朱高峰
今年2月,国家发展改革委等部门联合印发文件,同意在京津冀等8地启动建设国家算力枢纽节点,并规划了张家口集群等10个国家数据中心集群。至此,“东数西算”工程正式全面启动。
“东数西算”有了总体布局设计并开始行动。因此,有必要对其概念内涵予以清晰科学的阐释,以免再现一哄而起的局面。
“东数西算”属于信息领域范畴,目标是形成一张算力网。当前我国已建成相当发达的现代信息网,比如通信网、互联网等,且形态、技术手段多样,发展速度远远快于其他领域。为什么又提出建算力网络呢?
这要从流通网络和数据谈起。在现代社会中,实现交换和分配就需要流通。流通不仅在点与点之间,而且在面上多个点之间进行,因此需要构建网络,以便经济有效、高效通畅地实现多点与多点之间的流通。
网的主要功能是流通,有针对实物的运输网、针对能量的电力网,而针对信息的就是通信网。当然,信息流通中个体间非经济范畴如情感、思想的交流大量存在,同样需要在流通网络中实现。
物体、能量和信息除了流通外,还需要加工变换等以满足人们的需要。比如,信息加工是在计算机或具有计算功能的各种设备中实现的。
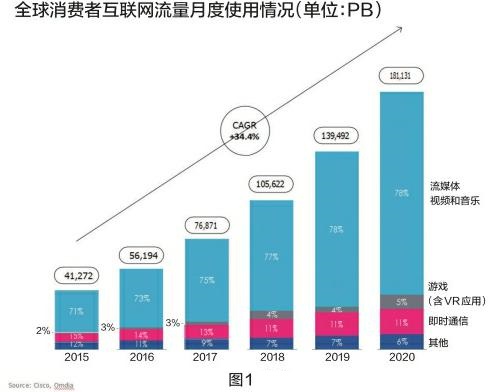
由于信息技术的快速发展,除了个人或集体产生的信息外,人们还可以从各种社会活动中提取各类信息。例如道路交通信息,从若干监测点获取的温湿度及其变化情况、气压、气流等天气信息,以及商店人流、各类商品销售信息等。为了便于收集处理大量信息,人们用统一的电子格式来表达,这就是数据。
近年来,人们从看起来互不相干的一大类数据中寻找其中的关联因素,发现这些数据之间并非因果关系,而是数学上的相关关系。由于此类数据量较大,称之为大数据。例如,从一段时间内通过某一路段的车辆或行人数,一段时间内进入某一商店购买某类商品的人数,以及组成人群的性别、年龄结构等数据集中找到的关系,可以作为道路交通管理或商品营销的一种依据。
而这种对各类数据加工处理、从中提取有用结果的能力,称为算力。大数据被发现以来,人们对算力的需求大幅增长。
此前,信息网络的主要功能为信息流通,辅之以短时存储,以及使信息变换形式适应在网络中传输的要求。这些功能的具体实现可以综合到通信网络中。这是因为,那时对复杂数据的加工处理往往是由单个计算机,包括高性能计算机或小范围的计算机群来实现的,数据量和处理量相对而言均不大。也因此没有单独明确提出算力及算力网的概念,只明确了计算机或其组成的群结构具有数据处理能力。
大数据出现后,由于对数据处理能力的要求大幅增长,且有些数据集来自于一定的地域范围,因此需要形成有别于通信网的数据处理专用网络,即算力网络。
算力网络的核心是数据处理设备,相应地要配置数据收集传送通道,以收集来自不同地域的数据,并配备相应的数据存储设备,以及把加工获得的有用结果传送至使用目的地的传送通道。
多个数据收集、传递、处理、应用与存储的单元组合在一起,就形成了算力网络。算力网络根据地域覆盖范围可形成区域网和全国网,之间可形成层级关系,也可按不同应用领域形成专用网。
回到“东数西算”工程。根据我国实际情况,人口密度、人类活动、各种数据资源以及数据应用市场在东部更集中,中部次之,西部地域再次之。既然数据资源和应用市场相对密集于东部,相应的处理也主要在东部,为何提出“东数西算”,即东部数据送到西部计算处理,再把结果送回东部应用呢?
“东数西算”与“西煤东运”“西电东送”有一致性,也有差异性。相同的是,它们都是从资源密集地把资源送到相对稀少地加工,不同的是加工后成品的处置问题。
对于物品和能量,资源所在地与主要应用所在地不同,加工地也可有不同选择。由于物品加工大多需要较复杂的技术和较高技术水平的人力,因此大多情况下将原材料从西部产地运到东部加工,然后成品大量在东部使用或出口,因此也形成了原料和成品的不同物流网络。能量则由于能源的形式不同,其利用方式也不同,如水能需要就地实现,然后传送至需能地区,而长距离传递主要方式是用电,因此就需要实行西电东送,从水能丰富的西部输送至需要大量能量的东部。
而信息具有特殊性,它可以大量复制,因此加工后的数据一般可存储在加工处,只是在使用时才传输到使用处。之所以实施“东数西算”工程,主要有两个因素。一是集中的数据加工/处理中心需要占用较大的物理空间,即土地和建筑,也需要较大的能耗。而东部的土地已经成为稀缺资源,能耗成本比西部高出不少。此外,数据中心自动化程度很高,所需人力相对较少。二是加工后的数据虽然大量返回东部使用,但数据作为信息可大量复制,近乎零成本,所以数据送回东部并非实物返回,而是只选择所需要的数据以复制形态返回,原数据仍保存在西部数据中心,继续按需随时向不同地点输送。因此,“东数西算”在原则上是可行的。
但原则上可行并不意味着怎么做都行,我们需要重视一个问题,即数据长距离传输成本。一方面数据可以近零成本大量复制并不等于可以无成本任意传输。另一方面,数据传到某处实时使用,与先存储以备之后使用是两回事,存储是需要成本的。
信息网络组成中的主要问题之一就是传输成本和处理成本的相对关系。近年来,处理成本(即计算机成本)随着集成电路的摩尔定律不断下降,传输成本随着光纤定律下降,但由于光纤成本下降速度比集成电路成本快,传输在网络成本中的相对比重也一直下降,但下降并不等于零成本。
“东数西算”工程是以增加传输量来节约数据加工成本的,因此,必须根据具体情况对成本进行详细分析和具体设计。然而,目前尚未见到对此问题的分析,甚至很少提到。
过去的教训应吸取。比如刚提出“云计算”概念时,人们认为把各个点上的小规模数据处理和存储集中到一个点,即云中,可以发挥规模效应,省去大量设点的成本,但并未认真考虑传输成本、信息保密等问题。因此,后来又提出并推行了“边缘计算”。大量分散的边缘计算和集中的云计算共同组成一个较为合理的体系。
数据量的问题也应得到重视。数据量并非越大越好,应以够用为原则,且在满足目标情况下越小越好,这与节材节能意义相通。此外,相关关系类的数据中有用成分比因果关系类数据少得多,因此,设计算力网络时,要对所处理的数据种类和数量进行实事求是、合理的预估。
从全国来看,数据处理网络的组成、不同地区的需求各有差异,对全国性、地区性、行业性的数据需求、集中程度也不同,比如同是东部地区,京津冀、长三角、珠三角情况并不一样。此外,各地对数据中心建设、维护能力也不同,要考虑人力资源情况。
因此,在实际操作中,需要仔细分析考虑,对已有一定实践的如贵州数据中心建设等应认真总结、吸取经验和教训,推动我国数据事业更好、更顺利地发展。(作者系中国工程院院士)