来源:机器之心
编辑:陈萍
有人将快速可微分排序算法打包实现,性能还不错。谷歌去年年初在论文《Fast Differentiable Sorting and Ranking》中,重磅推出了首个具有 O(nlogn) 时间复杂度、O(n) 空间复杂度可微分排序算法,速度比现有方法快出一个数量级!
近日,有人在 GitHub 上开源了一个项目,通过软件包的形式实现了快速可微分排序和排名,上线几天,收获 300 + 星。
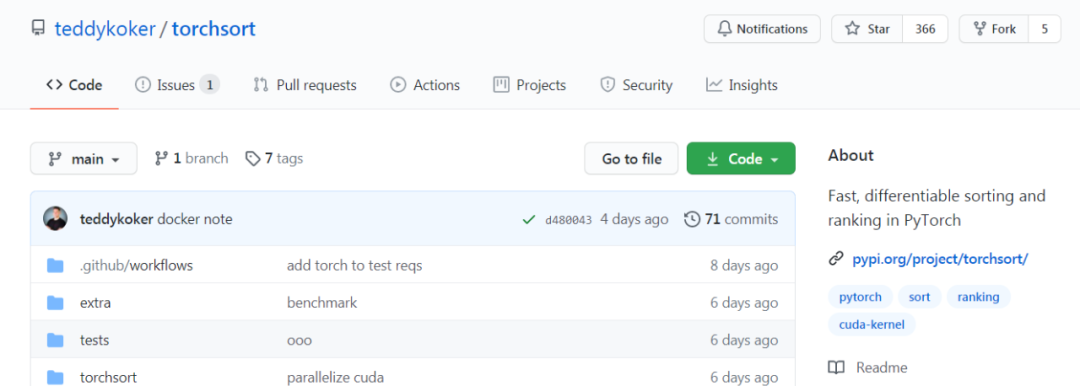
项目地址:https://github.com/teddykoker/torchsort
《Fast Differentiable Sorting and Ranking》论文地址:https://arxiv.org/pdf/2002.08871.pdf
Torchsort
Torchsort 实现了 Blondel 等人提出的快速可微分排序和排名(Fast Differentiable Sorting and Ranking),是基于纯 PyTorch 实现的。大部分代码是在项目「google-research/fast-soft-sort」中的原始 Numpy 实现复制而来,并配有自定义 C ++ 和 CUDA 内核以实现快速性能。
Torchsort 安装方式非常简单,采用常用的 pip 安装即可,安装代码如下:
pip install torchsort
如果你想构建 CUDA 扩展,你需要安装 CUDA 工具链。如果你想在没有 CUDA 运行环境中构建如 docker 的应用,在安装前需要导出环境变量「TORCH_CUDA_ARCH_LIST="Pascal;Volta;Turing"」。
使用方法
torchsort 有两个函数:soft_rank 和 soft_sort,每个函数都有参数 regularization (l2 或 kl) (正则化函数)和 regularization_strength(标量值)。每个都将对二维张量的最后一个维度进行排序,准确率取决于正则化强度:
importtorch
importtorchsort
x = torch.tensor([[8, 0, 5, 3, 2, 1, 6, 7, 9]])
torchsort.soft_sort(x,regularization_strength=1.0)
# tensor([[0.5556, 1.5556, 2.5556, 3.5556, 4.5556, 5.5556, 6.5556, 7.5556, 8.5556]])
torchsort.soft_sort(x,regularization_strength=0.1)
# tensor([[-0., 1., 2., 3., 5., 6., 7., 8., 9.]])
torchsort.soft_rank(x)
