今天,分享一篇机器学习模型以出色的精度进行有机反应机理分类,希望以下机器学习模型以出色的精度进行有机反应机理分类的内容对您有用。
编辑|绿萝
化学反应的发现不仅受到获得实验数据的速度的影响,还受到化学家理解这些数据的难易程度的影响。揭示新的催化反应的机理基础是一个特别复杂的问题,通常需要计算和物理有机化学的专业知识。然而,研究催化反应很重要,因为它们代表了最有效的化学过程。
近日,来自英国曼彻斯特大学(UoM)化学系的 Burés 和 Larrosa 报告了一种机器学习模型,展示了可以训练深度神经网络模型来分析普通动力学数据并自动阐明相应的机理类别,而无需任何额外的用户输入。该模型以出色的精度识别各种类型的机理。
研究结果表明,人工智能引导的机理分类是一种强大的新工具,可以简化和自动化机理阐明。预计这项工作将进一步推动全自动有机反应发现和开发的发展。
该研究以「Organic reaction mechanism classification using machine learning」为题,于 2023 年 1 月 25 日发布在《Nature》上。
论文链接:https://www.nature.com/articles/s41586-022-05639-4
化学反应机理的传统阐明方式
确定将底物转化为产品所涉及的基本步骤的确切顺序,对于合理改进合成方法、设计新催化剂和安全扩大工业过程至关重要。为了阐明反应机理,需要收集多个动力学曲线,人类专家必须对数据进行动力学分析。尽管反应监测技术在过去几十年中有了显著改进,以至于动力学数据收集可以完全自动化,但机理阐明的基础理论框架并没有以同样的速度发展。
当前的动力学分析流程包括三个主要步骤:从实验数据中提取动力学特性,预测所有可能机理的动力学特性,以及将实验提取的特性与预测的特性进行比较。
