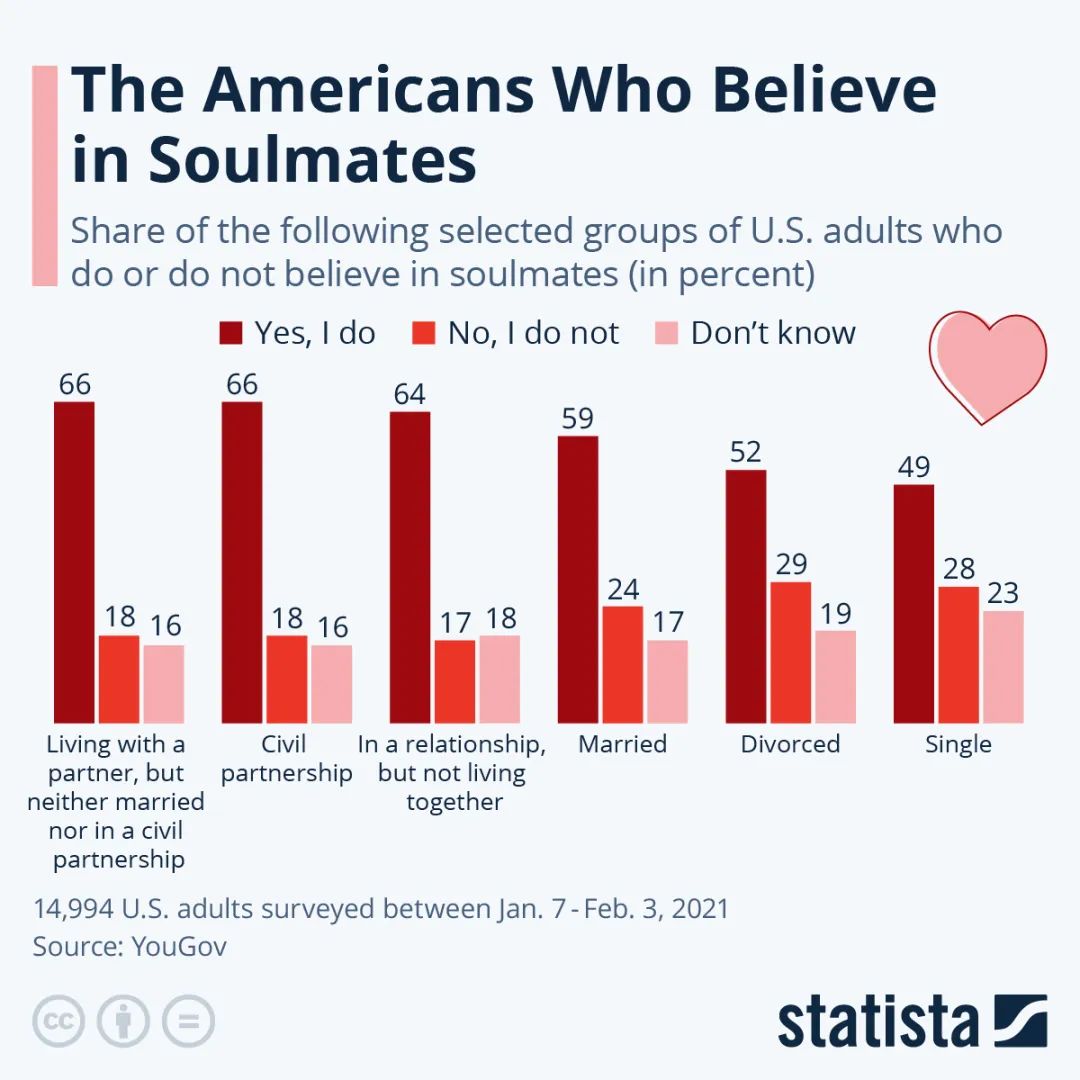
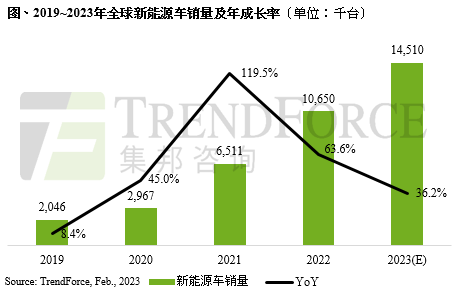
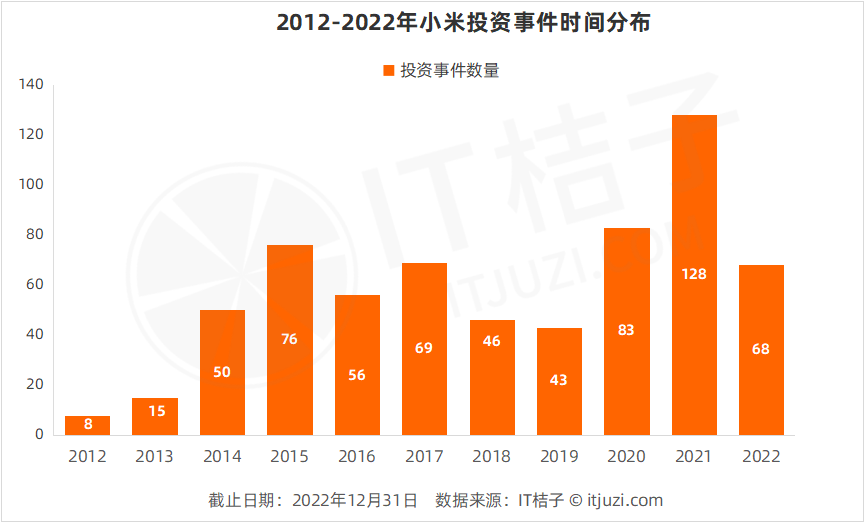
今天,分享一篇用GPT生成《超级马里奥》游戏关卡,近9成关卡可玩,希望以下用GPT生成《超级马里奥》游戏关卡,近9成关卡可玩的内容对您有用。
机器之心报道
编辑:赵阳、张倩
AIGC 正在变革游戏产业。
最近一年来,生成式 AI 在绘画、文本、代码等创作领域的表现越来越成熟,OpenAI 的聊天机器人 ChatGPT 更是将这一趋势推向舆论顶点。而 AIGC 在游戏领域的进展也备受关注,投资公司 a16z 不久前发表过一篇研究文章《AIGC 在游戏中的革命》,认为在所有娱乐类目中,游戏会是生成式 AI 影响最大的领域。
在之前的报道中,我们提到过 AIGC 在游戏音乐、剧情生成中的一些应用案例(见文末「相关阅读」)。此外,还有不少研究者专注于关卡生成方向。最近,来自哥本哈根信息技术大学等机构的研究者发表了一篇论文,介绍了他们如何应用一个名为 MarioGPT 的语言模型从文本生成《超级马里奥》游戏关卡。

论文链接:https://arxiv.org/pdf/2302.05981.pdf
一个智能体在玩MarioGPT生成的关卡。
这个研究方向从属于一个程序内容生成(PCG)的领域。PCG 是指可以自动创建游戏内容的技术,如创建关卡、地图或角色。程序内容生成的好处是可以增加游戏的可玩性,以及降低成本。
最近,PCG 和机器学习的发展已经开始以不同方式相互影响。一方面,程序化生成的环境成为评估 agent 的泛化能力的基准,Arcade 学习环境这样的非 PCG 基准成为过去,这种变化已经成为人们的共识。另一方面,PCG 研究人员已经开始将基于机器学习的方法纳入其系统当中。例如,最近的一些研究表明,生成对抗网络(GAN)等模型可以被用来生成各种游戏的关卡,如《毁灭战士》或《超级马里奥兄弟》,使用的关卡来自视频游戏关卡库。
