今天,分享一篇让PyTorch创始人直呼「Amazing」的视频「脑补」,动态场景NeRF合成速度提升百倍,希望以下让PyTorch创始人直呼「Amazing」的视频「脑补」,动态场景NeRF合成速度提升百倍的内容对您有用。
选自arXiv
作者:Ang Cao等
机器之心编译
编辑:袁铭怿
来自的密歇根大学的研究者提出了「HexPlane」,一种能高效合成动态场景新视图的方法。该研究引起了 PyTorch 创始人 Soumith Chintala 的关注。
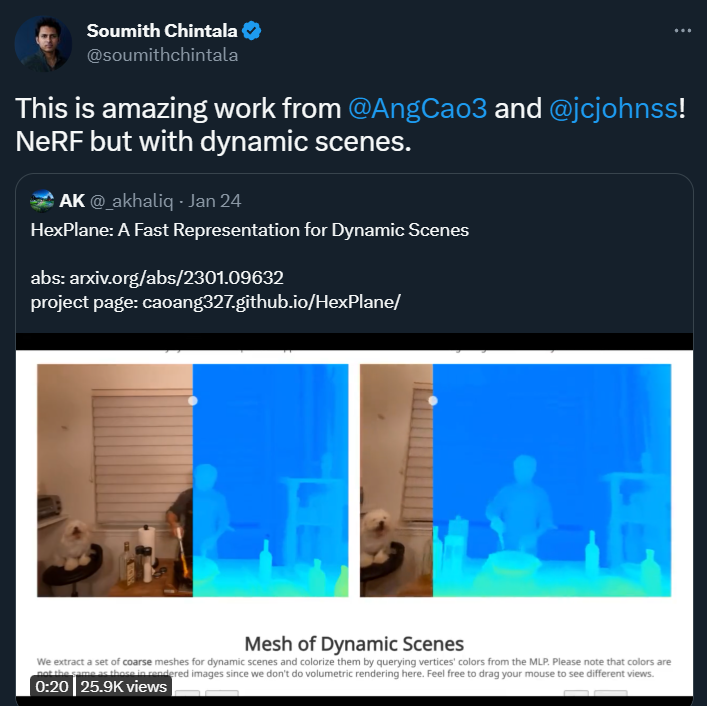
从一组 2D 图像中重建和重新渲染 3D 场景,一直是计算机视觉领域的核心问题,它使许多 AR/VR 应用成为可能。过去几年,重建静态场景方面取得了巨大的进展,但也存在局限性:现实世界是动态的,在复杂场景中,运动应是常态的,而非例外情况。
目前许多表征动态 3D 场景的方法都依赖于构建在 NeRF 基础上的隐式表征。他们训练了一个大型多层感知器(MLP),该感知器可以输入点在空间和时间上的位置,并且输出点的颜色或标准静态场景的形变。任何情况下从新视图渲染图像都是耗资巨大的,因为每个生成的像素都需要许多 MLP 来进行计算。训练进程同样也是缓慢的,需要长达数天的 GPU 时间来建模动态场景。这样的计算瓶颈阻碍了相关方法的广泛应用。
通过使用显式混合的方法,最近的几种静态场景建模方法已经实现了比 NeRF 更大的、速度方面的提升。这些方法使用显式空间数据结构,存储显式场景数据或特征,由小型 MLP 解码。这将模型的容量与其速度解耦,并可以实时渲染高质量的图像。不过这些方法虽然有效,但目前只能应用于静态场景。

论文链接:https://arxiv.org/pdf/2301.09632.pdf
