今天,分享一篇谷歌版ChatGPT首秀“大翻车”,端掉了7000亿市值,希望以下谷歌版ChatGPT首秀“大翻车”,端掉了7000亿市值的内容对您有用。
来源:创业邦

作者丨VickyXiao
编辑丨VickyXiao
题图丨图虫创意
在试图追上微软和OpenAI在人工智能方面的先发优势时,谷歌自己搞砸了。
在今天谷歌在巴黎召开的发布会上,谷歌再一次展示了Bard——这款为了对抗ChatGPT推出来的聊天机器人。按照谷歌的宣传,Bard不仅要和ChatGPT一样有问必答,还要更“负责任”——暗搓搓地指ChatGPT里掺杂的虚假信息太多,不够“负责”。
这一宣传明显提高了人们对于Bard的期望值。毕竟在最初的惊艳过后,ChatGPT“一本正经”的胡说八道,也就是回答里夹杂的不少似是而非的伪信息,已经让很多人对于使用它提高了警惕,里面逻辑和数学上的错误更加惊人。
让人没想到的是,谷歌的Flag立得太早。Bard刚一亮相,就出错了——而且出了个大糗。
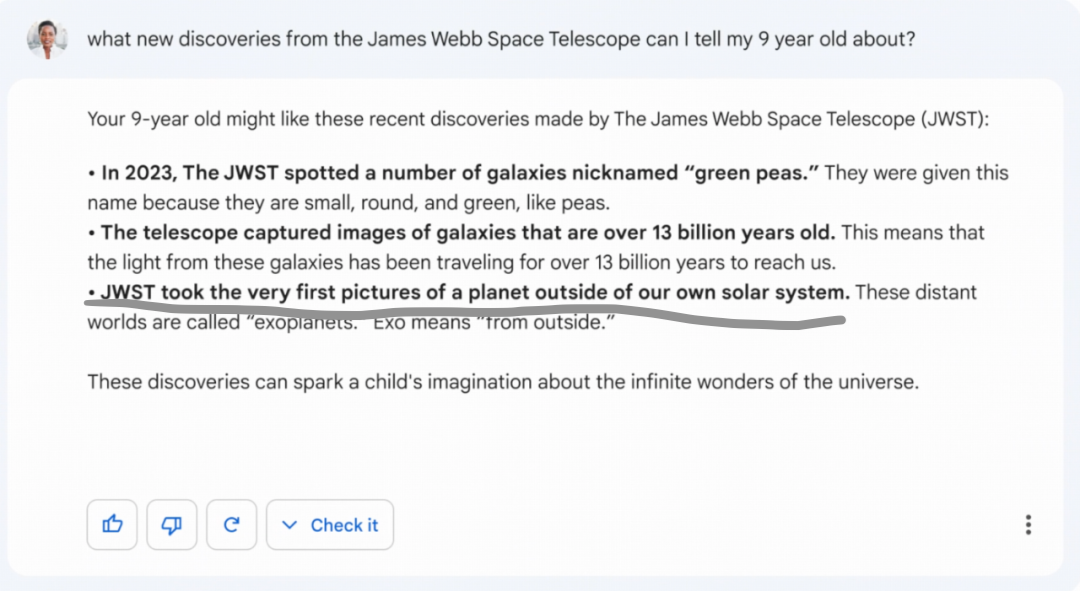
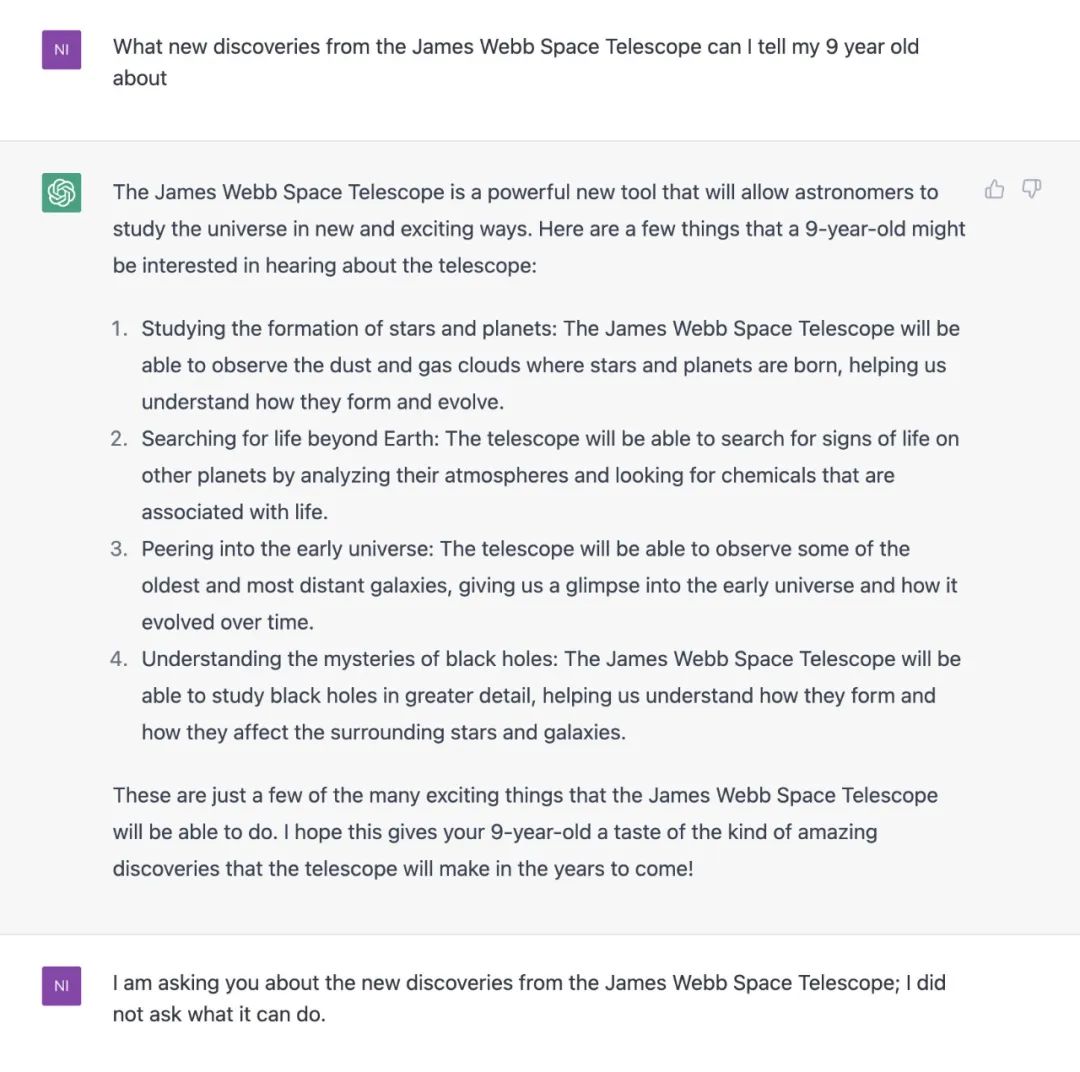
在谷歌短短的几秒展示里,Bard其实只被问了一个问题——“我可以告诉我 9 岁的孩子关于詹姆斯·韦伯太空望远镜(James Webb Space Telescope ,简称JWST) 的哪些新发现?”