然而,基于机器学习的程序内容生成(PCGML)在底层神经网络的隐空间中进行搜索的成本往往过于高昂。更为理想的方法是能够直接对生成器施加条件,使其创建具有某些属性的关卡,并且最好是用自然语言来完成。
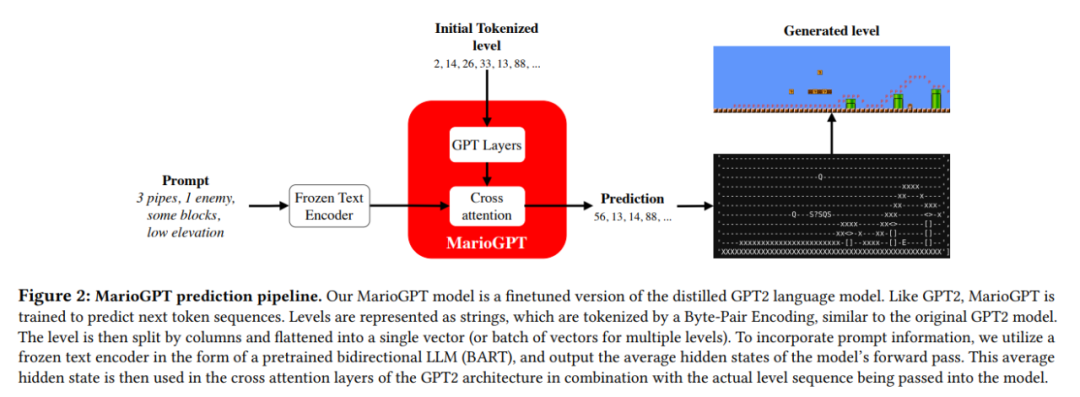
为了应对这些挑战,本文作者提出了 MarioGPT 模型(图 2)。这是一个经过微调的 GPT-2 模型,经过训练可以生成《超级马里奥》中的游戏关卡。该模型展示了大型语言模型是如何与 PCG 技术相结合的,最终能够通过自然语言下的 prompt 有效地创建新的、多样化的关卡。大规模语言模型(LLMs)是能够在多样化的语料库上训练的一类模型,如 GPT-n 系列模型,能够从语言的关联中捕捉人类行为的统计性关联关系。通过这个过程,GPT 获得了关于如何表示和预测复杂序列的知识。研究者利用这种知识为该模型提供了生成简单的游戏组件以及基于这些基础游戏组件生成更复杂的组件的能力。令人惊讶的是,MarioGPT 生成的关卡中,有很高的比例(88%)实际上是可以玩的。
此外,本文作者将 MarioGPT 与寻求多样性的算法 —novelty search 算法结合起来,以一种开放的方式不断地产生多样化的关卡。LLMs 与 novelty search 算法的结合为未来的研究开辟了许多有趣的新方向。研究者希望他们的工作能够为更灵活、更可控的 PCG 方法打开大门,使其能够生成复杂、多样和具备功能性的无尽的游戏内容。为了促进这一点,研究者表示将很快提供代码。
通过大型语言模型生成开放式关卡
在论文第三章,作者介绍了通过 LLMs 生成开放式关卡的完整方法,该方法由两部分组成。首先,作者介绍了属于一种 prompt-conditioned 的模型 ——MarioGPT(图 2),它可以在给定的自然语言 prompt 下生成关卡(编码为文本)。接着,图 3 详细介绍了 MarioGPT 如何融入 novelty search 算法的进化循环,从而使该方法能够不断地产生不同的关卡。