项目地址:https://caoang327.github.io/HexPlane/
在最近的一篇论文中,密歇根大学的研究者 Justin Johnson、Ang Cao 为动态 3D 场景设计了显式表征,取得了类似静态场景层面的进展。他们设计了一个存储场景数据的时空数据结构,其中必须克服两个关键的技术挑战:首先是内存使用。研究必须模拟空间和时间中的所有点;在密集的 4D 网格中存储数据将以网格分辨率的四次方进行缩放,这对于大场景或长时间持续是不可行的。其次是稀疏观测。在静态场景中移动单个摄像机可以获得密集覆盖场景的视图;相比之下,在动态场景中移动相机每个时间步只能提供一个视图。单独处理时间步可能无法提供高质量重建的场景覆盖,因此必须实现跨时间步共享信息。
研究者采用新式的 HexPlane 架构克服了这些挑战。受静态场景因子表征的启发,HexPlane 将一个 4D 时空网格分解为跨越每对坐标轴(例如 XY, ZT)的六个特征平面。HexPlane 通过将一个 4D 时空点投影到每个特征平面上,聚合六个结果特征向量来计算时空点的特征向量。然后将融合的特征向量传递给一个小型 MLP,该 MLP 预测点的颜色;之后可以通过体渲染来渲染新视图。
HexPlane 很简洁,且为上述挑战提供了一个巧妙的解决方案。由于它的因子化表征,HexPlane 的内存占用的空间只与场景分辨率成四等分。此外,每个平面的分辨率可以独立调整,以适应需要空间和时间可变容量的场景。由于一些平面仅依赖于空间坐标(例如 XY),通过构建 HexPlane,可以促进不相交的时间步长之间的信息共享。
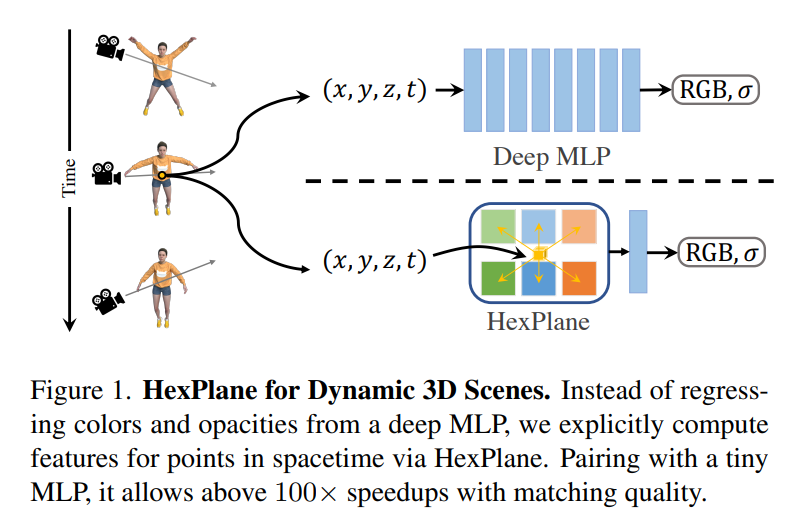
