原标题:AMD Zen3 3D堆叠缓存细节:比Intel更细致、互连带宽提升15倍 来源:快科技
先进制程工艺的推进越来越困难,成本也越来越高,半导体巨头们纷纷把目光投降了各种封装技术。Hot Chips 33大会上,AMD就第一次公开了3D V-Cache堆叠缓存的部分技术细节。
AMD此前六月初在台北电脑展上首次披露了这一技术,利用一颗锐龙9 5900X 12核心处理器,每个CCD计算芯片上堆叠64MB SRAM作为额外的三级缓存,加上原本就有的64MB,合计达192MB,游戏性能因此可平均提升15%,堪比代际跨越。

这一次,AMD首先罗列了各家的各种封装技术,包括Intel、台积电、苹果、三星、索尼等等,并强调之所以有如此丰富的封装技术,是因为没有一个方案能够满足所有产品需求,必须根据产品属性来定制。
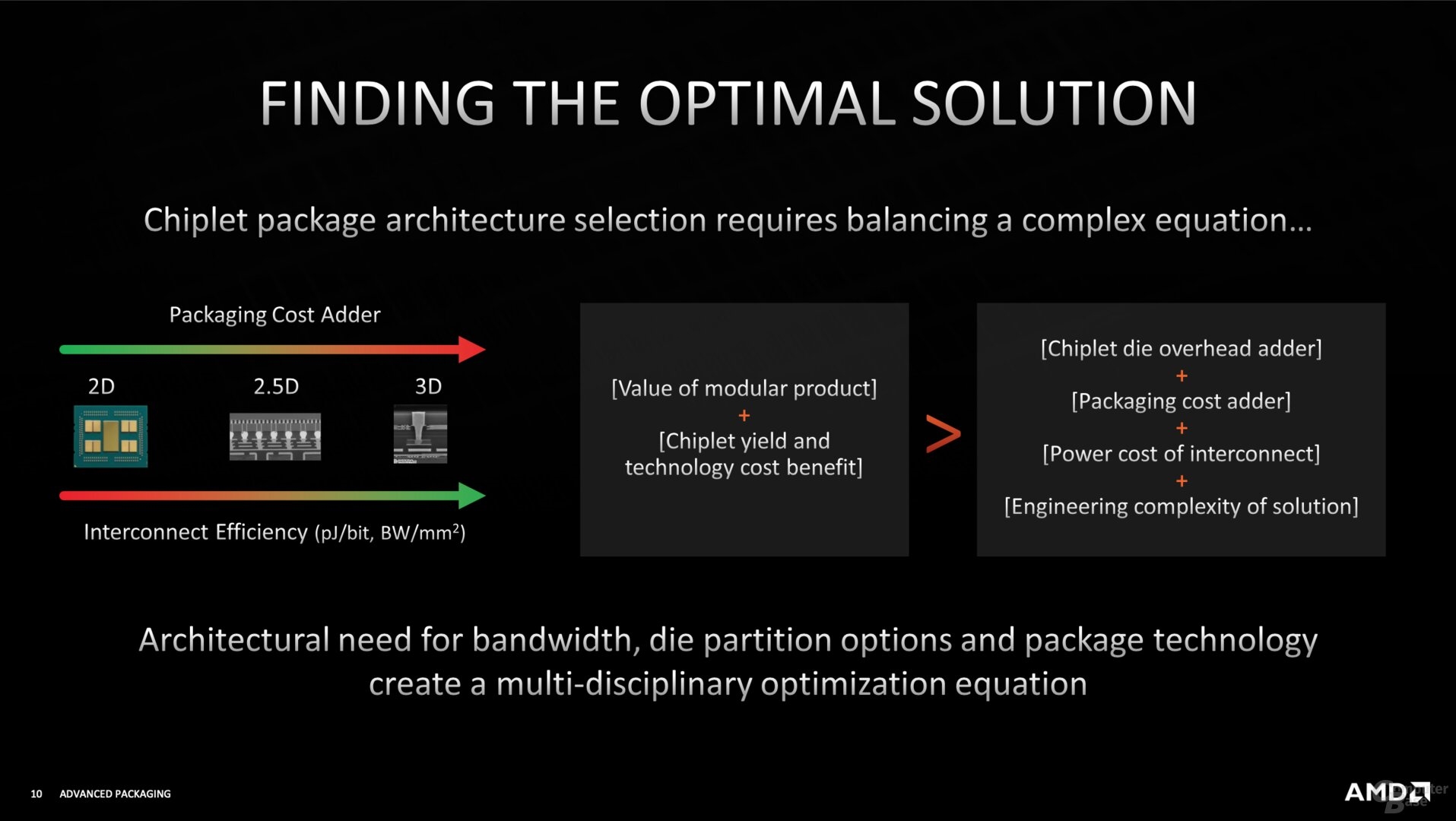
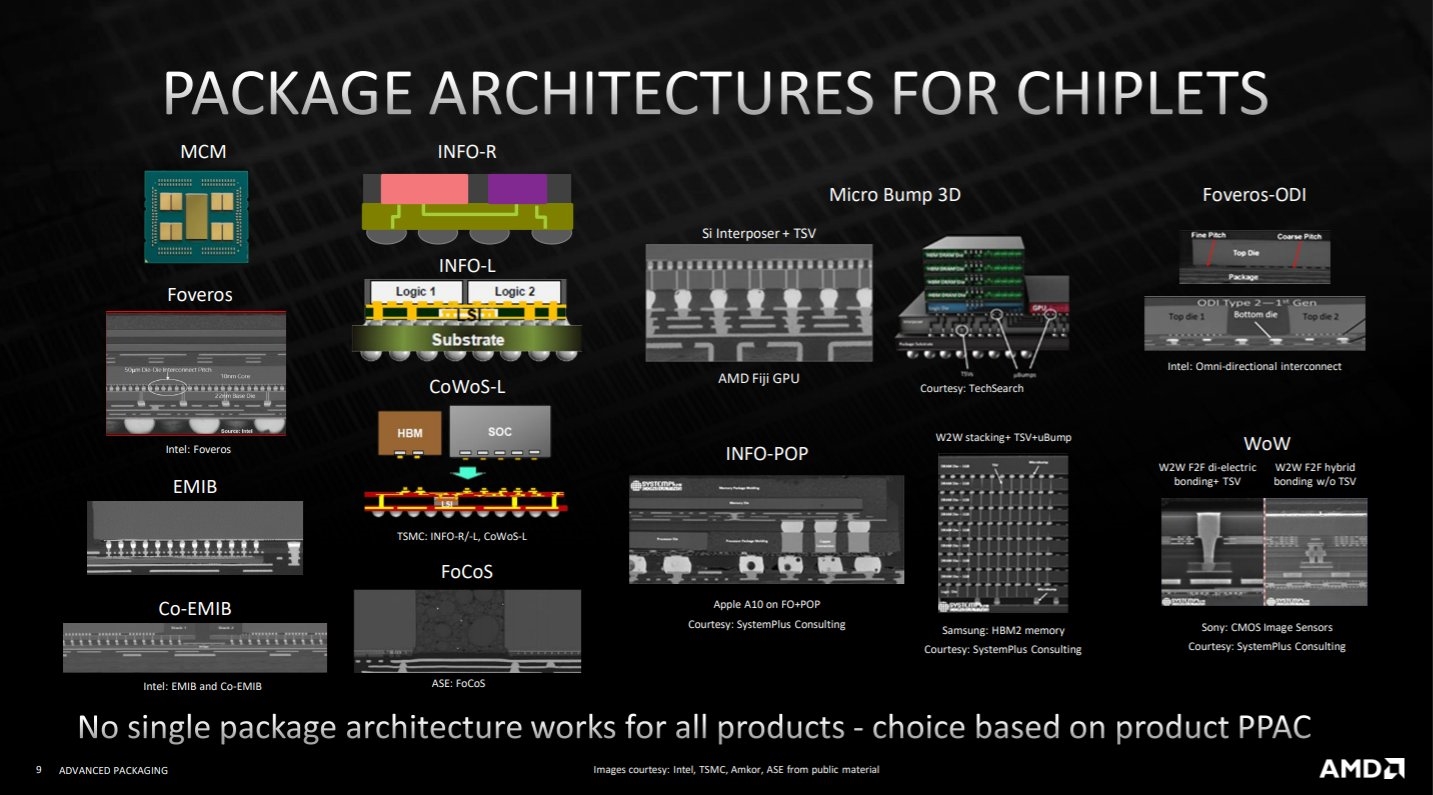