Bard的回答很精彩——有丰富的信息,而且很形象的比喻,确实深入浅出地给孩子解释了JWST的发现。
然而,里面有一个巨大的错误:回答里提到“ JWST 拍摄到了太阳系外行星的第一张照片”,也就是下图灰线部分。
然而,事实上,第一张系外行星照片是由欧洲南方天文台的Very Large Telescope (VLT) 在 2004 年拍摄的。
 图源:谷歌
图源:谷歌最先指出这个错误的是天体物理学家 Grant Tremblay。
他在推特上写道:“我不是要成为一个讨厌鬼,我相信 Bard 会令人印象深刻,但郑重声明:JWST 并没有拍下「我们太阳系外行星的第一张图片」。”
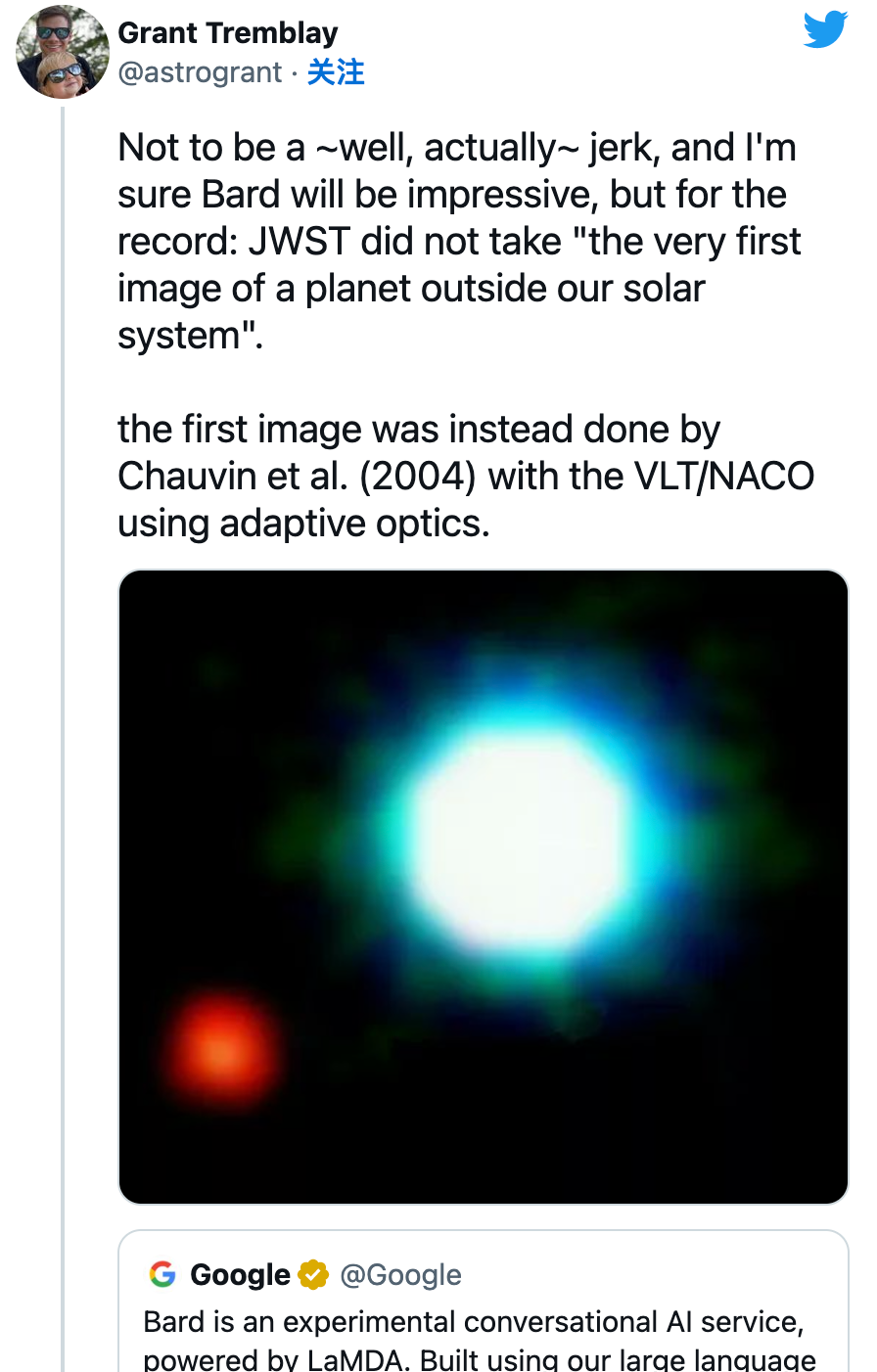 图源:Twitter
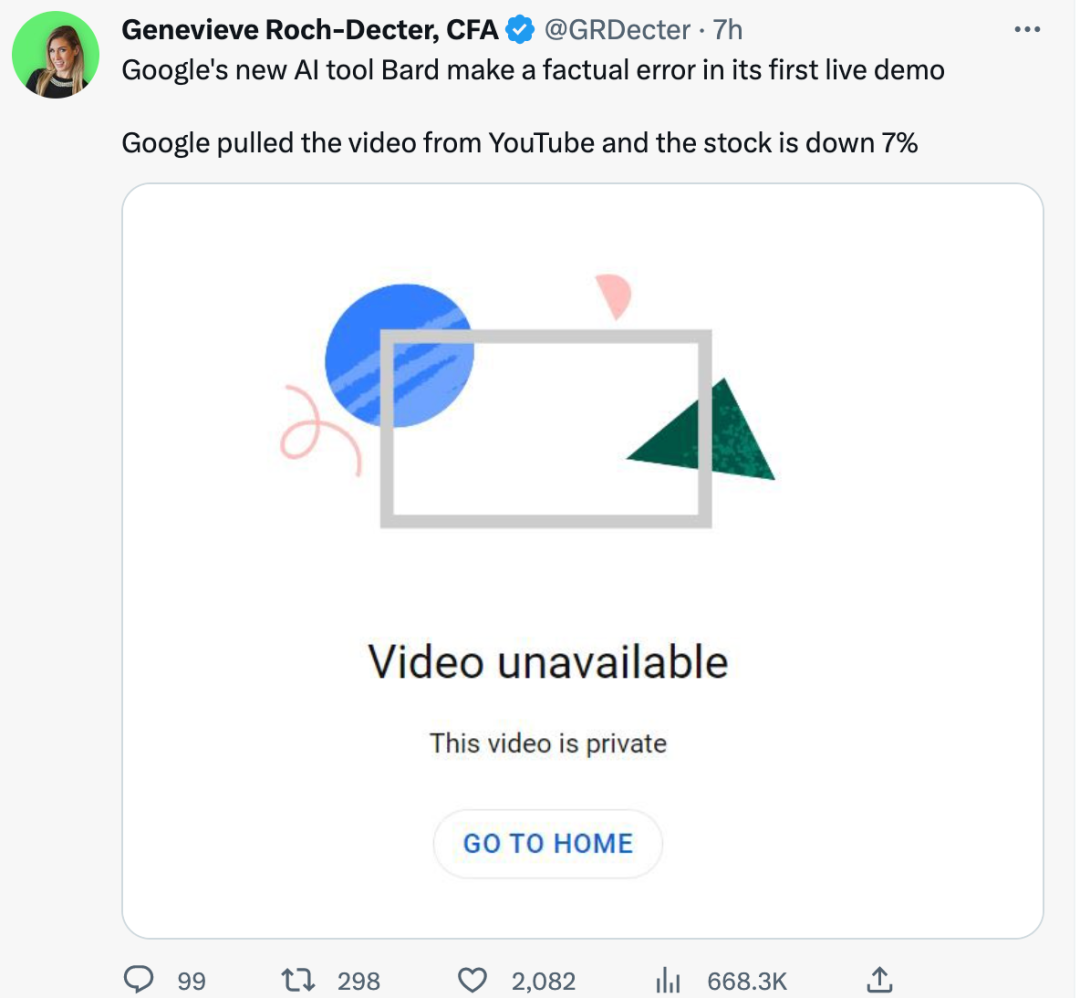
图源:Twitter在唯一的一次演示里,就犯了这么大的错误,谷歌可以说颜面尽失,不得不快速撤下了相关演示的YouTube视频。不过不少官方宣传推文里的演示动图还在。
AI犯错不可怕,正如前文所说的,ChatGPT上同样充斥着大量似是而非的虚假信息,而且比较来说,对于同样一个问题,ChatGPT的回答并不好,它只能回答出来JWST能做一些什么,而没有办法回答它的新发现,更不用说以一种小孩更能理解的通俗易懂的方式来解释。
 图源:Twitter
图源:Twitter但是在谷歌这么关键的产品的首次公开亮相上,这样明显的事实错误,却通过了层层审核,被批准放上了CEO的案头、大幅宣传——这一点,却明显让人感觉到谷歌员工的麻痹大意。