MarioGPT 模型
MarioGPT 是一种 prompt-conditioned 的单向语言模型,并且对长序列关卡的预测进行了优化。更确切地说,MarioGPT 的架构依赖于 GPT2 的蒸馏后的轻量级版本 ——DistilGPT2。与 novelty search 算法中采取的方法类似,研究者将这个蒸馏过的 GPT2 版本微调后,用于预测《超级马里奥》关卡中的 token。为了生成关卡,研究者将前 50 列的窗口串联成一个单一的向量,并将其送入 MarioGPT。利用 Transformer 的注意力机制,他们生成了质量更好,长度更长的关卡。
架构:MarioGPT 的架构与 DistilGPT2 的架构相同,区别在于交叉注意力的权重被用在了 prompting 上。尽管 DistilGPT2 支持大小为 1024 的上下文长度,但 MarioGPT 的上下文长度限制在了 700,因为研究者发现增加长度对提高性能没有什么作用。MarioGPT 总共有 9600 万个参数(8600 万个原始 DistilGPT2 的参数和 1000 万个交叉注意力权重)。研究者对 MarioGPT 进行了 5 万次 step 的训练,在每次迭代中随机抽取 4 个关卡,并使用 Adam 优化器对模型进行优化。总的来说,MarioGPT 使用了 200,000 个训练样本。由于该模型相对较小,它可以使用单个 Nvidia 2080ti GPU 进行训练。
关于 Prompting 的细节:为了包含 Prompt,研究者微调了注意力层的交叉注意力权重,如图 2 所示。Prompt 通过冻结权重的预训练语言模型 BART 进行编码生成。Prompt 通过权重冻结的语言模型传递,经过正向传递的隐状态被平均化为单个向量。随后,这个平均化的隐状态被输入到 GPT2 架构的交叉注意层中,并与被传入模型的实际关卡相结合。