AMD使用的技术叫做“3D Chiplet”(立体芯片),是在微凸点3D(Micro Bump 3D)技术的基础上,结合硅通孔(TSV),应用了混合键合(Hybrid Bonding)的理念,最终使得微凸点之间的距离只有区区9微米,相比于Intel未来的Foveros Direct封转技术还缩短了1微米,结构更加细致。
AMD声称,3D Chiplet技术可将互连功耗降低至原来的1/3,换言之能效提升3倍,互联密度则猛增15倍。

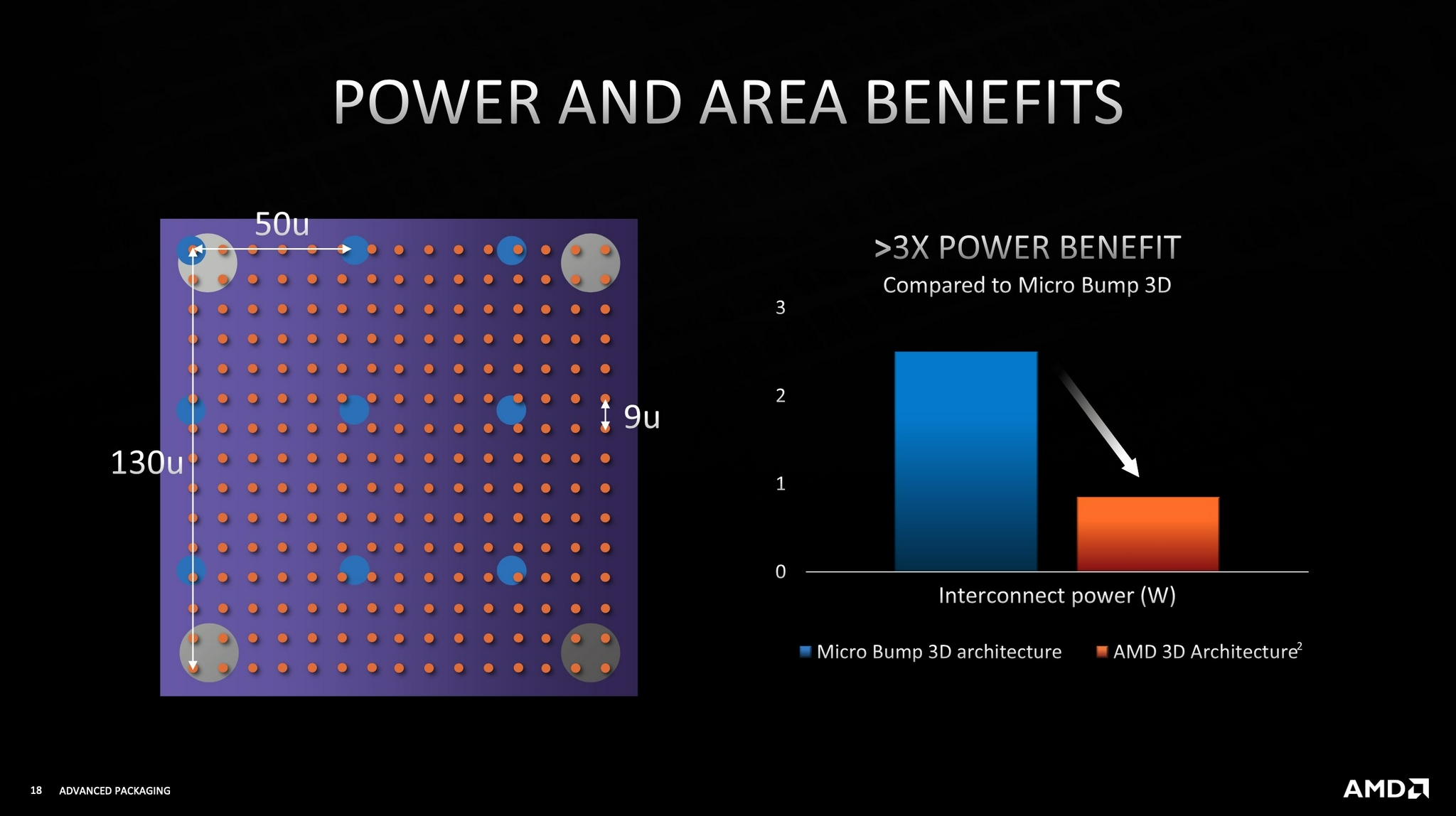