实验结果表明,HexPlane 是一种能高效合成动态场景新视图的方法。研究者在 Plenoptic 视频数据集上匹配了先前工作的图像质量,但将训练速度提高了 100 多倍;该方法也在单目视频数据集上优于先前所采用的方法。多项消融实验验证了 HexPlane 设计的合理性,并证明了它对不同的特征融合机制、坐标系(矩形与球面)和解码机制(球面谐波与 MLP)具有鲁棒性。

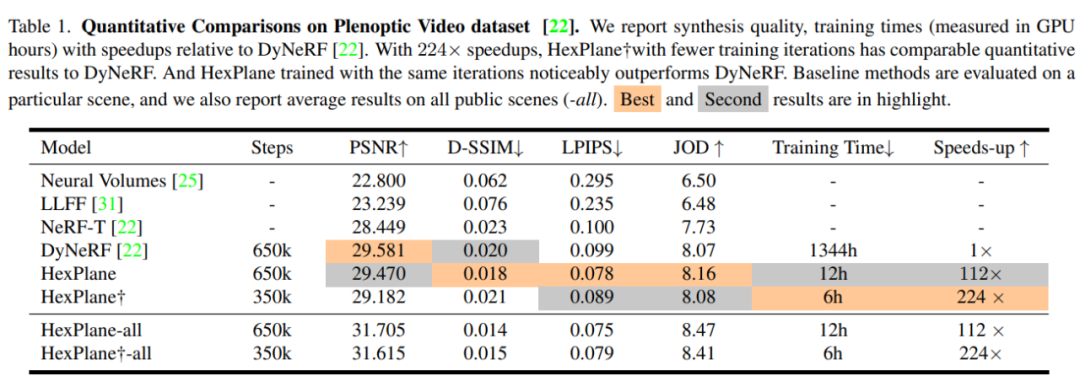
此前基于 MLP 的方法需要超过 1400 GPU 小时进行单个视图训练,而该方法在 10 小时内以相同的质量完成训练,加速超过 100 倍。
HexPlane 是一种简单、明确、通用的动态 3D 场景表征。它对底层场景做的假设最少,并且不依赖于变形场或特定类别的先验。除了改进和加速视图合成外,HexPlane 有望能在动态场景的广泛研究中发挥作用。
方法概述
在给定一组动态场景的姿势和时间戳图像的前提下,研究者的目标是让模型适应场景,从而能以新的姿势和时间渲染新图像。像 NeRF 一样,模型给出时空点的颜色和不透明度;图像是通过沿射线的可微体积渲染来呈现。该模型使用渲染图像和 ground-truth 图像之间的光度损失进行训练。
本文的主要贡献在于新动态 3D 场景的显式表征,研究者将其与小型隐式 MLP 相结合,从而在动态场景中实现新的视图合成。输入时空点用于有效地查询特征向量的显式表征。一个小型 MLP 接收特征以及点坐标和视图方向,并为点返回输出 RGB 颜色。模型概述见图 2。
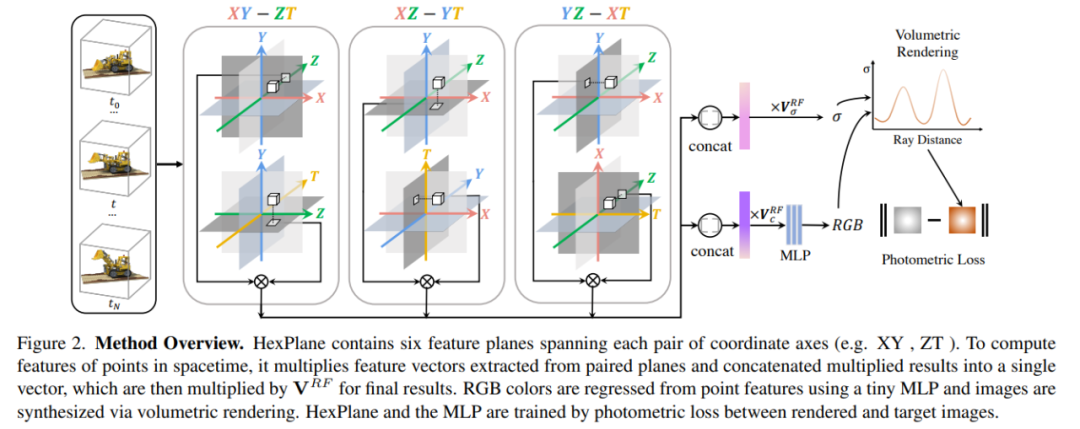
为动态 3D 场景设计显式表征存在一定的挑战。静态 3D 场景通常由点云、体素或网格建模,动态场景的显式表征尚未得到充分探索。该研究展示了如何通过简单的 HexPlane 表征来克服内存使用和稀疏观测的关键技术挑战。
实验结果
动态新视图综合结果
