来自清华大学的研究者基于可重构数字存算一体架构,设计了国际首款面向通用云端高算力场景的存算一体AI芯片ReDCIM。
被誉为“集成电路奥林匹克”的国际固态电路会议ISSCC,今年从全球12个领域共录用论文200篇,中国大陆及港澳地区入围的论文共30篇,其中清华大学集成电路学院发表的基于可重构数字存算一体架构设计的国际首款面向通用云端高算力场景的存算一体AI芯片ReDCIM(Reconfigurable Digital CIM)成果论文,引起广泛关注。

论文地址:https://ieeexplore.ieee.org/document/9731762
该论文的第一作者是涂锋斌博士,尹首一教授是论文的通讯作者,加州大学圣塔芭芭拉分校谢源教授为论文共同作者。
清华大学集成电路学院魏少军教授、尹首一教授团队提出的可重构数字存算一体架构(如图 1所示)可兼顾算力、精度、能效和灵活性,首次在存算一体架构上实现了高精度浮点与高精度整数计算,可满足数据中心级的云端AI推理和训练需求。
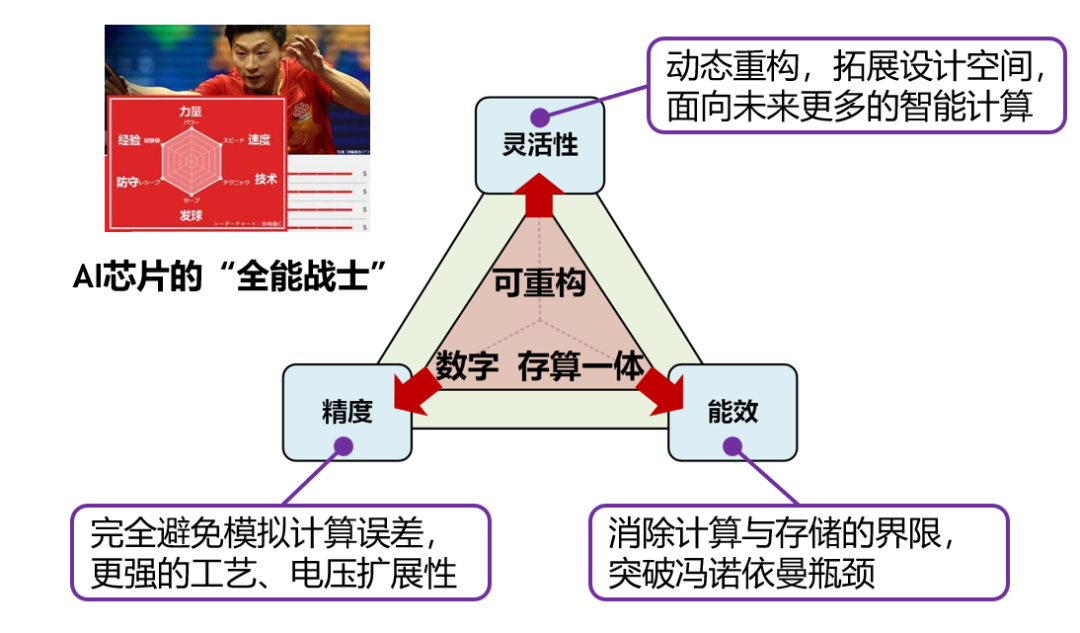 图 1:高算力AI芯片新范式:可重构数字存算一体架构,兼顾能效、精度和灵活性。
图 1:高算力AI芯片新范式:可重构数字存算一体架构,兼顾能效、精度和灵活性。随着人工智能(Artificial Intelligence, AI)技术的发展,模型规模不断增加,带来巨大的算力和存储需求。大量频繁的访存使得AI芯片的能效严重受限于冯诺依曼瓶颈问题。存算一体(Compute-In-Memory,CIM)架构可直接在存储器内完成计算,消除了计算和存储间的频繁访问,被认为是一种能够突破冯诺依曼瓶颈的高能效AI计算架构。
然而,目前大多数存算一体AI芯片基于模拟计算原理设计,模拟计算误差限制了计算精度,固定的存算通路限制了功能灵活性。这使得模拟存算一体架构只适合计算精度要求不高、功能灵活性要求不高、更注重低功耗的边缘端AI场景,而不适合对算力、能效、精度和灵活性同时具有很高要求的云端AI场景。随着高精度大规模AI模型不断涌现,在数据中心等云端AI场景进行训练和推理的算力需求日益增长。因此云端AI芯片的研究极具前景,亟需革新的AI芯片计算范式。
