C114讯 北京时间5月11日消息(余予)近期量子计算的一个主要挑战是可用量子位的数量有限。假设我们要运行一个由400个量子比特组成的电路,但我们只有100个量子比特可用的设备。我们该做什么?
在过去的一年中,IBM Quantum团队已经开始研究一种叫做“电路编织”的计算方法。电路编织技术使我们能够将大型量子电路划分为适合较小设备的子电路,并结合经典模拟将结果“编织”在一起,以实现目标答案。成本是模拟开销,它会随着编织门的数量呈指数级增长。
在未来,电路编织将很重要。我们的量子硬件开发团队专注于通过经典连接较小的处理器,然后通过量子链路进行扩展。基于这种计划好的硬件架构,在不久的将来,当我们在经典并行量子处理器上运行问题时,电路编织将很有用。提高可用量子比特数量的技术也将在未来很长一段时间内发挥作用。
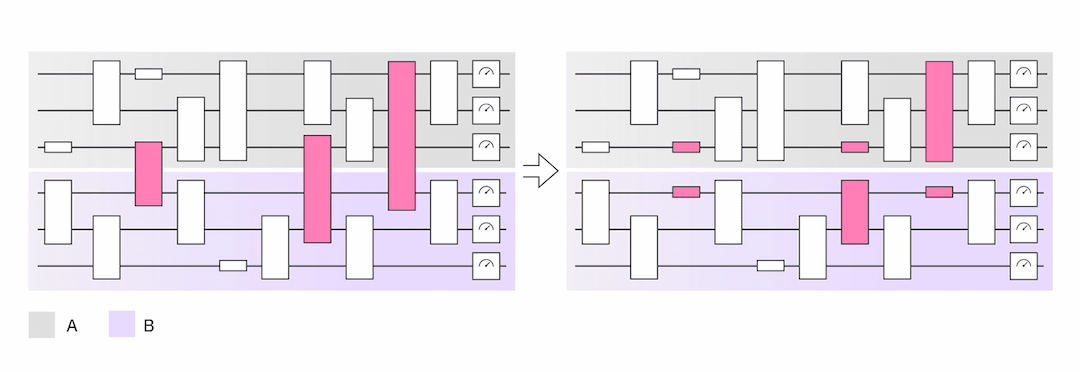 图1:电路编织示例:左侧作用于A⊗B的非本地电路可以模拟为仅作用于右侧A或B的本地电路,然后进行经典后处理。
图1:电路编织示例:左侧作用于A⊗B的非本地电路可以模拟为仅作用于右侧A或B的本地电路,然后进行经典后处理。但首先,我们的团队需要了解这些方法可以提供多少好处,特别是当我们知道模拟开销随着这些子电路之间的门数量呈指数级增长时。
我们目前正在研究本地量子计算机之间的经典通信是否有助于降低模拟开销——正如您可能在一对经典并行化的IBM Quantum “Heron”处理器上看到的那样。具体来说,我们通过一种以前在误差缓解和经典模拟算法领域受到关注的方法,即准概率模拟技术,实现了电路编织。
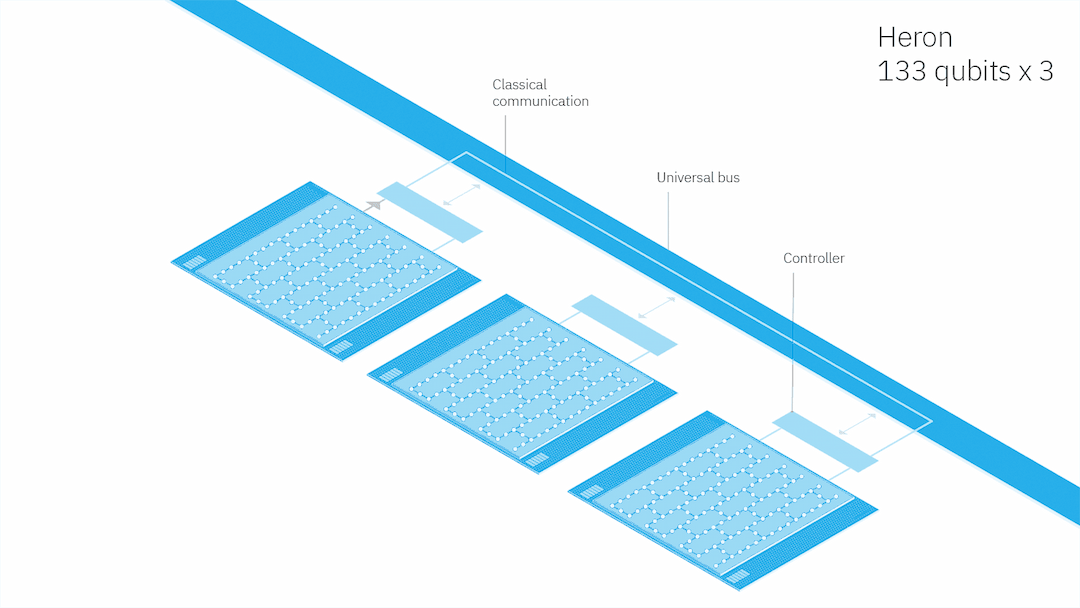 计划于2023年推出的133量子位“Heron”处理器
计划于2023年推出的133量子位“Heron”处理器我们考虑三种设置来模拟具有本地操作的非本地电路。首先,两台量子计算机只能在它们的子电路上运行它们自己的本地操作,它们之间没有通信。在第二种情况种,两台计算机可以实现这些本地操作,增加了向一个方向发送经典信息的能力——从A到B,但不能从B到A。第三种情况种,两台量子计算机可以运行它们自己的本地量子操作,并在它们之间向任一方向发送经典信息。