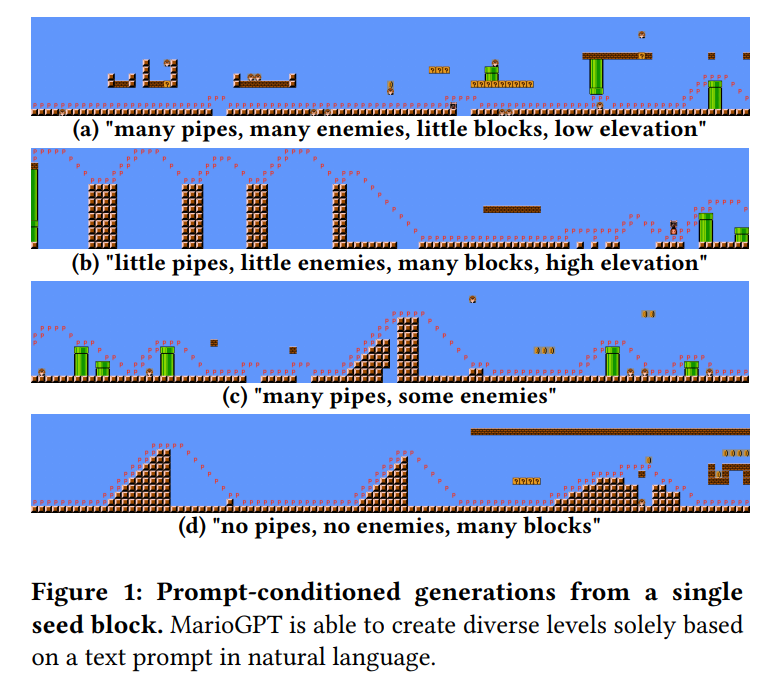
Prompt 表示为特定特征(例如管道、敌人、街区、立面)和定量关键词的组合:
例如,“没有管道,很多敌人,低海拔” 或 “许多管道,许多敌人,许多障碍” 都是可能的 Prompt。关键字 “no”、“little”、“some”、“many” 是根据相应计数的分位数(在 50 列窗口内)计算的,如表 2 所示。“低” 和 “高” 高程由水平段中最高不可破碎的石块的高度确定。

基于 Novelty Search 算法的开放式马里奥关卡生成
在 PCG 领域,重要的是不仅要生成具有不同物理特征的关卡,而且要生成让玩家能觉得有趣的关卡。在创建马里奥关卡时,重点就成为了,能够让玩家采取不同的路径来完成该关卡。这对许多之前的算法来说是一个挑战,需要使用外部 agent 进行评估。然而,有了 MarioGPT,就有可能生成多样化和可控制的关卡,这些关卡接近于现实的玩家路径,减少了对外部 agent 的需求,并产生可以直接玩的关卡。
为了鼓励生成关卡的多样性,研究者将 MarioGPT 整合到一个基于 Novelty Search 增强的遗传算法(NS-MarioGPT)中,其中语言模型扮演着变异算子的角色。如图 3 所示,NS-MarioGPT 从生成的关卡档案中反复采样和变异,这些关卡由在 MarioGPT 样本中随机选取的大小为 1400(100 列)的 Prompt 的初始化生成。
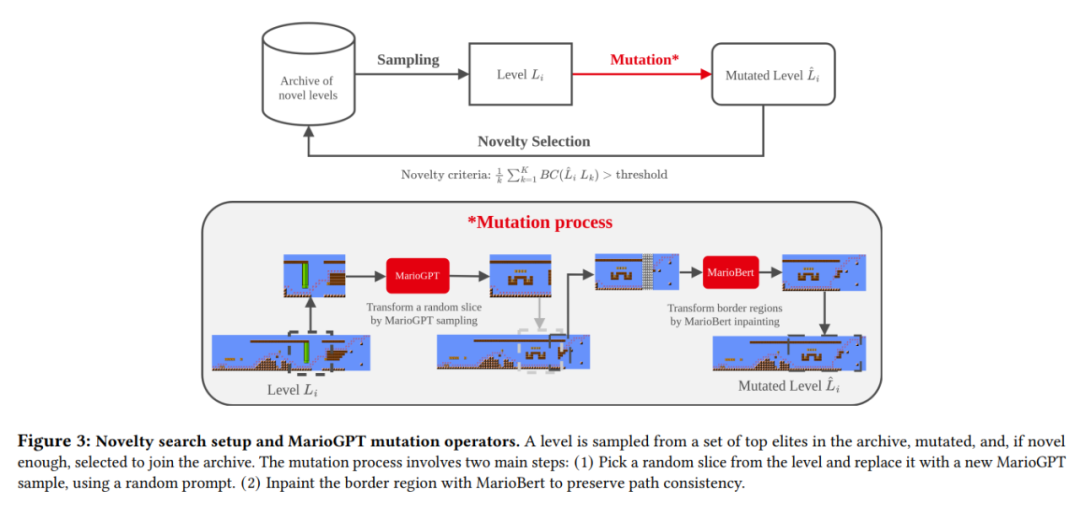
Novelty Search 算法:变异的关卡只有在比以前的最优解有更高的的 Novelty 分数时才会被储存在种群中。新颖性得分是以关卡的行为特征向量与种群中最接近的 k 个元素的行为特征向量之间的平均距离来衡量的(使用 K-means 算法)。
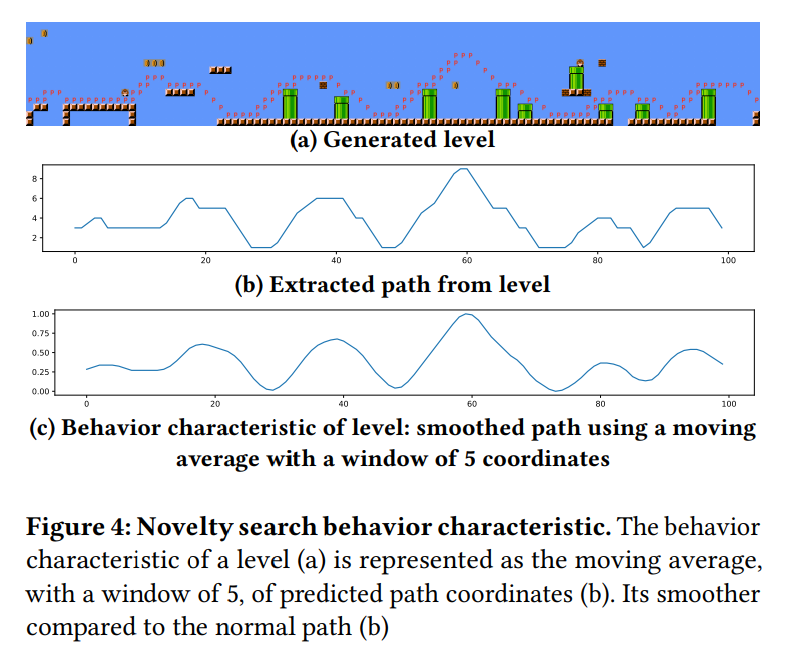
