AI自动生成的字幕,能离谱到什么程度?不仅把“螃蟹”(crab)误听成“废话”(crap),当场爆粗,甚至还能把“玉米”(corn)给翻译成p*rn……


关键在于,这些是AI给儿童节目自动生成的字幕。
被AAAI 2022收录的一篇新研究发现,在7013个儿童视频中,接近40%的节目出现了少儿不宜或脏话等词汇。
甚至在一个113集的儿童机器人学习栏目中,AI就“爆粗”了103次,平均接近一集一次!
对此,油管(YouTube)在接受《连线》采访时回应:
我们为13岁以下的儿童开发了YouTube Kids,这个APP会关闭字幕生成功能。
但如果真有字幕需求的话,如何才能想办法减少这种AI生成错误?
一起来看看。
亚马逊Google都很“祖安”
先来看看这篇论文的调查结果。
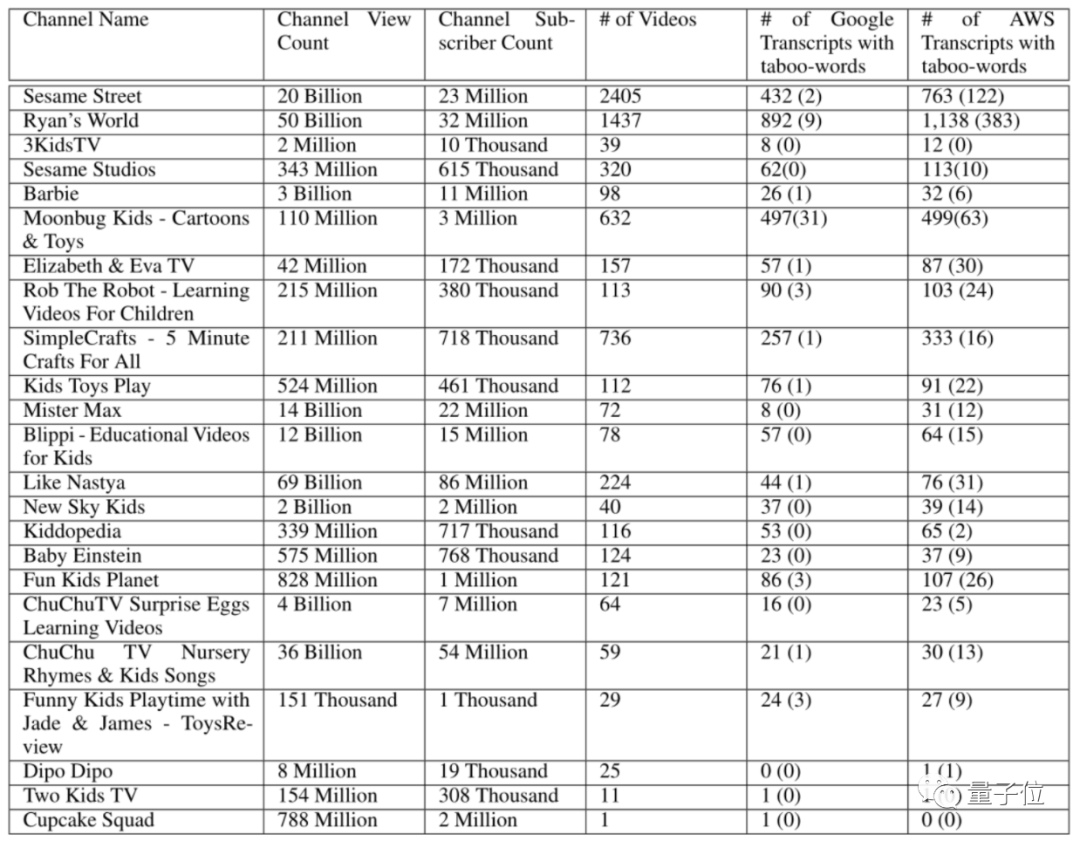
研究人员一共从油管上选出了24个儿童频道,分别记录了这些频道的播放量和订阅量。