如图 3 所示,HexPlane 可以跨时间和视点给出高质量的动态的、新颖的视图合成结果。
与其他 SOTA 方法的定量对比见表 1。
鉴于 DyNeRF 的模型未公开,因此很难直接比较可视化结果。本文从原论文中下载图像,并在检索结果中找到了最匹配的图像,如图 4 所示。

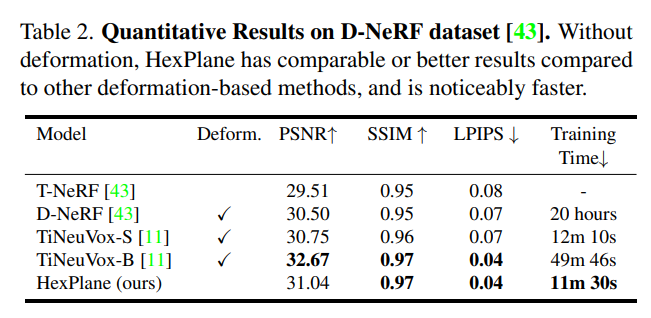
D-NeRF 数据集的定量结果如表 2 所示:
消融和分析
研究者还比较了 HexPlane 与表 3 中方法提到的部分其他设计:

HexPlane 的对称性极佳,包含所有的坐标轴对。研究者通过打破这种对称性计算了表 4 中的其他变体。
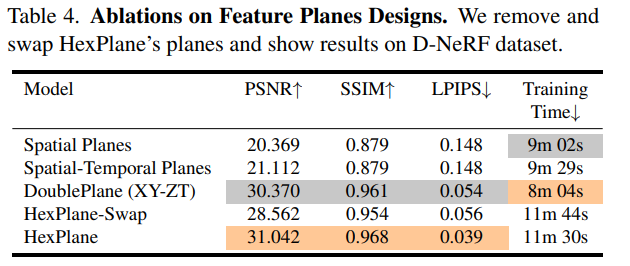
表 5 和图 5 都表明,Multiply-Concat 并不是唯一可行的设计。Sum-Multiply 和它的交换版本 Multiply-Sum 产出的结果也都不错,尽管不是最优的,这也表明了乘法和加法之间的对称性。
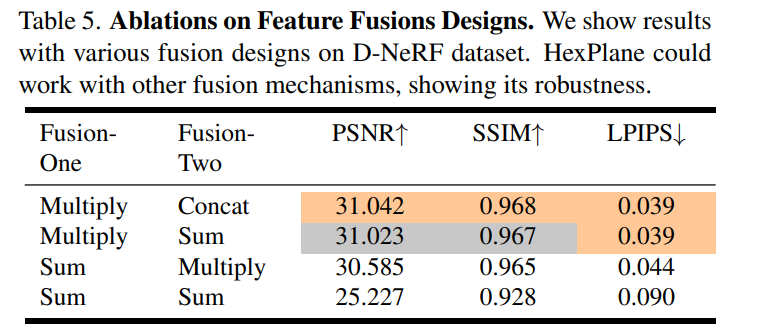
 图 6 中显示了不同时空网格分辨率的定性结果:
图 6 中显示了不同时空网格分辨率的定性结果:
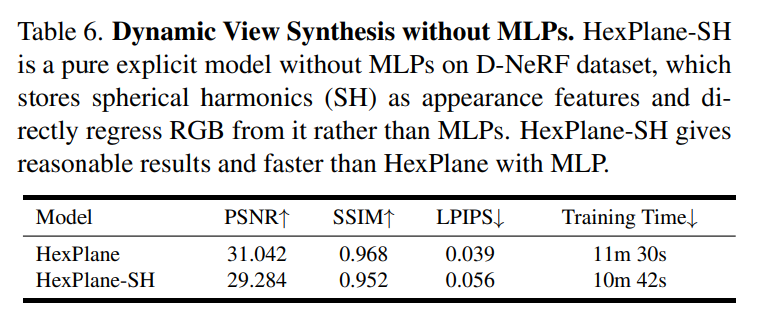
表 6 展示了在没有 mlp 的情况下,研究对纯显式模型的评估:
无界场景的重新参数化
图 7 展示了使用小 x, y 边界的 NDC 的 HexPlane 在极端视图下的合成结果,无法对边界附近或边界外的对象建模。

查看真实视频的合成结果
研究者采用 iPhone 拍摄的单目视频来测试 HexPlane,其相对随意的摄像轨迹更接近真实的用例。具体合成结果见图 8。

更多研究细节,可参考原论文。