研究者在关卡生成中的目标是创建能让玩家行为多样化的路径,因此其使用预测的玩家路径作为行为特征的基础。更具体地说,研究者对预测路径的相对模式感兴趣。例如,如果一个玩家角色在高处的积木块上直线移动,研究者希望该路径的特征在行为空间中与在低处直线移动的路径相近。为了达到这个目的,研究者将行为特征表示为预测路径坐标的归一化平均值,从而使路径的特征变得平滑(图 4)。因此,单一块之间的差异的重要性被降低了,变异后的关卡更难被添加到种群中。这是研究者所希望的,这是因为种群库中不应该充斥着与种群中现有关卡仅有微小差别的关卡。
在研究者基于 novelty search 算法的实验当中,他们使用一个大小为 4 的小邻域,产生维度为 100 的行为特征。研究者用少量的关卡(30 个)初始化种群,这是因为他们发现单靠变异就足以产生一个多样化的关卡集,并不需要一个大的起始种群。
变异:本文介绍的基于 LLM 的变异操作(图 3)在随机 prompt 的引导下,将一个随机挑选的关卡切片(40-80 列之间的切片)与一个新的 MarioGPT 预测进行转换。就其本身而言,MarioGPT 能够通过变异,产生各种具有不同 agent 路径的关卡。然而,由于 MarioGPT 是一个单向的模型,不能保证新生成的路径与关卡的其他部分一致。为了进一步提高路径的一致性,研究者在 Bert 架构的基础上加入了一个微调的 mask 预测模型(称之为 MarioBert)。BERT 语言模型是一个双向的 LLM,在 mask 预测的任务中的表现十分惊艳。这种能力对于现在的情况来说是非常理想的,MarioBert 被用来在采样的图像片段的内部进行绘制,以平滑地连接变异的片断和关卡中其余的画面。这可以在图 3 的 "变异过程" 的第二步中观察到。
实验结果
为了评估 MarioGPT 生成多样化和可玩性关卡的能力,研究者觉得可以从以下几个维度去思考:(1)MarioGPT 与其他 baseline 在验证集上对 tile 的预测准确性方面的比较;(2)MarioGPT 生成的关卡是否能通关?(3) MarioGPT 是否会记忆?