总之,AMD 3D堆叠缓存并没有使用全新独创的复杂封装工艺,主要是基于现有技术,针对性地加以改进、融合,更适合自身产品,从而以最小的代价,获得明显的性能提升,不失为一种高性价比策略。
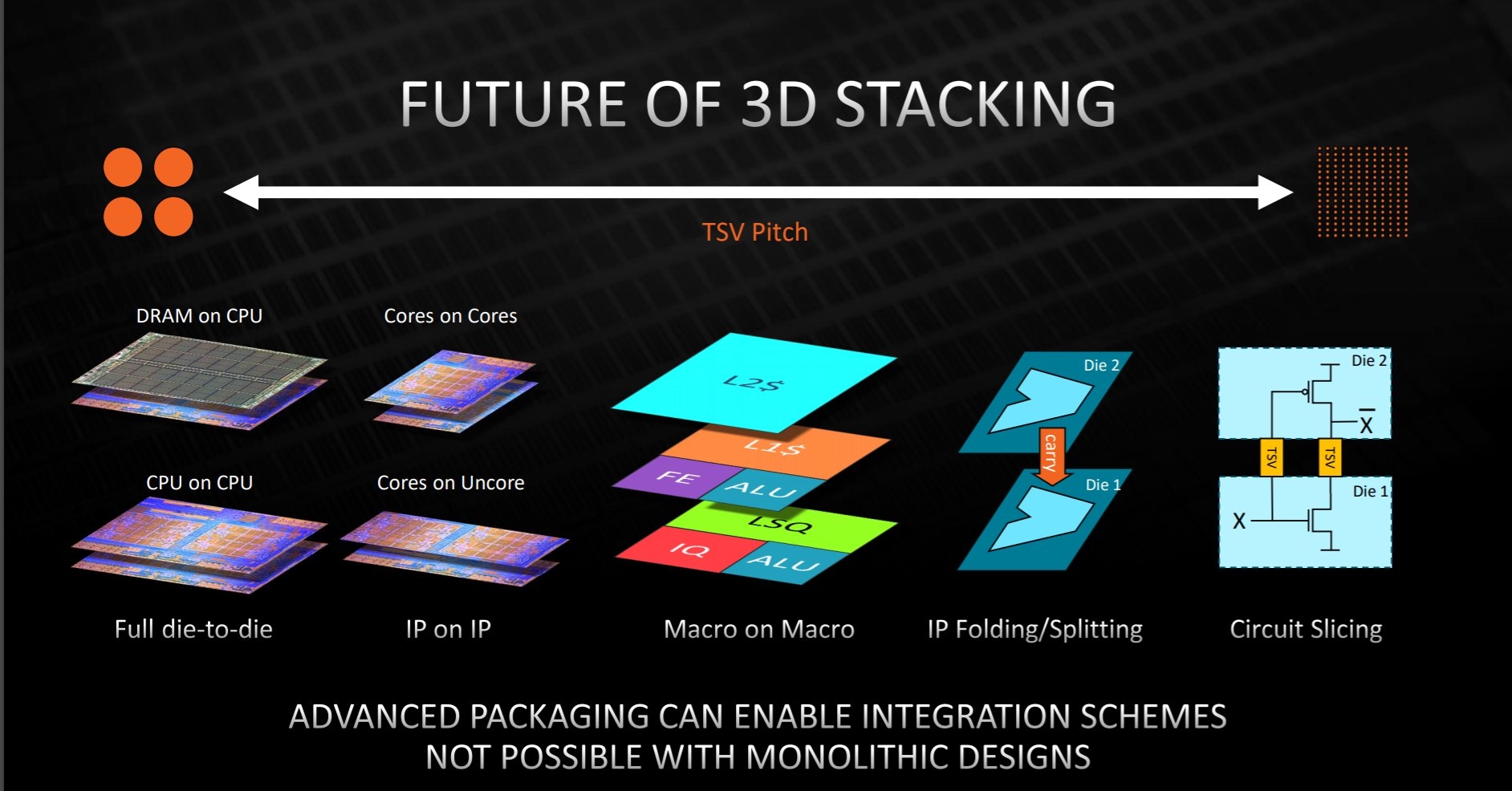
按照之前的说法,搭载3D V-Cache缓存的锐龙处理器将在今年底量产,可能就是锐龙6000系列,而基于全新Zen4架构的下一代产品,要到明年下半年了。

堆叠额外缓存的锐龙