AMD、Graphcore 和英特尔 3D 芯片技术颠覆计算的方式。
高性能处理器研究表明,延续摩尔定律的新方向即将到来。每一代处理器都需要比上一代性能更好,这也意味着需要将更多的逻辑电路集成到硅片上。但是目前在芯片制造领域存在两个问题:一是我们缩小晶体管及其构成逻辑和内存块的能力正在放缓;另一个是芯片已经达到了尺寸极限。
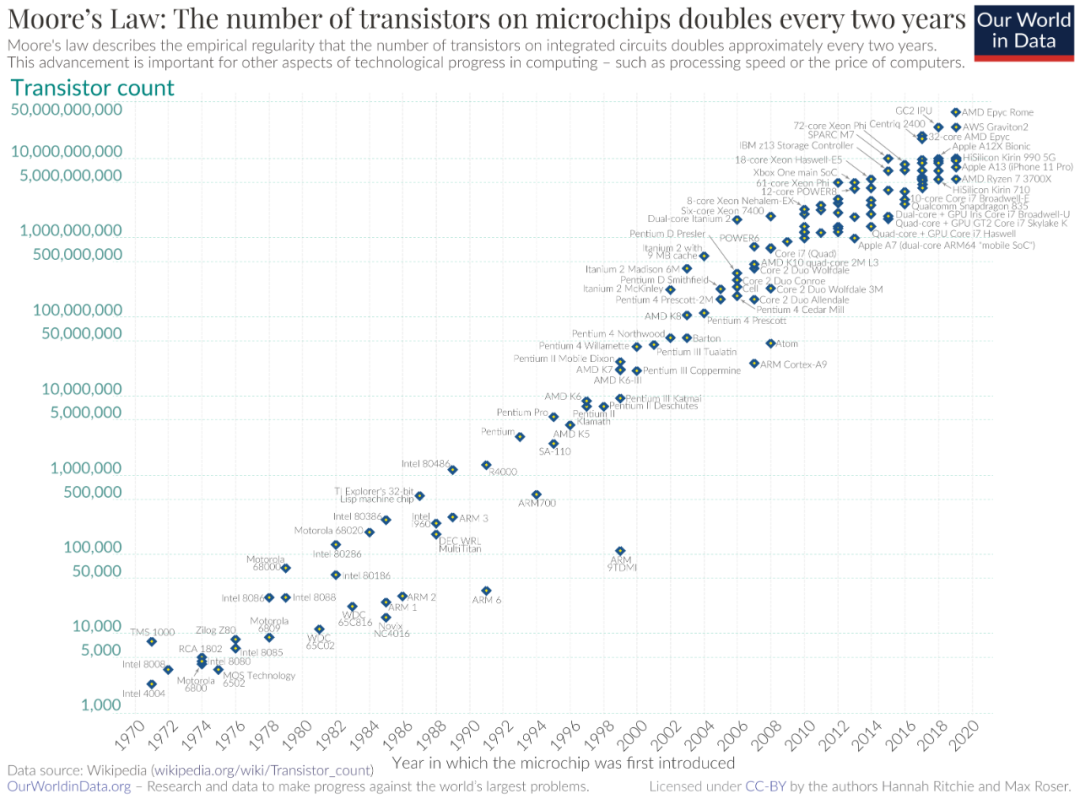 摩尔定律。图源:wikipedia
摩尔定律。图源:wikipedia光刻工具只能刻印大约 850 平方毫米的区域,大约是顶级 Nvidia GPU 的大小。
近几年,片上系统开发人员开始将较大的芯片设计分解成较小的芯片,并在同一个封装内将它们连接在一起。在 CPU 中,连接技术大多是 2.5D 封装,其中小芯片彼此并排放置,并使用短而密集的互连连接。由于大多数制造商已就 2.5D 「小芯片 - 小芯片」通信标准达成一致,这种集成的势头会不断发展。
但是,由于数据存储需求增加,要想将大量数据存储在同一个芯片上,就需要更短、更密集的连接,而这只能通过将一个芯片叠加在另一个芯片上来实现。将两个芯片进行连接意味着芯片之间每平方毫米要进行数千次连接。
这需要大量的创新才能实现,工程师必须弄清楚如何防止堆栈中一个芯片由于过热毁掉另一个芯片,防止偶尔出现的坏小芯片导致整个系统崩溃等。
近日,IEEE Spectrum、负责半导体报道的高级编辑 Samuel K. Moore 撰文介绍 3D 芯片技术颠覆计算的 3 种方式,主要介绍了 AMD、Graphcore 和英特尔行业领先优势。
AMD Zen 3
长期以来,个人电脑可以选择增加内存来提高超大应用程序和数据量大的工作速度。得益于 3D 芯片堆叠,AMD 的下一代 CPU 小芯片将提供这种选择。
Zen 2 和 Zen 3 处理器内核都使用相同的台积电制造工艺,因此具有相同尺寸的晶体管、互连等。AMD 在架构上做了很多改变,即便没有额外的缓存内存,Zen 3 的平均性能也提高了 19%。