存算一体架构可突破冯诺依曼瓶颈,提高AI芯片能效
近年来,学术界和工业界推出大量基于数字架构的AI芯片[2-4]以满足日益增长的AI算力需求。这类AI芯片的典型架构如图 2 (a)所示,由分离的计算单元和存储器构成:计算单元主要处理AI算法中核心的乘加计算,存储器缓存输入数据、输出数据和AI模型权重。为满足越来越复杂的AI任务需求,AI模型尺寸不断增加。因此在AI计算过程中,计算单元会频繁访问存储器中的数据,使得访存主导AI芯片整体延迟和能耗,严重制约AI芯片的能效。这就是AI芯片的冯诺依曼瓶颈问题。
存算一体架构消除了计算与存储的界限,直接在存储器内完成计算,被认为是突破冯诺依曼瓶颈的极具潜力的高能效AI芯片架构。目前大多数存算一体AI芯片基于模拟计算原理设计,其典型架构如图 2(b)所示。模拟存算一体架构通常基于SRAM[5-7]或非易失存储器[8, 9],模型权重保持在存储器中,输入数据流入存储器内部基于电流或电压实现模拟乘加计算,并由外设电路对输出数据实现模数转换。由于模拟存算一体架构能够实现低功耗低位宽的整数乘加计算,它们非常适合边缘端AI场景。
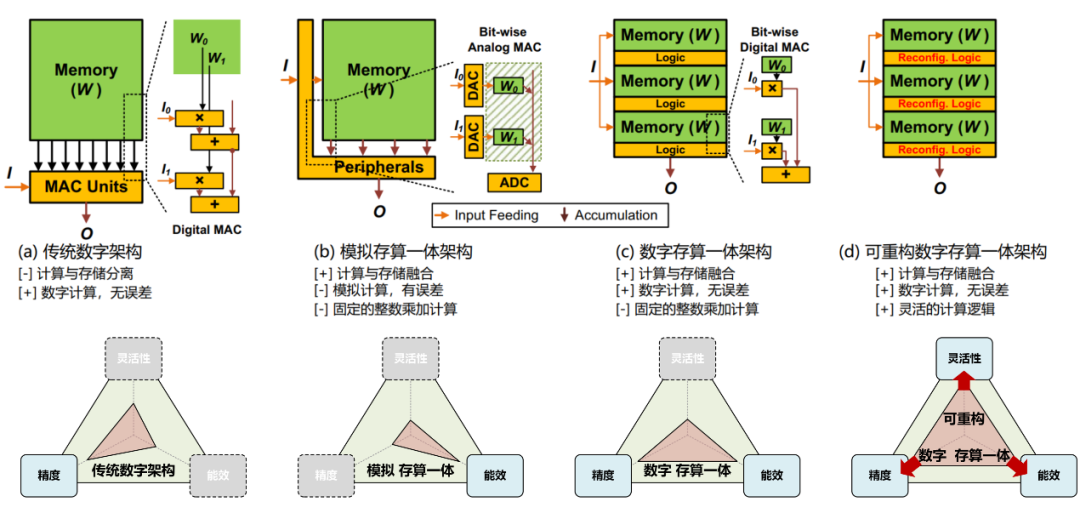
图 2:AI芯片架构对比:(a)传统数字架构,(b)模拟存算一体架构,(c)数字存算一体架构,(d)可重构数字存算一体架构。
模拟存算一体架构难以兼顾能效、精度和灵活性,不适合云端AI芯片
随着AI任务的复杂性和应用范围增加,高精度的大规模AI模型(如BERT,GPT-3等)不断涌现。这些模型需要在数据中心等云端AI场景完成训练和推理,产生巨大的算力需求,同时冯诺依曼瓶颈问题也更加严重。相比于边缘端AI场景,云端AI场景具有更多样的任务需求,如图 3所示,除了需要支持高能效的低位宽整数(INT8)AI推理任务,还需要支持高精度的AI推理和训练任务。因此,云端AI场景需要更高位宽的整数(如INT16)和浮点计算(如BF16、FP32)能力,以保证各种大规模AI推理和训练没有精度损失[4]。综上,云端AI芯片设计必须兼顾能效、精度和灵活性。