为了衡量 MarioGPT 在生成关卡方面的熟练程度,研究者选择 LSTM,以及从头开始训练的 MarioGPT(不使用预训练的 GPT2 权重)作为 baseline,并比较了预测准确性,结果如表 3 所示。
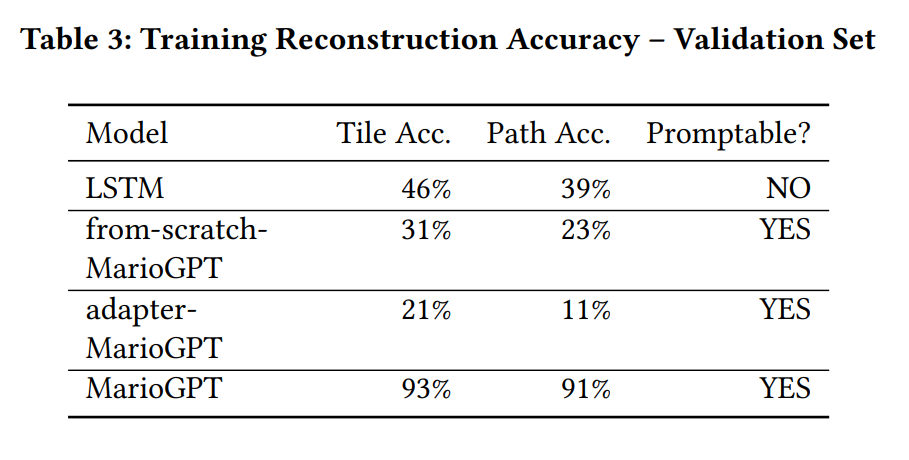
为了测试可玩性,研究者在 250 个关卡中部署了 Robin Baumgarten 的 A* agent。研究者发现,所有 MarioGPT 生成的关卡中,88.33% 可以由 agent 完成,因此可以判定为是可通关的。此外,研究者发现这些可以通关的关卡中只有一个需要使用 A* agent 再次运行一次。研究者进一步地测试模型生成的路径是否与 A* agent 的路径匹配,以评估其可行性。表 4 分别显示了可通关和不可通关关卡中,建议的路径和实际 A* agent 选择的路径之间的平均绝对误差(MAE)。

为了进一步研究生成的路径的质量,研究者可视化了具有最大、最小和中值重叠的路径(即与高度平均绝对误差的最大值、最小值和中值相对应的关卡)以及图 6 中两个有趣的手动选择的示例。
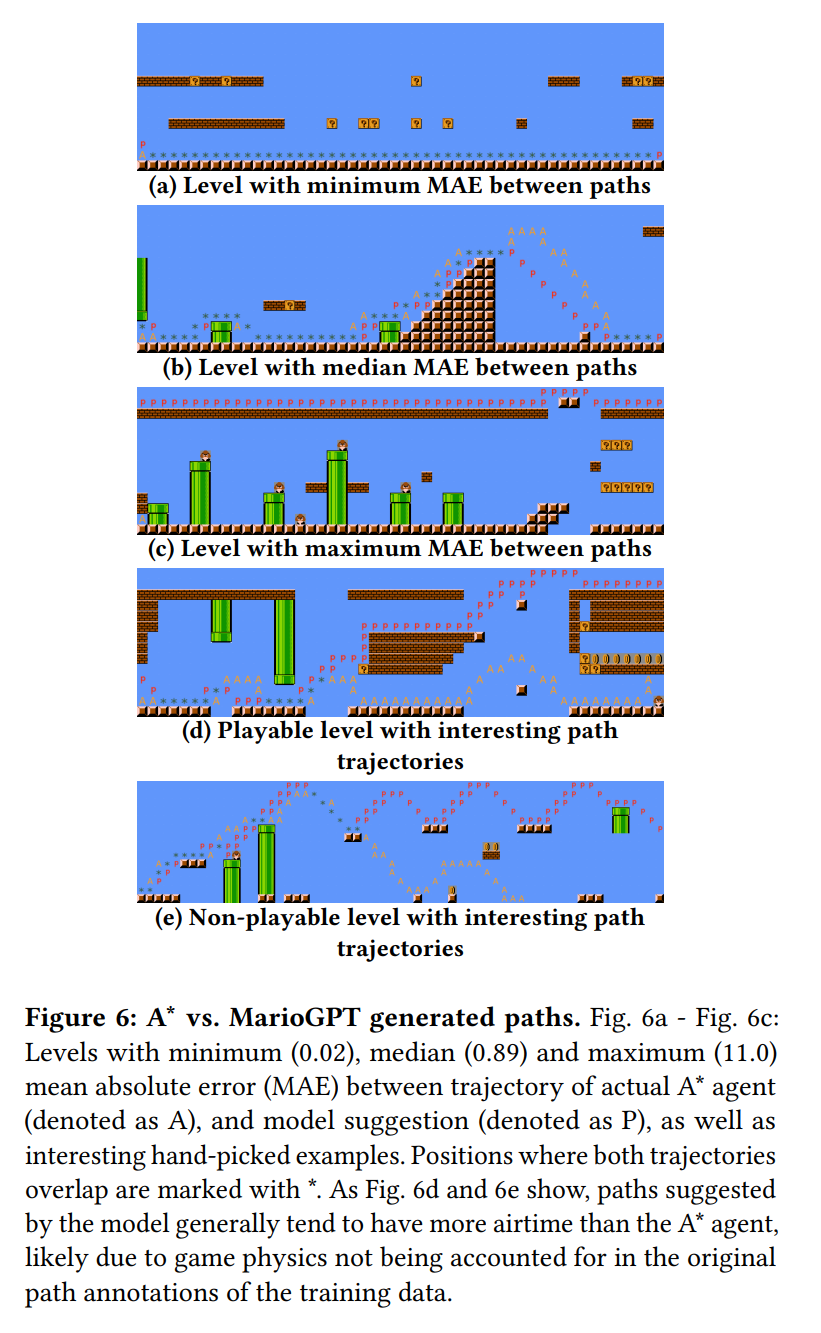
在训练 transformer 架构时,LLM 的动态记忆能力仍然是一个悬而未决的问题,并且许多工作对其进行了探索。虽然 LLMs 的功能非常强大,但它们有时会过度拟合,最终会反噬给训练数据。缓解这个问题的一个流行方法是在预测中加入一些随机性,即可调整的 热力学 "温度" 参数。为了评估 MarioGPT 是否产生了与训练集相同的关卡,我们用不同的温度参数进行采样,并与训练数据集中最接近的关卡进行比较。