一个多世纪以来,化学家们一直在从反应速率中提取机理信息。今天仍在使用的一种方法是评估反应的初始速率,重点关注最初百分之几的起始物质的消耗。这种方法很受欢迎,因为在大多数情况下,反应物浓度随时间的变化在反应开始时是线性的,因此分析起来很简单。虽然很有见解,但这种技术忽略了在大部分时间过程中发生的反应速率和浓度的变化。
在过去的几十年里,已经发展出了更先进的方法来评估整个反应过程中反应组分的浓度。数学技术进一步促进了这些方法,这些技术从反应动力学图中揭示了参与一个反应步骤的组分的数量(也称为反应组分的顺序)。这些技术肯定会继续为化学反应性提供深刻的见解,但它们局限于分析反应组分的顺序,而不是提供一个更全面的机理假设来描述催化系统的动力学行为。
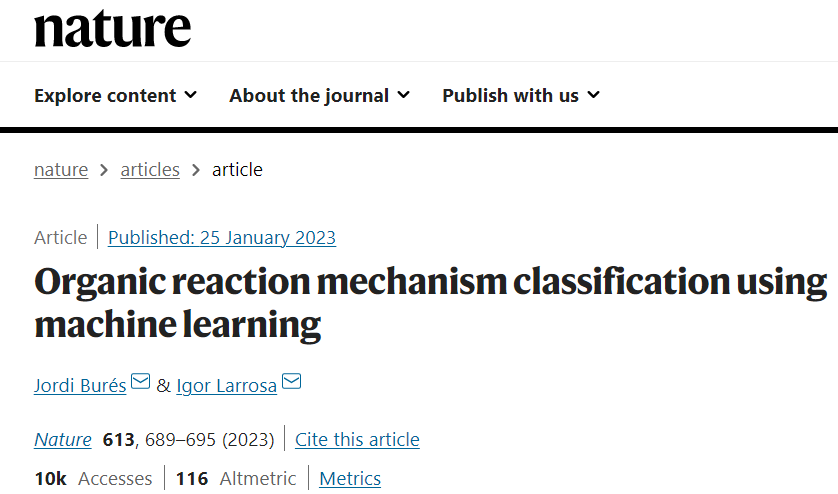
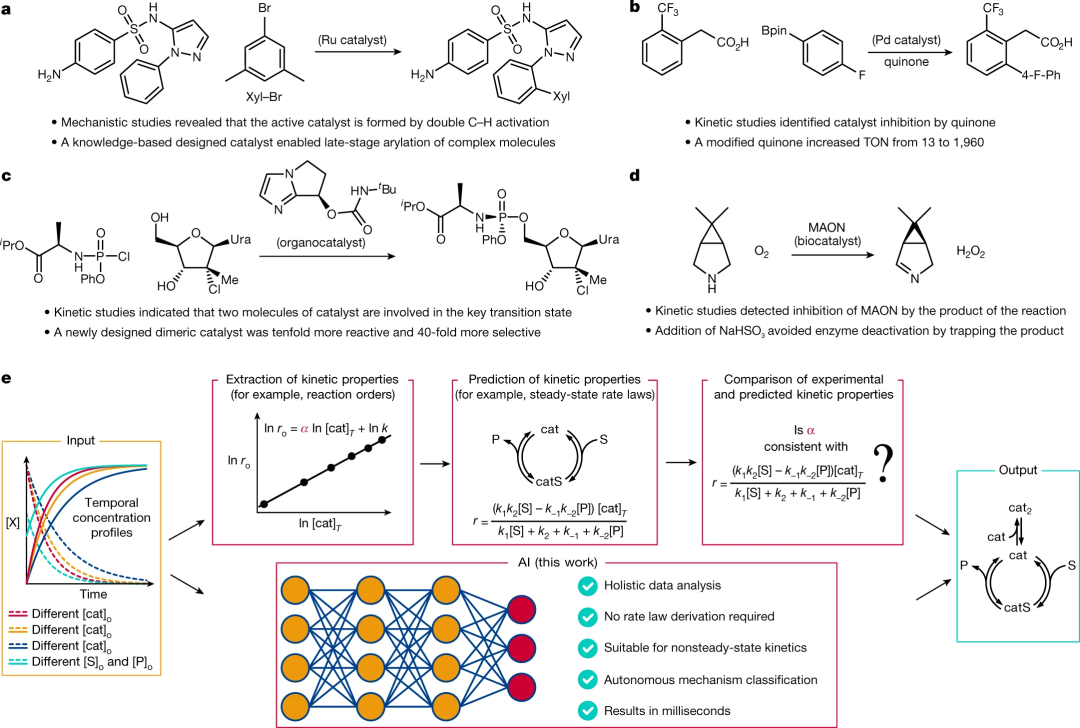 图 1:动力学分析的相关性和最新技术。(来源:论文)
图 1:动力学分析的相关性和最新技术。(来源:论文)AI 改变动力学分析领域
机器学习正在彻底改变化学家解决问题的方式,从设计分子和路线到合成分子,再到理解反应机理。Burés 和 Larrosa 现在通过机器学习模型,根据模拟的反应动力学特征对反应进行分类,为动力学分析带来了这场革命。
在这里,研究人员证明了一个基于模拟动力学数据训练的深度学习模型能够正确地阐明来自时间浓度分布的各种机理。机器学习模型消除了速率定律推导和动力学性质提取和预测的需要,从而简化了动力学分析,极大地促进了所有合成实验室对反应机理的阐明。