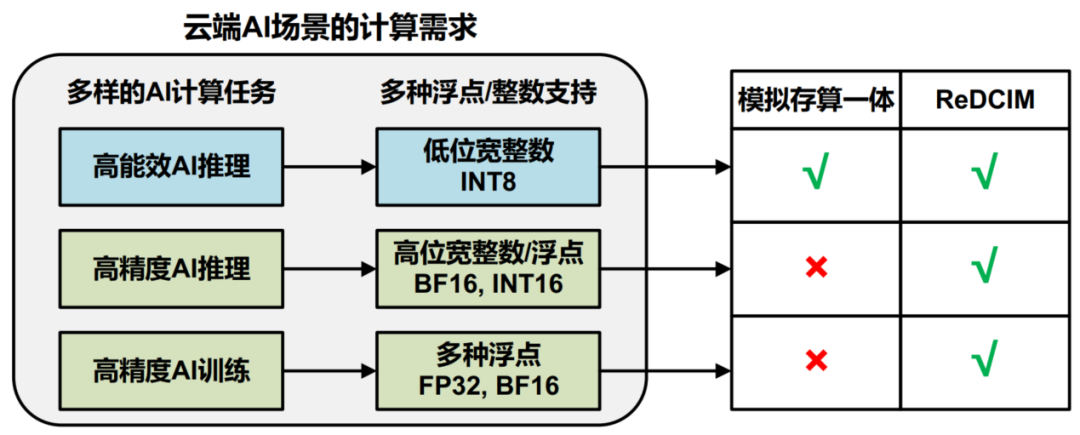 图 3:云端AI场景的计算需求:高能效、高精度和高灵活性。
图 3:云端AI场景的计算需求:高能效、高精度和高灵活性。尽管存算一体能够通过突破冯诺依曼访存瓶颈以实现高能效AI计算,但目前主流的模拟存算一体架构还无法同时兼顾精度和灵活性需求,制约了它们在云端AI场景的使用:1)模拟计算由于工艺偏差、信号噪声等因素容易产生计算误差,通常最高只能支持INT8数据格式,难以支持更高位宽计算[5-9];2)由于同时激活整个存储器阵列会产生较大计算误差,当前的模拟存算一体AI芯片通常只能同时激活很小部分存储器阵列[5-9]。这限制了它们单位面积下的计算能力,使得兼顾能效和精度变得更加困难;3)如图 2(b)所示,模拟数据通路形成了固定的存算架构,限制了它们在功能上只能实现整数乘加计算,难以灵活支持各种浮点和整数计算。
高算力AI芯片新范式:可重构数字存算一体架构
清华大学集成电路学院魏少军教授、尹首一教授团队首次探索了存算一体在云端AI场景下的架构设计问题,提出可重构数字存算一体架构AI芯片,将可重构计算与数字存算一体架构融合,兼顾能效、精度和灵活性,设计出国际首款面向通用云端场景的存算一体AI芯片ReDCIM。如图 1所示,数字存算一体架构是兼顾能效和精度的关键,可重构计算架构保障了AI芯片的可编程灵活性。
数字存算一体架构是当下正在兴起的一种新型存算一体架构。TSMC连续两年(2021,2022)在ISSCC上发布基于SRAM的数字存算一体芯片[10, 11]。相比于模拟存算一体架构,数字存算一体架构在存储器内实现纯数字逻辑(如图 2(c)所示),完全避免模拟计算导致的计算误差,可同时激活全部存储器阵列,具有更高的能量效率和面积效率,以及更好的工艺和电压扩展性[11]。但是,受限于固定的存算通路,TSMC的两款数字存算一体芯片仍只能支持整数乘加计算。