值得一提的是 Zen 3 架构亮点之一是硅通孔 (TSV) 垂直堆叠芯片,这是一种将多个芯片相互连接的方式。TSV 是在 Zen 3 最高级别缓存中构建的,即称为 L3 的 SRAM 块,它位于计算小芯片的中间,并在所有 8 个核心上共享。
在处理繁重数据的处理器中,Zen 3 晶圆背面被减薄,直到 TSV 暴露出来,然后,一个 64 兆的 SRAM 小芯片被连接到那些暴露的 TSV 上,该过程使用的是混合键合——一种类似于铜冷焊的过程。其结果是一组密集的连接可以紧密到 9 微米。最后,为了结构稳定和热传导,在 Zen 3 CPU die(Die 或者 CPU Die 指的是处理器在生产过程中,从晶圆上切割下来的一个个小方块)的剩余部分附着空白硅小芯片。
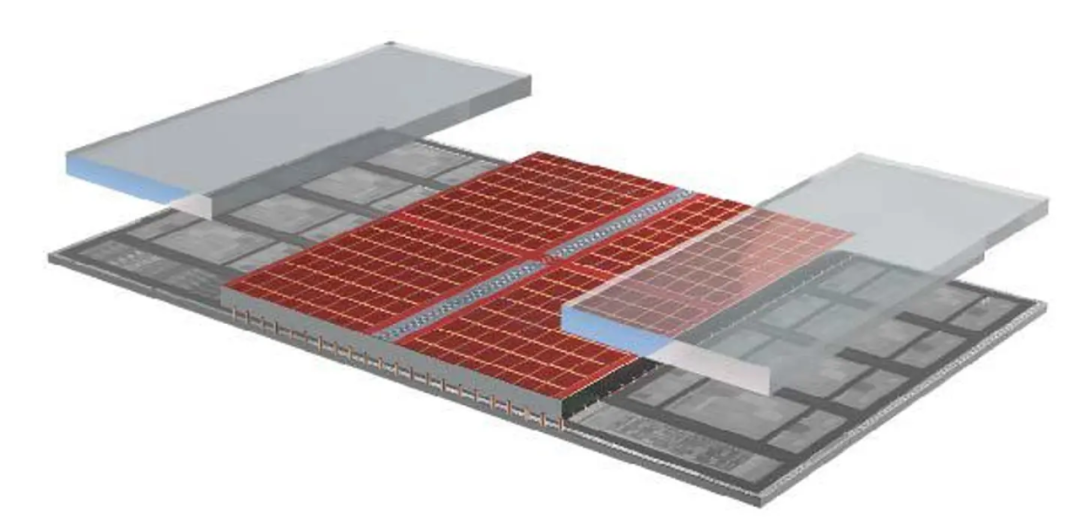
AMD 3D V-Cache 技术将一个 64 兆字节的 SRAM 缓存(红色)和 2 个空白结构小芯片堆叠到 Zen 3 计算小芯片上。
「通过将空白硅小芯片设置在 CPU die 旁边来增加额外的内存是不可取的,因为数据要花费太长的时间才能到达处理器核心。尽管 L3 缓存大小增加了三倍,但 3D V-Cache 仅增加了四个时钟周期的延迟——这只能通过 3D 堆叠来实现,」AMD 高级设计工程师 John Wuu 表示。
更大的缓存在高端游戏中占有一席之地,使用具有 3D V-Cache 的台式机 Ryzen CPU 可将 1080p 的游戏速度平均提高 15%。Wuu 指出,与缩小逻辑能力相比,业界缩小 SRAM 的能力正在放缓。因此,我们可以预测 SRAM 扩展将继续使用更成熟的制造工艺,而计算小芯片则被推向摩尔定律的前沿。
Graphcore Bow AI 处理器
即使堆栈中的芯片没有晶体管,3D 集成也能加快计算速度。总部位于英国的 AI 计算机公司 Graphcore 仅通过在其 AI 处理器上安装电力传输(power-delivery)芯片,就实现了系统性能的大幅提升。
添加电力传输硅意味着名为 Bow 的组合芯片可以运行得更快(1.85 GHz VS 1.35 GHz),并且电压低于其前一代。这意味着与上一代相比,计算机训练神经网络的速度提高了 40%,能耗降低了 16%。最重要的是,用户无需更改其软件即可获得这种改进。