在本地和单向经典通信设置中,不一定需要两台独立的量子计算机。相反,可以在同一设备上按顺序运行两个子电路。然后可以通过经典地存储从A和B发送的比特来模拟单向设置中的经典通信。
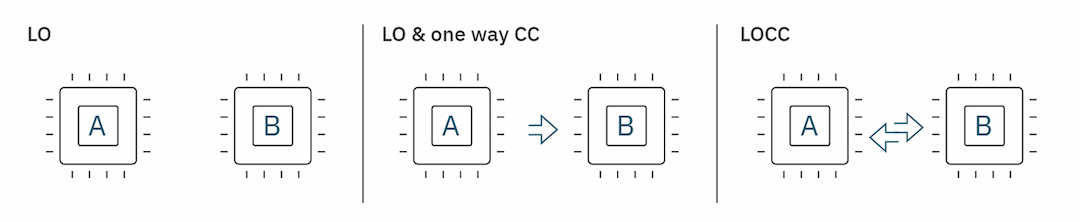
图2:考虑运行非本地操作的三个场景的图形概述。LO指本地操作;LO & one way CC指本地操作和one way经典通信;LOCC 指本地操作和经典通信。
相比之下,双向通信设置需要两台量子计算机在两个方向上交换经典信息。我们表明,对于基于准概率模拟的电路编织,当应用于具有相同非本地门的多个实例的电路时,上述三种设置都具有不同的采样开销。
我们在arXiv上得到的结果表明,双向通信可以大大减少模拟开销。对于包含连接每个子电路的n个CNOT门的电路,子电路之间的经典信息交换的结合将模拟开销从O(9n) 减少到O(4n)——这在实践中是一个显著的减少。对于给定的固定模拟开销,它允许我们切割更多的CNOT门,即纠缠量子比特的门。
在技术层面上,我们的结果基于这样的见解,即同时在本地准备两个最大纠缠态(称为Bell pairs)比在本地准备单个Bell pair两次效率更高。原因是,对于联合准备,我们可以利用本地子系统之间的纠缠,而如果我们分别准备两个Bell pairs,这是不可能的。利用门隐形传态的想法,我们可以在本地操作和经典通信下将Bell pair转换为CNOT门。
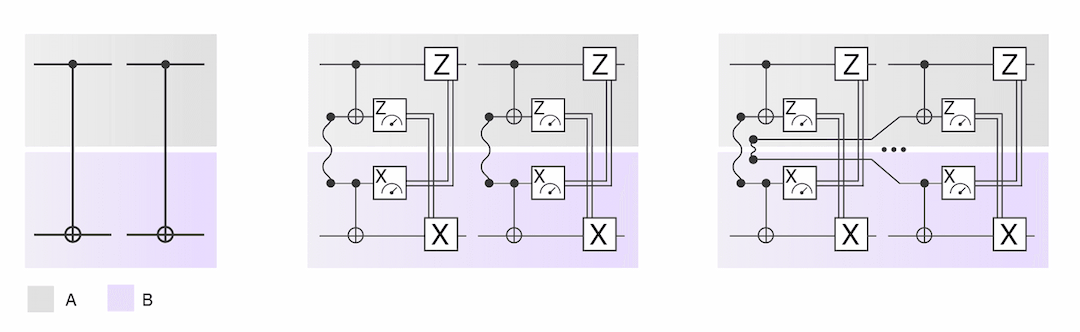
图3:如何通过门传送在LOCC设置中实现两个CNOT门的图形说明。通过同时生成两个Bell pairs(而不是生成两次单个Bell pairs),我们可以减少总的模拟开销。
我们的结果表明,当执行超过每个量子设备单独拥有的量子比特数的大型计算时,本地分离的量子计算机之间的经典通信是有益的。
按照IBM最新的路线图,这些结果可能有助于减少未来架构中的模拟开销,因为它促进了单个量子芯片与经典通信链路的连接。