今天,分享一篇B站UP主硬核自制智能音箱有ChatGPT加持,才是真・智能,希望以下B站UP主硬核自制智能音箱有ChatGPT加持,才是真・智能的内容对您有用。
在大型语言模型的加持下,智能音箱领域的「拐点」即将到来?
在智能音箱风靡的那些年,很多人都希望能与音箱来一场深度对话。可惜事与愿违,智能音箱的对话能力显然达不到人类的要求。如今,智能音箱的市场红利期已经过去,昔日光环消退,渐渐不再为人提起。
一位名为「GPTHunt」的 Up 主也是一样,自述是智能语音音箱的「轻度爱好者」。只是失望的次数太多了,也就不再抱有希望。
比如,他买过亚马逊的 Alexa 音箱,但发现自己英语水平不太够,此外音箱产品设计也不够 local,试用了一阵就弃坑了。
他也买过网易三音音箱,听音乐、设闹钟都挺好的,但「需要用到脑子的问题就不能指望了」。而且这款音箱还会有一些「抽风」时刻,比如在自己打电话的时候突然接话,或是在看电影的时候突然出声……
苹果家的 Siri 同理,你可以命令它设置闹钟,咨询它时间和天气,但完全不能谈论有些深度的问题。
这些烦恼,都可以归结于 AI 的对话能力不够用。但近段时间面世的大型语言模型 ChatGPT,却给了这位 UP 主新的希望。
某天,他突然想到,何不用 ChatGPT 改造一下音箱,自制一款智能且强大的语音助理呢?

视频地址:https://www.bilibili.com/video/BV11M411F7Ww/
自制过程
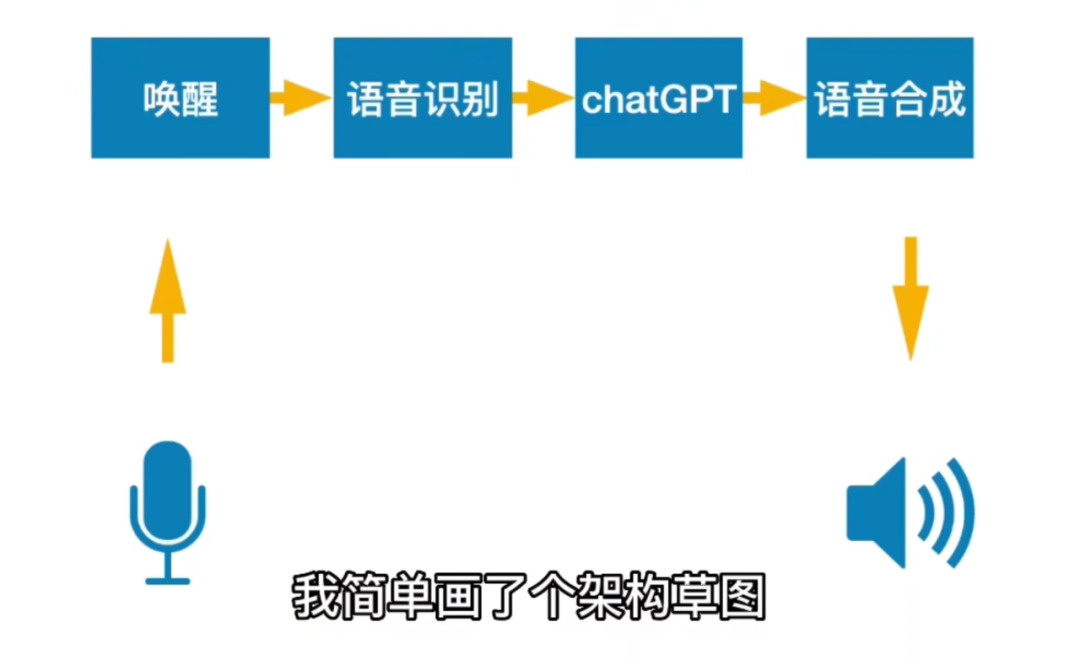
作者设计的架构草图如下,从语音输入到音箱回复,大致分为四个步骤:唤醒、语音识别、ChatGPT、语音合成。
硬件方面,自然是极客的不二之选:树莓派。
作者翻出尘封了几年的树莓派 3 Model B,发现它并未自带麦克风。只能在某宝光速下单,一边等快递,一边先用电脑调试。