电源管理 die 由电容器和硅通孔堆叠而成,后者为处理器芯片提供电力和数据,真正与众不同的是电容器。与 DRAM 中的位存储组件一样,这些电容器是在硅中又深又窄的沟槽中形成的。由于这些电荷储存器非常靠近处理器的晶体管,功率传输变得平滑,从而使处理器内核能够在较低电压下更快地运行。
如果没有电力传输芯片,处理器必须将其工作电压提高到高于其标称水平才能在 1.85 GHz 下工作,这样会消耗更多的功率。使用电源芯片,它也可以达到既定的时钟频率并消耗更少的功率。

Graphcore Bow AI 加速器使用 3D 芯片堆叠将性能提升 40%。
Bow 的制造工艺是独一无二的。大多数 3D 堆叠是通过将一个小芯片粘合到另一个小芯片上来完成的,其中一个仍然在晶圆上,称为晶圆上芯片 [参见上面 AMD 的 Zen 3]。相反,Bow 使用了台积电的「晶圆 - 晶圆」,其中一种类型的整个晶圆与另一种类型的整个晶圆键合,然后切割成芯片。
Graphcore 首席技术官 Simon Knowles 表示,这是市场上第一款使用该技术的芯片,它使两个裸片之间的连接密度高于使用晶圆芯片工艺所能达到的密度。
 BOW-2000。
BOW-2000。尽管电力传输小芯片没有晶体管,但不久的将来可能会出现。Knowles 说,仅将这项技术用于电力传输只是第一步,在不久的将来,它会走得更远。
了解更多请参考:https://spectrum.ieee.org/graphcore-ai-processor
英特尔 Ponte Vecchio 超级计算机芯片
Aurora 超级计算机旨在成为美国首批突破 exaflop 障碍的高性能计算机 (HPC) 之一——每秒 10 亿次高精度浮点计算。为了让 Aurora 达到这些性能,Ponte Vecchio 将 47 块硅片上超过 1000 亿个晶体管封装到一个处理器中。英特尔同时使用 2.5D 和 3D 技术,将 3,100 平方毫米的硅片(几乎等于四个 Nvidia A100 GPU)压缩到 2,330 平方毫米的空间中。

英特尔 Ponte Vecchio 处理器将 47 个小芯片集成到一个处理器中。