可重构计算架构是一种兼顾能效和灵活性的计算架构。魏少军教授、尹首一教授团队近年推出的Thinker系列AI芯片均基于此架构。Thinker系列芯片具有实时重构能力,能够在线配置成不同数据通路以满足多样的任务需求。
数字存算一体架构不同于模拟存算一体架构,其数字逻辑具备极强的可定制性。将原本固定的数字存内逻辑改造成可重构逻辑,就能融合数字存算一体和可重构计算各自的优点,兼顾能效、精度和灵活性。基于以上思路,研究团队提出了可重构数字存算一体架构(如图 2(d)所示):在SRAM内实现可重构数字逻辑,既避免了模拟计算导致的计算误差,又能在同一存储器中灵活支持多种浮点和整数计算。
首款面向通用云端场景的存算一体AI芯片ReDCIM
基于可重构数字存算一体架构的云端AI芯片ReDCIM使用28nm CMOS工艺成功流片,其研究成果发表于ISSCC’2022。如图 4所示,ReDCIM由16个CIM核,32KB全局缓存,1个SIMD核和顶层控制器构成。它具有以下三大关键技术点:
1) ReDCIM采用无存内对齐的浮点乘加流水线架构,来分离浮点乘加计算中的指数对齐和尾数乘加。由于输入和权重都对齐到了局部最大指数,存储器内部只需进行乘加计算而不用实现复杂的对齐逻辑。
2) ReDCIM采用比特级存内Booth乘法架构来优化存内乘加计算。相比于传统的顺序比特流存内乘加计算架构,该架构可以把计算周期和比特级乘法量降低近50%。
3) ReDCIM采用层次化可重构存内累加架构,在同一个CIM单元内灵活支持多种浮点(BF16、FP32)和整数(INT8、INT16)计算能力,满足云端AI计算需求。
ReDCIM在设计上引入了近存和存内两个层次的可重构计算:技术1中的前置对齐单元属于近存重构逻辑。它可以改变输入数据的预处理流程,实现不同的浮点模式和整数模式。技术2中的部分积重编码和技术3中的部分积累加共同构成了存内重构逻辑。它们可根据具体的数据格式实现存内移位、符号位扩展、有/无符号加减等计算操作。
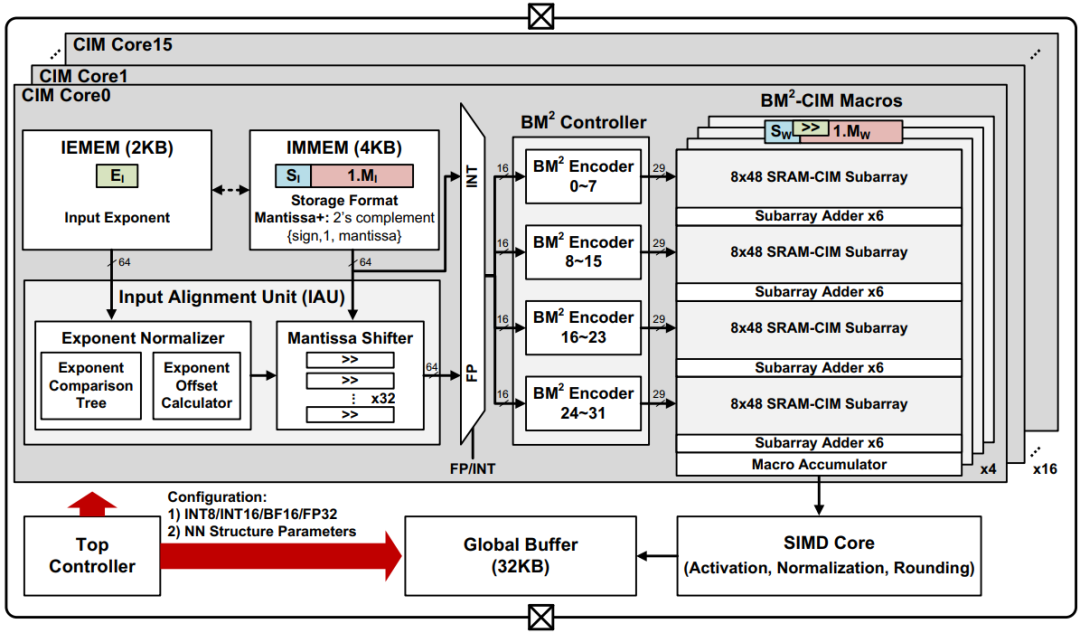 图 4:ReDCIM芯片的整体架构。