可以看出,这些筛选出来的视频播放量基本都达到了百万级,订阅人数也同样不少。
然后,研究人员分别试了一下Google和AWS(亚马逊网页服务)的字幕生成效果。
结果显示,AI字幕的“少儿不宜”率可谓离谱:
在7013个视频中,GoogleAI出现错误字幕的次数达到2768次,接近40%。
亚马逊的AI字幕错误率还要更高,达到了3672次,超过52%。
具体来说,两个AI分别容易在这些“不太恰当”的字词上出错:
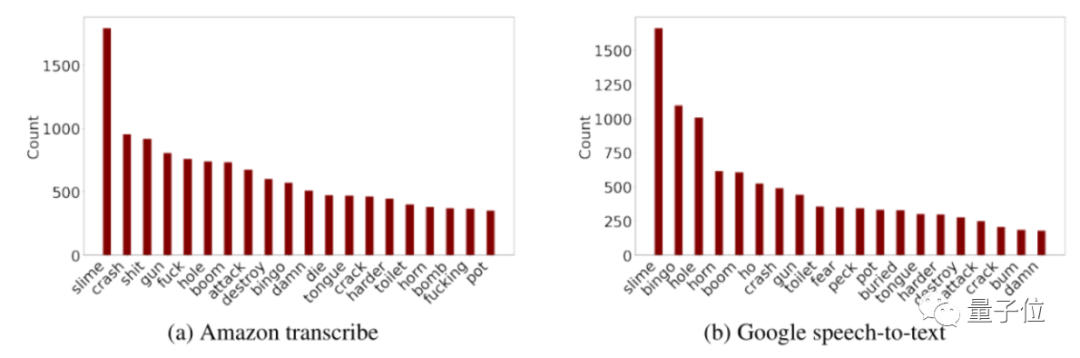
图左亚马逊,图右Google
在这些数据集中,有一些词语又尤为“少儿不宜”,例如一些骂人的脏词:
经过作者们人工检查(例如确认原视频是否真的说了脏话),发现AI主要容易在以下几种情况中出错:
背景音乐嘈杂
说话者为婴儿
说话者为儿童
说话者以英语为第二语言
说话者在唱歌
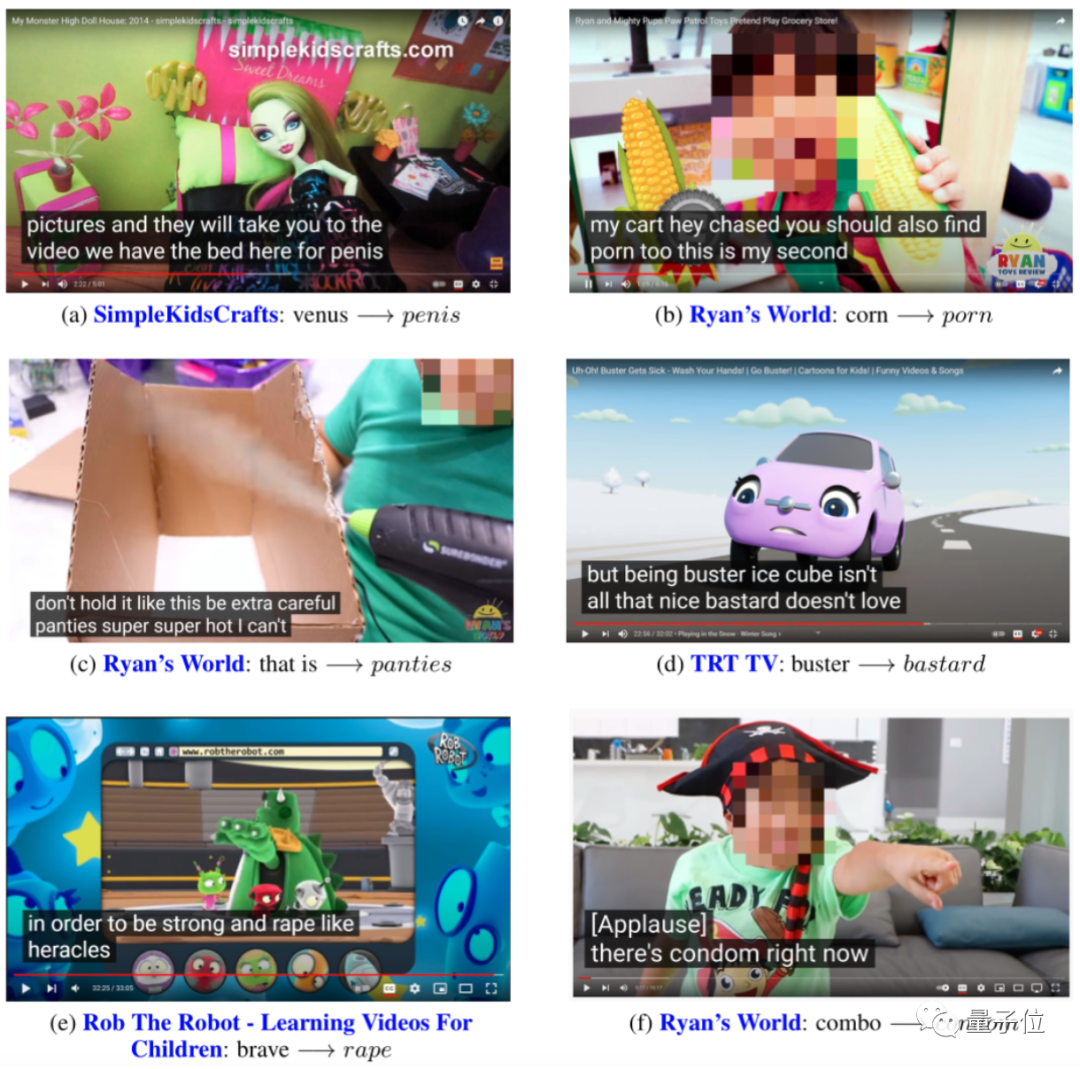
包括但不限于这些情况
那么,有没有什么办法减少这种情况发生呢?