接下来就是系统搭建工作了。首先要实现的,就是唤醒词检测。
唤醒词是一个特殊的词或短语,用于在说出它时激活设备,不说时让设备睡眠,也被称为「热词」和「触发词」
这里隐含一条规则,就是在唤醒前绝不允许偷听。然而实际上我们无法确认音箱到底有没有在偷听,所以只有自己使用开源代码去实现,才能确认音箱在唤醒之前不会偷听。
想必大家都听过一些常见的唤醒词,比如「Hey Siri」、「小爱同学」、「小度小度」。自定义唤醒词同样要遵守相应规则:一是避免使用过短的单词,以免产生误报;二是出于用户体验的考虑,唤醒词还要尽可能短;三是尽量选择不同发音的单词,组合特征更明显不易误报。
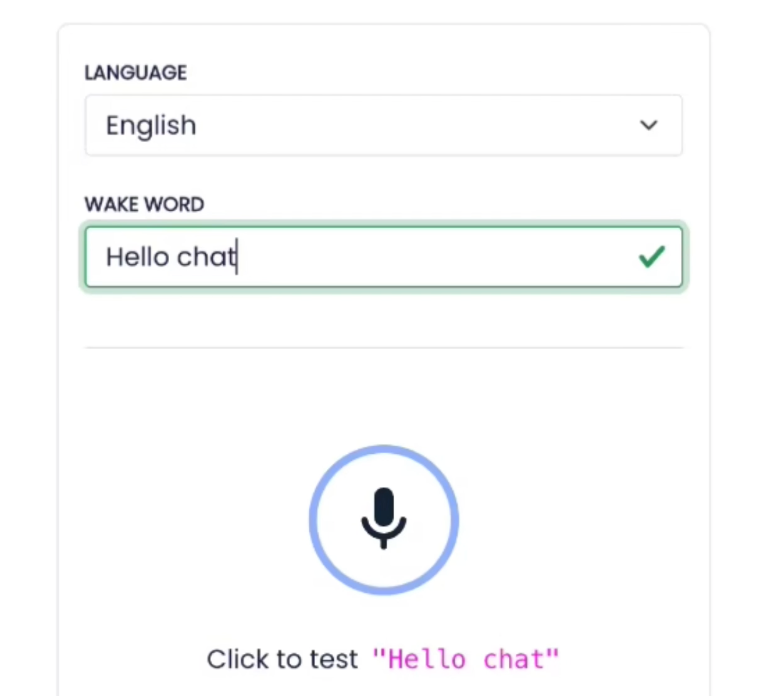
作者在这里使用的检测框架是 Porcupine,该框架对非商业应用免费开放,且支持多个词,唯一的遗憾是暂不支持中文。
最终,作者选择的唤醒词是「Hello Chat」。经过在线录音和训练后,得到了下载即用的模型。作者编写了一个脚本来运行唤醒词检测,检测之后会回应一声「咦」。
唤醒之后,作者用基于 Python 的语音处理库「PyAudio」来录制声音,假如此时你不想钻研项目文档,可以直接让 ChatGPT 给出示例代码,再做些微调即可。
第二步就是语音识别了,作者选择了微软 Azure 的在线 ASR,识别比较准确,速度也很快。这项功能会提供静音检测,当然也可以使用 Porcupine 提供的 cobra 静音检测功能,来判断语音输入何时结束。
第三步就是将 Azure 的识别结果发送给 ChatGPT,收到回复后再进行语音合成(TTS),通过音箱播放出来。
经过一番调试之后,网购的麦克风也到货了,将整套系统移植到树莓派,大功告成。
效果展示
通常,你会问智能音箱什么问题?
