原标题:昆仑芯x飞桨:智能核芯,生态共赢
近日,由深度学技术及应用国家工程实验室与百度联合主办的「WAVE SUMMIT+2021深度学开发者峰会」在上海成功举办。WAVE SUMMIT是中国深度学领域每年两次的科技盛会,WAVE SUMMIT+2021是今年下半年的AI生态主题专场。
昆仑芯科技资深研发工程师韩金宸受邀出席“智能核芯,生态共赢”论坛,并在现场进行“昆仑芯:让计算更智能”主题分享。关于昆仑芯科技团队历史、技术优势、产品进展、落地情况及未来展望,此次分享均有详细介绍。
 昆仑芯科技资深研发工程师韩金宸
昆仑芯科技资深研发工程师韩金宸以下内容来源于现场速记:
大家好,我是来自昆仑芯科技的韩金宸,非常开心,今天能给在这里给大家介绍一下公司和我们的产品。
昆仑芯是一个很年轻的公司,今年才刚成立,目前还是一个规模不大的创业公司。
但我们的团队有很长的历史,前身是百度智能芯片及架构部,由于看到了芯片,对整个AI产业的重要性,因此特意把我们部门spinoff出来,成为一个独立的公司。
我们公司的愿景是“成为划时代、全球领先的智能计算公司。”
结合计算设备发展的历史,我们可以清楚地看到,未来,算力发展最快、最集中的方向,一定是AI的workload,而AI算力的发展,需要非常多的投入和很强的技术实力,昆仑芯科技就致力于在这个赛道上成为全球的领先者。
芯往事
我们团队的历史最早可以追溯到2011年,当时深度学才刚刚开始热起来,那时候我们公司的CEO欧阳剑就认准了「用硬件加速AI计算」这一方向,启动了FPGA AI加速器项目。

15年,我们的FPGA产品在百度内部已经部署超过5000片,用来支撑百度的核心任务,17年的时候,更是部署了超过12000片。
到了18年的时候,我们正式启动了ASIC项目,也就是第一代昆仑芯,2020年,第一代昆仑芯在百度内部大规模部署。
而今年呢,我们第二代产品也成功量产。
芯产品
很多朋友在和我们,刚开始接触的时候,都会有这样的疑问,昆仑芯的产品究竟是什么?与大家所熟悉的,传统的CPU,尤其是GPU,他们的差别在哪里?
这个问题其实并不容易回答,因为大家的架构其实都在不停地进化与改变,随着计算任务的演变,随着深度学的兴起,传统CPU、GPU也在不断添加新的功能,来满足客户对AI的需求。
正如GPU在近几代产品中,加入了TensorCore,它其实是一个AI计算单元,是用来加速深度学,张量计算的部分的。那么在加入TensorCore之后,GPU就形成了这样一种,通用Core为主,TensorCore为辅,这样融合的架构。
通用AI处理器,其实也是类似的。不过我们是从另一个角度出发的,我们先构建了一套硬件流水线,用来进行深度学计算,然后在此基础上,加入通用计算核,来提升我们处理器的灵活性。
那么最终呢,大家其实都走向了融合架构的方向,只是设计上的取舍不同,最终在不同的场景下,大家的收益不尽相同。
这一页呢,就展示了我们第二代昆仑芯的XPU架构。
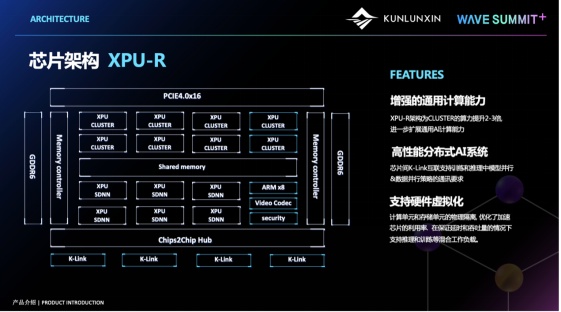 XPU架构图
XPU架构图其中SDNN,是我们XPU架构中的AI计算单元,他可以非常快速的处理深度学张量计算的流水线,而XPU Cluster则是一个通用计算单元,用来处理深度学通用的、非张量的部分。
因此使用了这种SDNN + Cluster的融合的架构呢,我们既可以提供很强的计算能力,又可以保证较好的通用性。
我们在第二代产品中使用了GDDR6,它可以在控制成本的同时,提供很好的访存带宽,我们是国内第一个使用GDDR6内存的产品,还是比较先进的。
此外,随着模型的规模增加,分布式计算已经成为了一个核心诉求,不论是分布式训练,还是分布式推理,都要求芯片能够提供很强的互联通信的能力,因此大家可以看到,我们在第二代昆仑芯中加入了Chip2Chip的能力,用来满足AI中并行的需求。
昆仑芯2代也加入了硬件虚拟化支持,因为我们看到,不管是在云,还是互联网的很多场景中,大家会希望能够尽可能的提升计算卡的利用率,同时能,又要保证服务的质量,硬件虚拟化,所提供的资源硬隔离能力,就很好的解决了这一问题。