有谷歌员工表示,谷歌这两年的各种活动往往追求市场宣传效果,放放产品视频就好,没有上真产品的,就算上了真产品,也不用好好测试,不管到时候展示结果如何,哪怕实际产品越来越烂,只要PR做好了就好了。“产品和运营都麻痹了,太缺乏实战经验了,总有一天要出糗。只是没料到在跟微软硬抗的时候掉链子。真是天意。”
而在ChatGPT的步步紧逼下,谷歌管理层也失去了方寸。正如此前所说,这次Bard的发布有点赶,在内部算不上完全准备好,所以才以面向有限开发者的形式推出。这种情况下出现错误,也就情有可原了。
但这个错误的代价就是,投资人失去了信心。消息一传出,谷歌股价大跌9%,一天就丢了1000亿美元的市值。
1000亿美元,可以说,这是AI到目前为止犯下的最昂贵的一个错误。有网友很悲观地预计,“Bard会不会又是下一个Google+、Stadia、Wave等等等等?真是想不到,谷歌甚至没有办法对自己的宣传材料进行事实核查。”
也有推特网友评价说,这也正是如今的AI研究和语言模型共有的问题:它们非常擅长生成「看起来」准确的,但其实并不准确的信息。概括来说,他们就是很牛的扯淡人。

在后续推文中,Tremblay 也补充道:“我非常喜欢并感谢地球上最强大的公司之一正在使用 JWST 搜索来宣传他们的 LLM(大语言模型)。棒棒哒!但是 ChatGPT 等等这些,虽然令人印象深刻,但通常*非常自信*地犯错。如果未来看到LLM 进行自我错误检查将会很有趣。”
