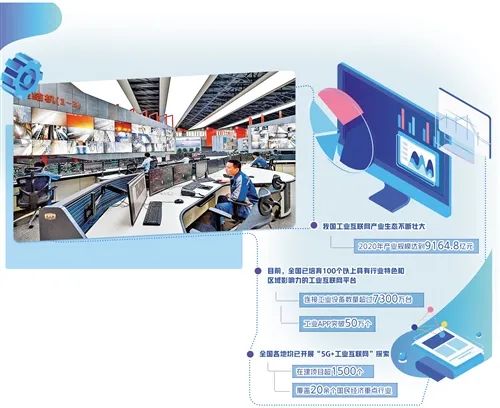
数据存储处理分析比以往更为复杂,而效率和成本催生了智能湖仓架构的兴盛。
本文来源:199IT Ralf
2019年,全球汽车巨头丰田着手自身车联网服务的打造。通过给汽车配备车载数据通信模块DCM,用户授权将数据传到丰田互联构建的超大数据湖里面,对数据湖里的数据分析驾驶员可以更安全地使用汽车。包括精准感知车况、驾驶习惯的科学建议、甚至根据驾驶习惯来判断保险折扣。
这一超大车联网系统背后的重要一环是亚马逊云科技数据湖的强力支持。
而今,数据存储处理分析比以往来得更为复杂。效率和成本催生了智能湖仓架构的兴盛。虽然智能湖仓架构并非新近提出,但亚马逊云科技在2020 re:Invent上,迭代自身的智能湖仓架构,其要点在于智能湖仓架构对整体数据的更好支撑。
为何会需要智能湖仓架构,如果从应用的结果层面来看,亚马逊云科技大中华区云服务产品部总经理顾凡给出的三个挑战或许说明了一些问题。

顾凡认为,首先,当前数据呈指数级增长,从GB、TB、PB到EB,从结构化到半结构化到非结构化数据。数据量及非结构化数据越来越大。
其次,数据面临更为复杂的使用场景。不同分析场景下的数据会需要技术更加的个性化和定制化。数据驱动决策对象范围越来越大。
再次,基于实时数据的快速决策,让以前几天的决策变成了分钟级别决策,甚至在一些实时流分析中实时就应该给到决策。
从应用深入到底层,一个被反复提及的重点是数据的无缝移动。无缝移动在哪几个之间移动,数据湖、数据仓库以及围绕着数据湖周边构建的所有的这些专用的数据存储,SQL的数据库,Non-SQL的数据库,甚至更多不同的分析引擎。数据如何在湖、仓和不同的数据专用分析服务之间移动非常关键。
如何构建智能湖仓架构,亚马逊云科技所定义的智能湖仓架构不仅仅是湖和仓的打通,而是湖、仓专门构建数据服务连接成一个整体。
顾凡表示,“要构建一个数据湖要有专门构建的数据分析服务,要能做到数据、湖、仓和专门构建的数据服务的无缝数据移动,统一管理、低成本,这是我们所定义的亚马逊云科技智能湖仓架构。“
亚马逊云科技“智能湖仓”架构具有以下五个特点。
灵活扩展,安全可靠。亚马逊云科技“智能湖仓”架构用Amazon S3作为数据湖的存储基础,客户可根据不断变化的需求,灵活扩展或缩减存储资源。Amazon S3可达到 99.999999999%(11 个 9)的数据持久性,且具有强大的安全性、合规性和审计功能。
专门构建,极致性能。为了满足客户不同的数据分析需求,亚马逊云科技提供全面而深入的、专门构建的数据分析服务,包括交互式查询服务Amazon Athena、云上大数据平台Amazon EMR、日志分析服务Amazon Elasticsearch Service、Amazon Kinesis、云数据仓库Amazon Redshift等。这些专门构建的数据分析服务为客户提供了极致性能,客户在使用过程中不必在性能、规模或成本之间做出任何妥协。其中Amazon Redshift的性价比是其他企业云数据仓库的三倍,AQUA(分布式硬件加速缓存)使 Redshift 查询的运行速度比其他其他云数据仓库最高快 10 倍;Amazon EMR运行大数据处理及分析服务的成本不到传统本地解决方案的一半,但其速度比标准 Apache Spark 快 3 倍以上。
数据融合,统一治理。亚马逊云科技“智能湖仓”架构不止是打通了数据湖、数据仓库,还进一步将数据湖、数据仓库以及所有其它数据服务组成统一且连续的整体。在实际应用场景中,数据需要在这些服务与数据存储方案之间,以及服务与服务之间按需来回移动,跨服务访问。亚马逊云科技“智能湖仓”架构降低了数据融合与数据共享时统一安全管控和数据治理的难度。其中,Amazon Glue提供数据无缝流动能力,Amazon Lake Formation提供了快速构建湖仓、简化安全与管控的全面数据管理能力。
敏捷分析,深度智能。亚马逊云科技将数据、数据分析服务与机器学习服务无缝集成,为客户提供更智能的服务。例如Amazon Aurora ML、Amazon Redshift ML、Neptune ML等,数据库开发者只需使用熟悉的 SQL 语句,就能进行机器学习操作;Amazon Glue、Amazon Athena ML、Amazon QuickSight Q等,可以帮助用户使用熟悉的技术,甚至自然语言来使用机器学习,帮助企业利用数据做出更好的决策。用户还可以通过机器学习服务Amazon SageMaker、个性化推荐服务Amazon Personalize等挖掘数据智能。
拥抱开源,开放共赢。亚马逊云科技“智能湖仓”架构中的关键组件如Amazon EMR、Amazon Elasticserach Service、Amazon MSK的核心都基于开源代码,接口与开源完全兼容,无需改变任何代码就可以实现迁移,也兼容主流的管理工具。OpenSearch 基于开放的Apache2.0 授权,其代码完全开放,用户可以免费下载使用并获得企业级的功能。这些服务允许用户在转型过程中,以非常低的改造成本向云端迁移。
在顾凡眼中,数据的价值实现有三个步骤:第一是如何把数据基础设施现代化,采用云上的云原生数据库。第二如何从数据中真正产生价值,包括诸多的分析的工具。第三,如何用机器学习更好地辅助决策,甚至是驱动决策。
目前,亚马逊云科技已经打通旗下机器学习Amazon SageMaker和湖仓的融合,同时实现机器学习的再扩圈,数仓和数据库的开发人员或者分析师是SQL专家,但不懂Python,可以让他们能很快上手使用机器学习,而不用让数据科学家帮自己构建算法模型。