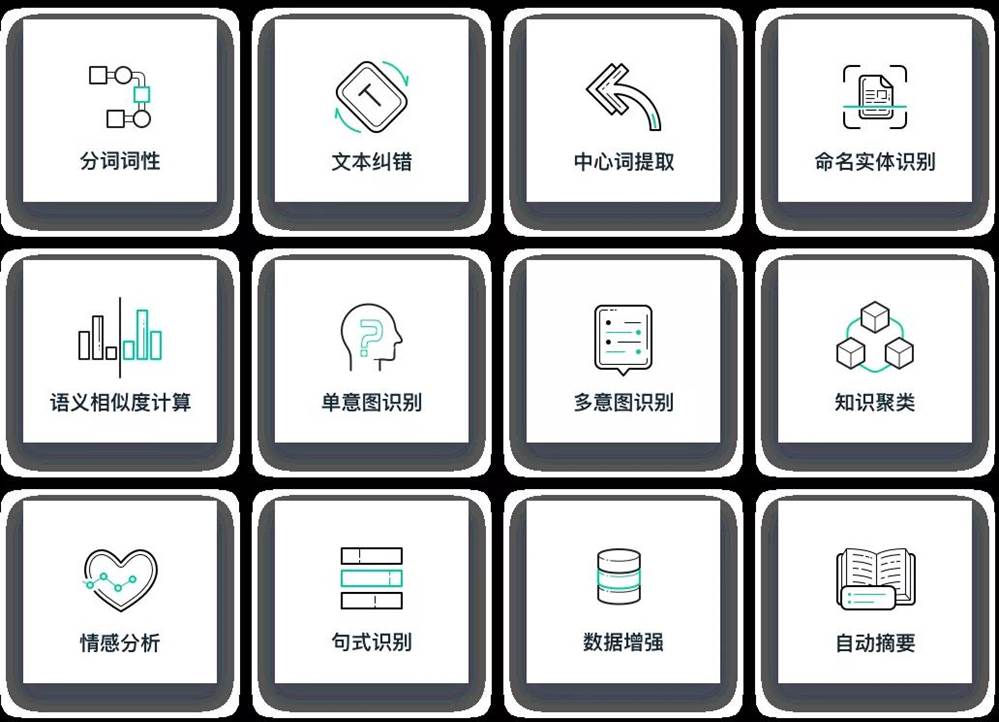
中文分词与词性标注:平台将自然语言文本切分成语义合理、完整的词汇序列,并为每个词汇赋予一个词性,如:动词、名词、介词等。
o 意图识别:基于规则模板+深度学习算法,平台可快速解析用户意图,支持单意图和多意图识别。
o 实体识别:基于bert+bilstm+crf模型,实时自动抽取文本中具有特定意义的实体,如:人名、地名、机构名等。
o 文本纠错:自动更正文本中存在错误的字段,降低由于文本错误带来的语义解析不准或阅读障碍。
o 语义相似度计算:基于海量数据训练的网络模型,计算句子之间的相似度,实现高精度语义相似度比对。
o 中心词提取:基于BERT多任务训练和MMR重排算法,自动提取文本核心关键词语。
o 知识聚类:对大量未标注数据进行自动聚类,实现快速创建业务场景和知识扩充。
o 情感分析:对文本话术情感的积极性、消极性等进行精准的意见挖掘和倾向性分析。
o 自动摘要:自动预测文本片段中的关键信息生成文本摘要,提炼文本主题。
o 句式识别:基于深度学习文本分类模型,支持对句子句式进行识别,如:肯定句、否定句、疑问句、感叹句等。
o 数据增强:借助EDA、回译等手段,实现有限数据样本的自动扩写,帮助解决文本数据量不足或不均衡问题。
AI能力平台为企业数字化提供有力支撑
容联AI Kernel将企业标准化数据统一管理,方便复用和沉淀,统一的服务接口规范,支持服务动态编排组合。可视化集数据-训练-评测-发布一体化的平台,支持14项训练超参设置,采用混淆矩阵4指标评测模型效果,支持自动拆分评测集,训练-评测过程完全自动化进行,无须人工干预,评测完成邮件通知,支持多任务并行训练,集中管理历史数据/历史模型版本,方便查询回退。在统一资源管控(计算资源、存储资源等),支持资源弹性调度,确保资源得到合理利用,避免资源浪费的同时,AI Kernel支持私有云、本地化部署方式。
目前,平台已服务于金融、银行、保险、证券、石化、汽车等诸多领域的智能营销、智能催收、智能服务、智能质检等应用场景。
作为容联云AI能力的出口之一,AI Kernel加速了企业AI开发应用创新的速度,助力企业释放AI的价值,为企业数字化提供有力的支撑。