另外我们还在第二代产品中加入了编解码的支持,在很多范视觉类的业务中,解码能力都是必需品。
这个是我们昆仑芯软件的一个架构,在系统层,除了基础的驱动程序,我们还有K8S套件,可以很方便的,以容器化的方式,对我们的计算卡进行管理。
 昆仑芯软件架构图
昆仑芯软件架构图开发套件方面,我们提供了自研的高性能算子库XDNN,可以满足绝大多数模型的计算需求,针对一些自研模型的客户,我们也提供XTDK编译器及相关开发套件。此外,我们还提供了高性能通讯库XCCL,和一个图像、视频处理加速引擎。
在框架方面,由于我们是百度内部孵化出来的团队,我们与Paddle团队保持着非常紧密的合作关系,Paddle原生对昆仑芯片提供的完整的支持,包括模型的训练、推理、部署等。基于PaddlePaddle使用昆仑芯产品也是非常方便的。
对于其他第三方的框架,如tensorflow、pytorch,我们则通过自研的 XTCL 图编译引擎,支持模型的推理与部署。
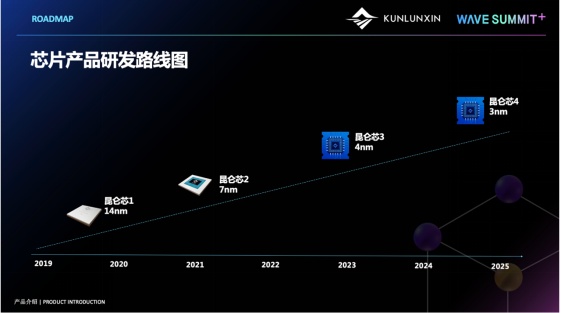 路线图
路线图我们第一代昆仑芯使用14nm制程,INT16算力可达64TOPS,使用的是HBM内存颗粒。产品有两个形态,分别是半高半长的K100,提供一半的算力,和全高全长的K200,提供全部的算力。
第二代昆仑芯,使用7nm制程,可以提供128TOPS的INT16算力,目前有3个产品形态,分别是全高全长的PCI-E计算卡R200,OAM计算模块R300,和服务器基板R480
这个就是我们第二代昆仑芯封装后的样子,第二代昆仑芯使用16路PCI-E4接口,设计功耗为150W,算力刚才也提到过,是128TOPS。
 昆仑芯2代封装图
昆仑芯2代封装图R200是目前我们主推的推理产品,这里是它的一些详细的参数信息,显存大小为16GB,带宽可达到512GB每秒,编解码的话,可以支持108路1080p 30fps的解码能力,和27路的编码能力
R300是基于OCP标准制作的一个OAM模块,和R200相比,R300计算能力是完全一样的,不同是提供了32GB的存储
R480是我们主要面向训练场景推出的一个产品,它封装了8个R300,通过主板上预置的走线使得8个R300之间形成一个,高效的,互联互通的,通信网络。整体上可以提供差不多 1P 的 FP16 的算力。
我们R200和市场同类产品在一些典型模型上进行实测性能对比,整体上我们可以说达到了业界领先水平。
芯进展
说了这么多产品,大家其实一定非常关心我们昆仑芯实际应用与落地的情况,毕竟,有了实际的应用,才算是真正为客户创造了价值。
首先,我们作为一个从百度内部孵化出来的公司,搜索与广告,一定是我们最重要的场景。这些场景,他们的技术原理都是比较类似的,其本质上,在用户和目标之间计算一个相关性,然后根据相关性排序,并返回相关性最高的结果。对百度这样一个量级的公司来讲,我们有10亿级别的用户,与万亿级别的目标,那么在他们之间算相关性,计算量大家可想而知,同时,由于不停有新的数据产生,模型还要在线上实时的进行重训练与更新。此外,这些都是实时业务,对延迟与稳定性的要求也极高。
在百度内部,我们有大约20000张昆仑芯,在支撑着百度这些核心业务,整体上来看,相比同级别的原有方案,昆仑芯可以达到1/3的TCO收益。
智能城市也是目前对AI算力需求比较大的一个场景,这部分大家应该都比较熟悉,我就不再赘述,在这个领域里,我们昆仑芯在国内几个城市里,也有不少的部署量。
工业视觉是近几年比较新兴的一个方向,刚才我们百度的副总裁吴甜,在主论坛的分享也提到了ai在工业质检方面的应用。
在药瓶生产这个case里,对算力的要求还不太大,但在一些精密零件的生产线上,但随着这个质检精度要求的提升,生产节奏的加快,对算力的要求会越来越高。
我们在这个方向上也是落地了蛮多客户的。
我们昆仑芯的产品,也是在百度内部、外部都大规模部署过的,是经历过大规模的实战考验的。
总结一下,昆仑芯在AI的各个领域都累积了多种解决方案,也达到了较好的一个收益。我们底层适配了多种处理器架构与国产操作系统,希望能够为国内人工智能事业做出自己的贡献。