语序连贯的错误更容易修复
研究人员提出了一个新的数据集,利用近音字词来构建禁忌词的“替换”备选。
例如,对于crap这一可能出现的“粗口”,研究人员就给它设置了crab、craft等读音相似的字词,便于AI在搞错时进行替换。
具体来说,他们在BERT、XLM、XLNet等NLP模型上,针对“完形填空”任务进行了重新训练,也就是用[MASK]遮住部分单词,让AI来填写对应的内容。
结果显示,在语序正常、前后文案有逻辑的视频中,AI替换的准确率更高(蓝色为正确替换词):

然而在一些逻辑不强的文案中,成功替换的效果就没有那么好了:

最终,Megatron和Levenshtein等模型展现出了最好的修复效果,分别给亚马逊AI带来了超过25%的正确修复率,给GoogleAI带来了超过28%的修复率。
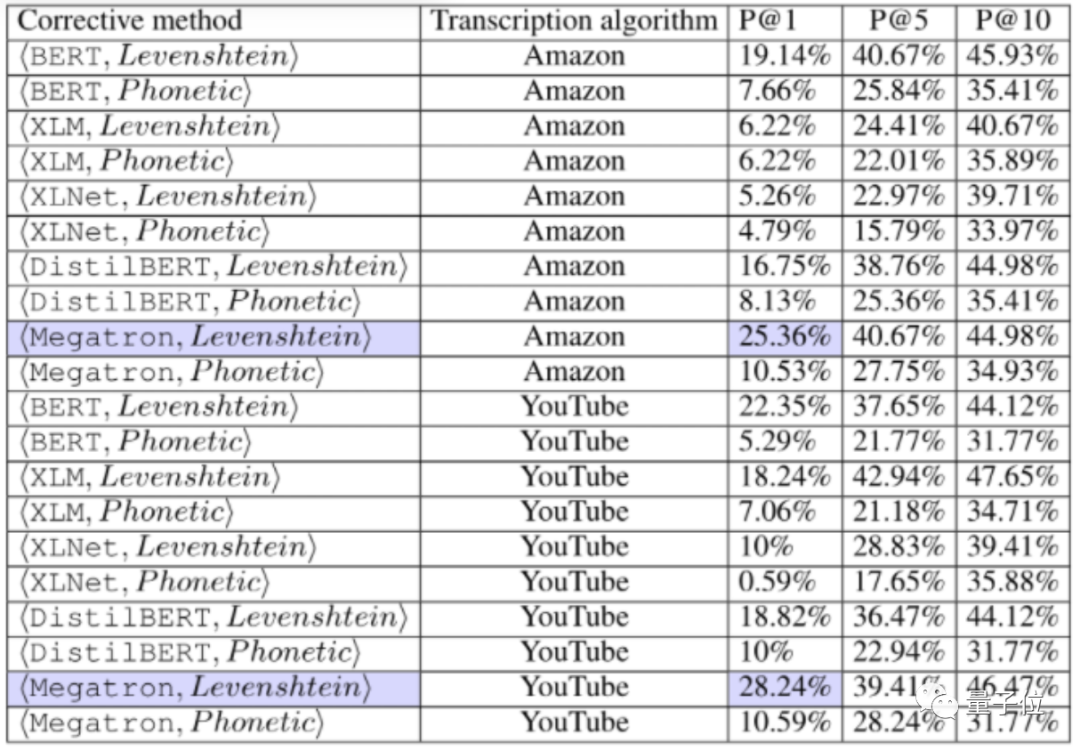
看来AI在字幕生成能力上还是任重道远啊。
自 量子位