正如 Tremblay 所指出的,ChatGPT 和 Bard 等 AI 聊天机器人的一个主要问题是它们倾向于自信地将不正确的信息陈述为事实。这些系统经常“产生幻觉”,即编造虚假信息,因为他们只是接受大量文本语料库的训练,但并不是查询已经过验证的事实的数据库来回答问题。这导致一位著名的 AI 教授将它们称为“扯淡生成器”。
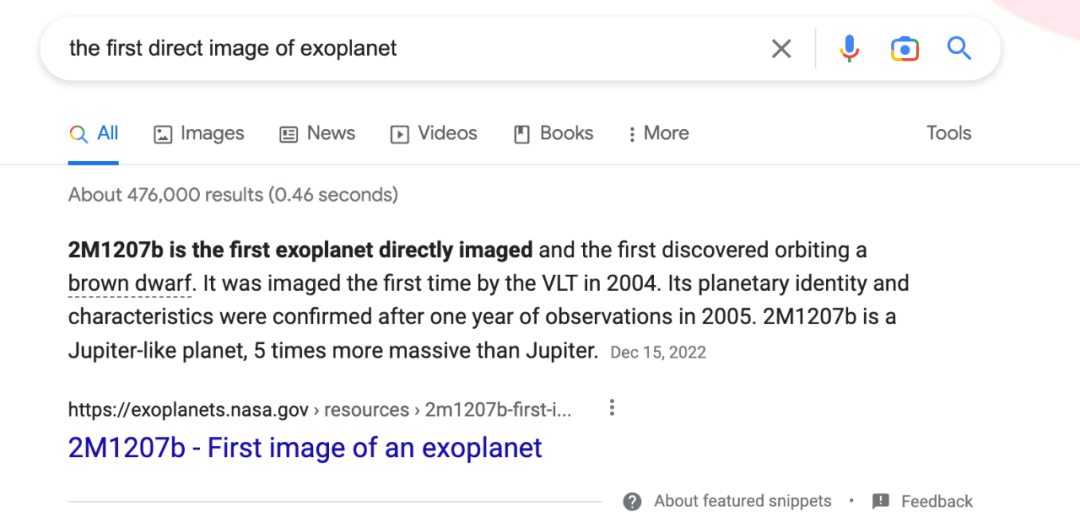
很明显的一个例子就是,对于Bard犯错的这个问题,其实Google搜索已经给出了正确答案。
如果你在Google上搜索“太阳系外行星的第一张图片”,Google自己就给出了准确信息——它是在2004年由VLT第一次捕捉成像。
微软已经预见到了这样的事情发生。它昨天演示了集成了ChatGPT的人工智能Bing搜索引擎,就试图通过把责任丢给用户来避开同样的这些问题。它在免责声明里称,“Bing 由 AI 提供支持,因此可能会出现意外和错误。请确保进行事实核查并分享反馈,以便我们学习和改进!”
在周一官宣Bard发布的博文里,CEO 皮柴特别强调,谷歌希望通过这一阶段的测试,来提高 Bard 的质量和速度,确保 Bard 的回答达到高标准。
然而,在这个望远镜乌龙事件后,谷歌发言人不得不强行挽回一点颜面。他们告诉媒体称:
“这凸显了严格测试过程的重要性,我们本周将通过 Trusted Tester 计划启动这一过程。我们会将外部反馈与我们自己的内部测试相结合,以确保 Bard 的回应在质量、安全性和现实世界信息的基础性方面达到高标准。”