通过简单的 prompting,本文能够引导 MarioGPT 走向可控和多样化的关卡生成。研究者通过使用各种 prompt 组合生成 1000 个样本,以实验的方式评估了 MarioGPT 的 prompt 能力,并检查生成的关卡对 prompt 描述的准确性。结果表明,MarioGPT 可以在大多数情况下生成与给定 prompt 匹配的关卡(表 5)
 研究者还对系统进行了可视化评估,在图 5 中显示了选定的即时条件下的生成结果。
研究者还对系统进行了可视化评估,在图 5 中显示了选定的即时条件下的生成结果。
凑巧的是,在这篇论文发布的当天,来自纽约大学坦登工程学院等机构的研究者也发布了一篇主题类似的论文,只不过生成的是《推箱子》游戏关卡。感兴趣的同学可以合并阅读。

论文地址:https://arxiv.org/pdf/2302.05817.pdf
这是一份全面、系统且高质量的 ChatGPT 文章合集,我们筛选出来了 89 篇相关文章,设计了阅读框架与学习路径,大家可以根据自己的需求进行浏览与研读。合集内容包括:
ChatGPT 及 OpenAI 大事件时间轴
概念·真正搞懂 ChatGPT:共 3 篇文章
研究·GPT 家族更迭:共 16 篇文章
八年·OpenAI 的历史与现在:共 13 篇文章
干货·GPT 相关研究与技术:共 18 篇文章
观点·专家谈 ChatGPT:共 8 篇文章
行业·应用与探索:共 23 篇文章
行业·同类产品:共 8 篇文章