首先,作者询问了一个哲学问题:「用 10 个字回答人生的意义」。音箱用 5 个词语完美回答了这个问题:「探索、成长、分享、欣赏、感恩」,字数也刚好是十个字。

然后,作者又问了一个和科技行业有关的问题:「马斯克和乔布斯谁更厉害」。智能音箱的回答首先说明「这个问题没有确切答案,两个人都在不同的领域取得了巨大成就」,然后分别介绍马斯克和乔布斯两个人的成就。

当然,除了提问,你也可以和这款智能音箱打招呼,它就像是你身边的一个小助手:

此外,自己构建智能音箱还有一个好处是可以查看音箱工作时执行的代码,分析程序占用的资源。
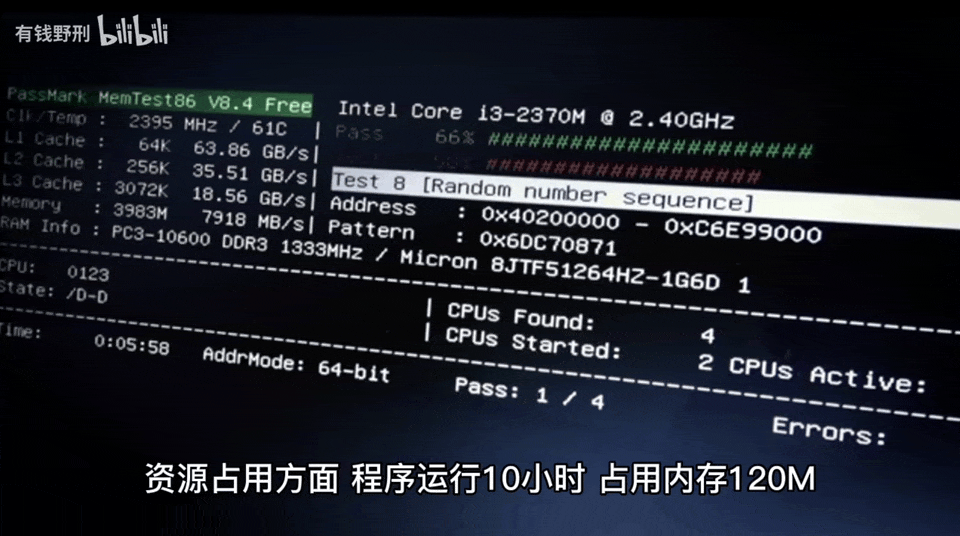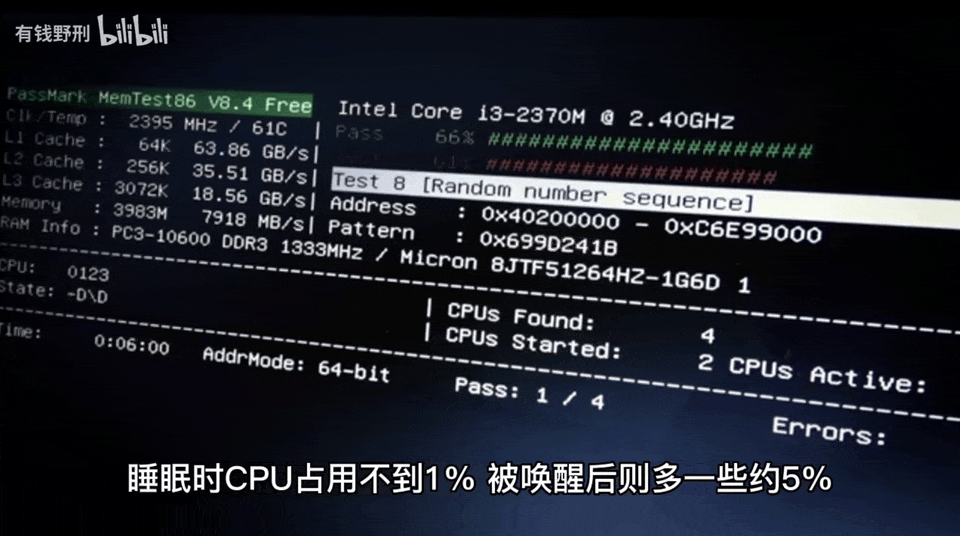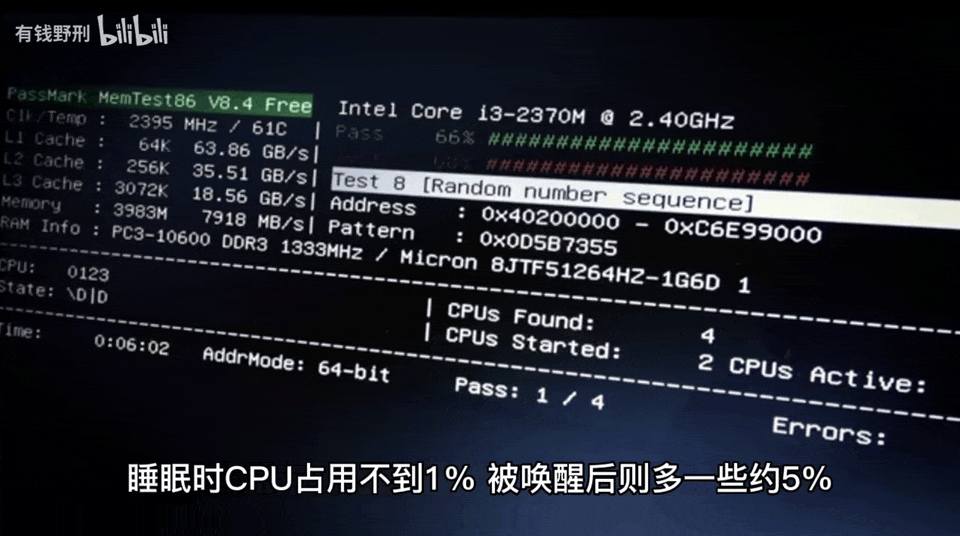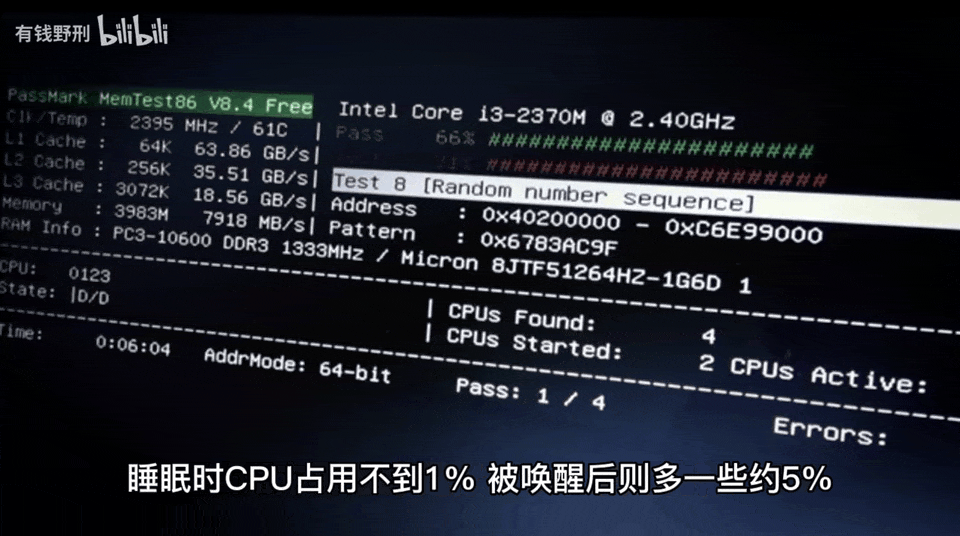
最重要的是,作者可以测试音箱的响应速度,并做出改进。第一版智能音箱听到问题后需要 10-20 秒才能作出回答,改进之后的第二版则只需要 4-6 秒,这个时间主要是 ChatGPT 的网络 + 计算时间开销。此外,作者还表示这款智能音箱的功能可以无缝迁移到其他平台。
最后,作者还挖了个坑:ChatGPT 在连续、关联性对话上的能力,又会如何提升音箱的智能水平?