图 4:ReDCIM芯片的整体架构。ReDCIM芯片的显微照片和硬件指标如图 5所示。该芯片在ImageNet数据集上分别使用INT8、BF16和FP32数据格式,进行ResNet-50推理、EfficientNet-B0推理和EfficientNet-B0训练三个实验,相比于IBM在ISSCC’2021发布的云端AI芯片架构[4]可分别获得11.61、8.92和9.86倍的能效提升。ReDCIM芯片首次在存算一体架构上支持高精度浮点与整数计算,可达到29.2TFLOPS/W的BF16浮点能效和36.5TOPS/W的INT8整数能效,满足云端AI推理和训练等各种任务需求。
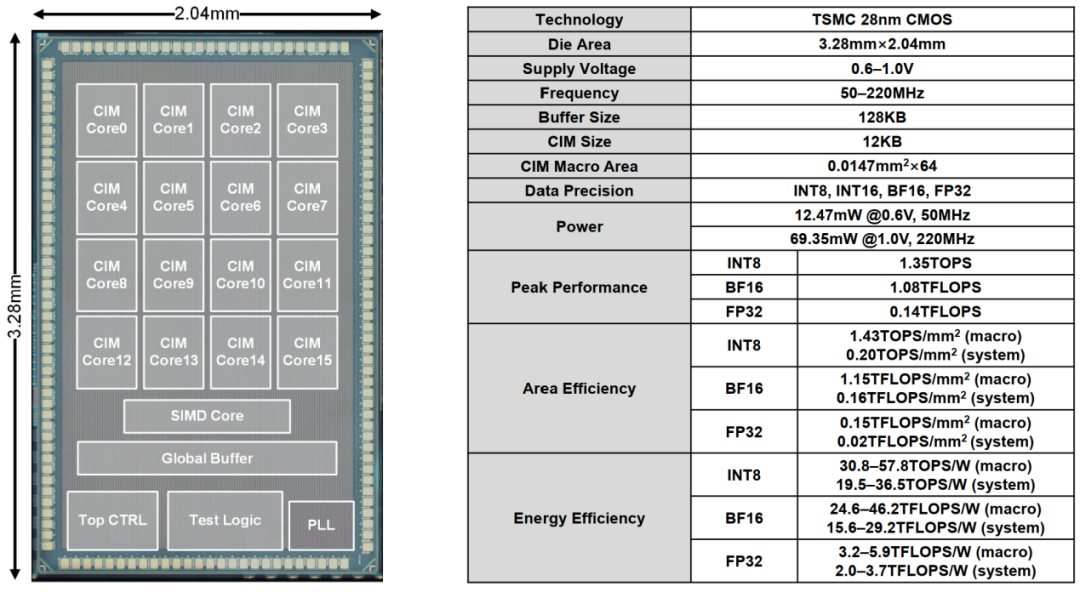 图 5:ReDCIM芯片的显微照片和硬件指标。
图 5:ReDCIM芯片的显微照片和硬件指标。可重构数字存算一体架构开辟了广阔的AI芯片设计空间
AI芯片发展至今,从数字架构到模拟存算一体,芯片架构更新换代。数字架构受限于冯诺依曼访存瓶颈,能效存在局限性。模拟存算一体因突破了冯诺依曼访存瓶颈而具有更高能效,但精度和灵活性欠佳。可重构数字存算一体架构融合了两大流派的优点,兼顾能效、精度和灵活性。可重构计算的引入大大拓展了传统存算一体架构的设计空间,让存算一体的功能不仅仅局限于整数乘加。可重构数字存算一体架构可适应未来更多人工智能计算场景需求,为AI芯片设计开辟了一条新技术路线。
参考文献
1.Tu, F., et al. A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 Reconfigurable Digital CIM Processor with Unified FP/INT Pipeline and Bitwise In-Memory Booth Multiplication for Cloud Deep Learning Acceleration. in 2022 IEEE International Solid- State Circuits Conference (ISSCC). 2022.IEEE.