每个 Ponte Vecchio 实际上是两组镜像芯片,使用英特尔的 2.5D 集成技术 Co-EMIB 连接在一起,Co-EMIB 在两个 3D 小芯片堆栈之间形成高密度互连的桥梁。「桥」本身是嵌入封装有机基板中的一小块硅,硅上互连线的密度可以是有机基板上的两倍。Co-EMIB die 还将高带宽内存和 I/O 小芯片连接到 base tile(最大的小芯片,其他芯片都堆叠在其上)。
base tile 使用英特尔的 3D 堆叠技术,称为 Foveros,在其上堆叠计算和缓存小芯片。该技术在两个芯片之间建立了密集的 die-to-die 垂直连接阵列,这些连接是 36 微米。信号和电源通过硅通孔进入这个堆栈,较宽的垂直互连直接穿过硅的大部分。
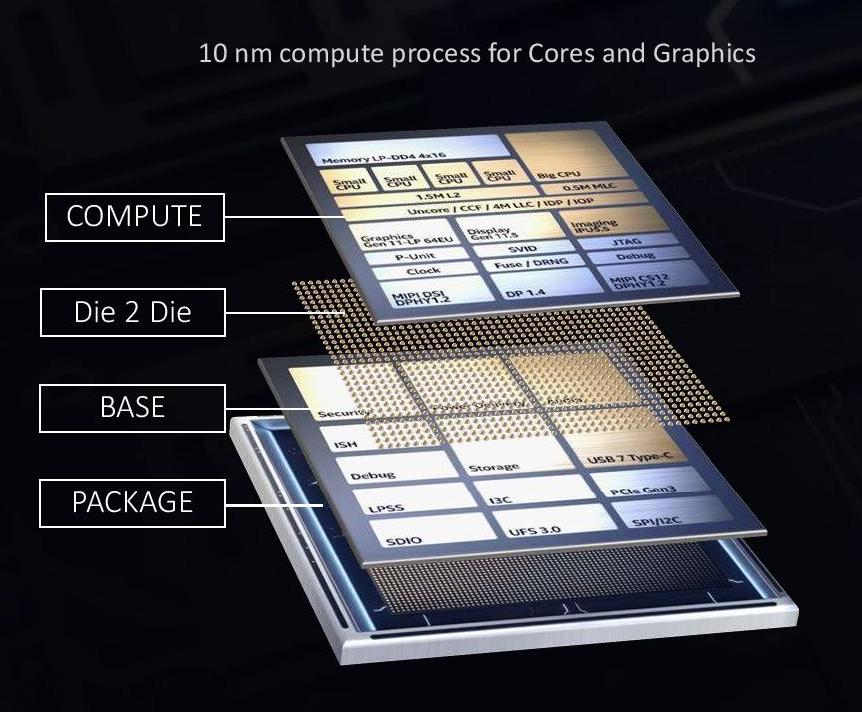 Foveros。
Foveros。八个计算 tile、四个缓存 tile 和八个用于给处理器散热的空白 tile 都连接到 base tile 上。base tile 本身提供缓存内存和允许计算 tile 访问内存的网络。
英特尔研究员 Gomes 表示:这一切都不容易,Ponte Vecchio 在良率管理、时钟电路、热调节和功率传输方面都进行了创新。例如,英特尔工程师选择为处理器提供高于正常电压(1.8 伏)的电压,以便电流足够低以简化封装。base tile 中的电路将电压降低到接近 0.7 V 以用于计算 tile,并且每个计算 tile 必须在 base tile 中有自己的电源域。关键是新型高效电感器,称为同轴磁性集成电感器。因为这些都内置在封装基板中,所以在向计算 tile 提供电压之前,电路实际上在 base tile 和封装之间来回移动。
Gomes 表示,从 2008 年的第一台 petaflop 超级计算机到今年的 exaflops 用了 14 年,先进的封装技术如 3D 堆叠,将有助于提高计算能力。
原文链接:
https://spectrum.ieee.org/amd-3d-stacking-intel-graphcore