# tensor([[8., 1., 5., 4., 3., 2., 6., 7., 9.]])
这两个操作都是完全可微的,在 CPU 或 GPU 的实现方式如下:
x = torch.tensor([[8., 0., 5., 3., 2., 1., 6., 7., 9.]], requires_grad=True).cuda()
y = torchsort.soft_sort(x)
torch.autograd.grad(y[0, 0], x)
# (tensor([[0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111]],
# device='cuda:0'),)
示例展示
斯皮尔曼等级系数是用于测量两个变量之间单调相关性的非常有用的指标。我们可以使用 Torchsort 来创建可微的斯皮尔曼等级系数函数,以便可以直接针对该指标优化模型:
importtorch
importtorchsort
defspearmanr(pred, target, **kw):
pred = torchsort.soft_rank(pred, **kw)
target = torchsort.soft_rank(target, **kw)
pred = pred - pred.mean()
pred = pred / pred.norm()
target = target - target.mean()
target = target / target.norm()
return(pred * target).sum()
pred = torch.tensor([[1., 2., 3., 4., 5.]], requires_grad=True)
target = torch.tensor([[5., 6., 7., 8., 7.]])
spearman = spearmanr(pred, target)
# tensor(0.8321)
torch.autograd.grad(spearman,pred)
# (tensor([[-5.5470e-02, 2.9802e-09, 5.5470e-02, 1.1094e-01, -1.1094e-01]]),)
基准
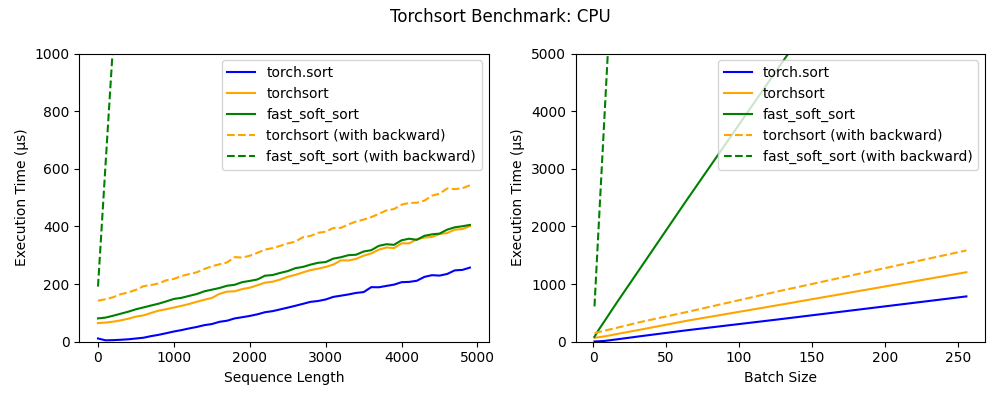
torchsort 和 fast_soft_sort 这两个操作的时间复杂度为 O(n log n),与内置 torch.sort 相比,每个操作都具有一些额外的开销。Numba JIT 的批处理大小为 1(请参见左图),fast_soft_sort 的前向传递与 Torchsort CPU 内核的性能大致相同,但是其后向传递仍然依赖于某些 Python 代码,这极大地降低了其性能。
此外,torchsort 内核支持批处理,随着批处理大小的增加,会产生比 fast_soft_sort 更好的性能。

torchsort CUDA 内核在序列长度低于 2000 时表现出色,并且可以扩展到非常大的 batch。在未来,CUDA 内核可能会进一步优化,以达到接近内置的 torch.sort 的性能。
建新·见智 —— 2021亚马逊云科技 AI 在线大会
4月22日 14:00 - 18:00
大会包括主题演讲和六大分会场。内容涵盖亚马逊机器学习实践揭秘、人工智能赋能企业数字化转型、大规模机器学习实现之道、AI 服务助力互联网快速创新、开源开放与前沿趋势、合作共赢的智能生态等诸多话题。
亚马逊云科技技术专家以及各个行业合作伙伴将现身说法,讲解 AI/ML 在实现组织高效运行过程中的巨大作用。每个热爱技术创新的 AI/ML 的爱好者及实践者都不容错过。
©THEEND
转载请联系本公众号获得授权