2.Yin, S., et al., A High Energy Efficient Reconfigurable Hybrid Neural Network Processor for Deep Learning Applications.IEEE Journal of Solid-State Circuits, 2018. 53(4): p. 968-982.
3.Tu, F., et al., Evolver: A Deep Learning Processor With On-Device Quantization–Voltage–Frequency Tuning.IEEE Journal of Solid-State Circuits, 2021. 56(2): p. 658-673.
4.Agrawal, A., et al. A 7nm 4-Core AI Chip with 25.6TFLOPS Hybrid FP8 Training, 102.4TOPS INT4 Inference and Workload-Aware Throttling. in 2021 IEEE International Solid-State Circuits Conference (ISSCC). 2021. IEEE.
5.Yue, J., et al. A 2.75-to-75.9TOPS/W Computing-in-Memory NN Processor Supporting Set-Associate Block-Wise Zero Skipping and Ping-Pong CIM with Simultaneous Computation and Weight Updating. in 2021 IEEE International Solid-State Circuits Conference (ISSCC). 2021. IEEE.
6.Su, J.-W., et al. A 28nm 384kb 6T-SRAM Computation-in-Memory Macro with 8b Precision for AI Edge Chips. in 2021 IEEE International Solid-State Circuits Conference (ISSCC). 2021. IEEE.
7.Guo, R., et al. A 5.99-to-691.1TOPS/W Tensor-Train In-Memory-Computing Processor Using Bit-Level-Sparsity-Based Optimization and Variable-Precision Quantization. in 2021 IEEE International Solid-State Circuits Conference (ISSCC). 2021. IEEE.
8.Xue, C.-X., et al. A 22nm 4Mb 8b-Precision ReRAM Computing-in-Memory Macro with 11.91 to 195.7TOPS/W for Tiny AI Edge Devices. in 2021 IEEE International Solid-State Circuits Conference (ISSCC). 2021. IEEE.
9.Xue, C.-X., et al. A 22nm 2Mb ReRAM Compute-in-Memory Macro with 121-28TOPS/W for Multibit MAC Computing for Tiny AI Edge Devices. in 2020 IEEE International Solid-State Circuits Conference (ISSCC). 2020. IEEE.
10.Chih, Y.-D., et al. An 89TOPS/W and 16.3TOPS/mm2 All-Digital SRAM-Based Full-Precision Compute-In Memory Macro in 22nm for Machine-Learning Edge Applications. in 2021 IEEE International Solid-State Circuits Conference (ISSCC). 2021. IEEE.
11.Fujiwara, H., et al. A 5-nm 254-TOPS/W 221-TOPS/mm2 Fully-Digital Computing-in-Memory Macro Supporting Wide-Range Dynamic-Voltage-Frequency Scaling and Simultaneous MAC and Write Operations. in 2022 IEEE International Solid-State Circuits Conference (ISSCC). 2022. IEEE.
IJCAI 2022 - Neural MMO 海量 AI 团队生存挑战赛
4月14日,由超参数科技发起,联合学界MIT、清华大学深圳国际研究生院以及知名数据科学挑战平台 AIcrowd 共同主办的「IJCAI 2022-Neural MMO 海量 AI 团队生存挑战赛」正式启动。
本届赛事以「寻找未来开放大世界的最强 AI 团队」为主题,通过在 Neural MMO 的大规模多智能体环境中探索、搜寻和战斗,获得比其他参赛者更高的成就。比赛还设置新的规则,评估智能体面对新地图和不同对手的策略鲁棒性,在 AI 团队中引入合作和角色分工,丰富了比赛内容,增强了趣味性。






