由于对所有可用动力学数据进行了整体分析,该方法提高了询问反应曲线的能力,消除了动力学分析过程中潜在的人为错误,并扩大了可分析的动力学范围,包括非稳态(包括活化和失活过程)和可逆反应。这种方法将是对目前可用的动力学分析方法的补充,并将在最具挑战性的情况下特别有用。
具体研究
研究人员定义了 20 类反应机理,并为每一类制定了速率定律。每种机理都由一组动力学常数(k1, … kn) 和化学物质浓度的常微分方程(ODE)函数进行数学描述。然后,他们求解了这些方程式,生成了数百万个描述反应物衰变和产物生成的模拟。这些模拟动力学数据用于训练学习算法以识别每个机理类别的特征签名。生成的分类模型使用动力学曲线作为输入,包括初始和时间浓度数据,并输出反应的机理类别。
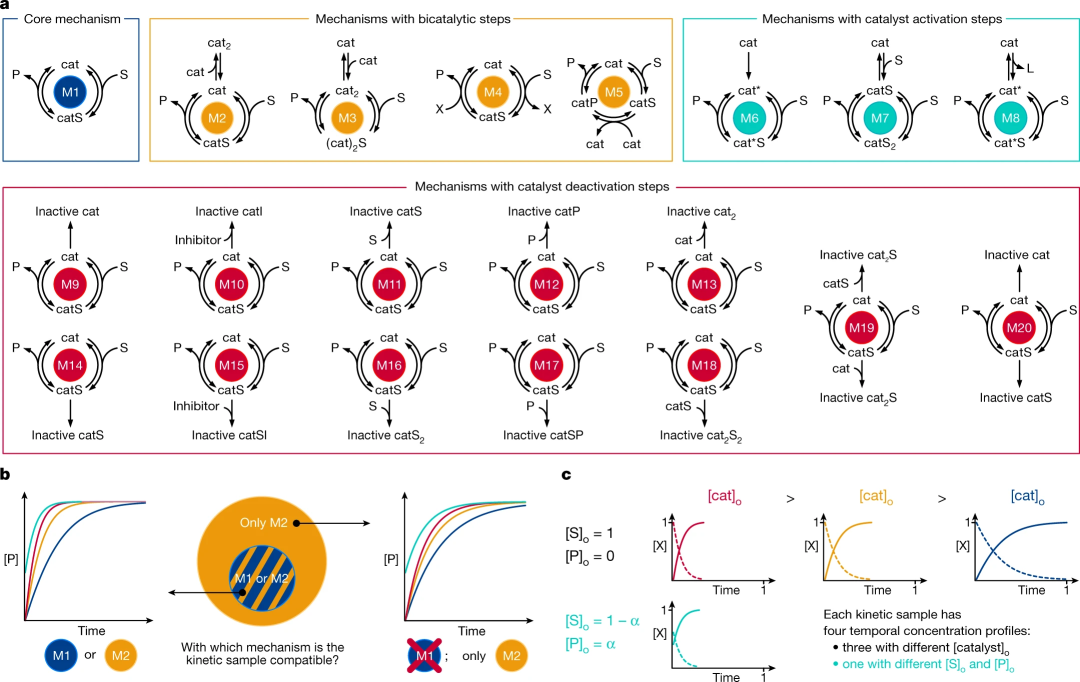 图 2:机理范围和数据构成。(来源:论文)
图 2:机理范围和数据构成。(来源:论文)深度学习模型的训练通常需要大量数据,当必须通过实验收集这些数据时,这可能会带来相当大的挑战。
Burés 和 Larrosa 训练算法的方法避免了产生大量实验动力学数据的瓶颈。在案例中,研究人员能够通过数值求解 ODE 集来生成 500 万个动力学样本用于模型的训练和验证,而无需使用稳态近似。
模型包含 576,000 个可训练参数,并结合使用两种类型的神经网络:(1) 长短期记忆神经网络,一种用于处理时间数据序列(即时间浓度数据)的循环神经网络;(2) 全连接神经网络,用于处理非时间数据(即每次动力学运行中催化剂的初始浓度和长短期记忆提取的特征)。该模型输出每种机理的概率,概率总和等于 1。
研究人员使用模拟动力学曲线的测试集评估了训练模型,并证明它正确地将这些曲线分配给机理类,准确率为 92.6%。
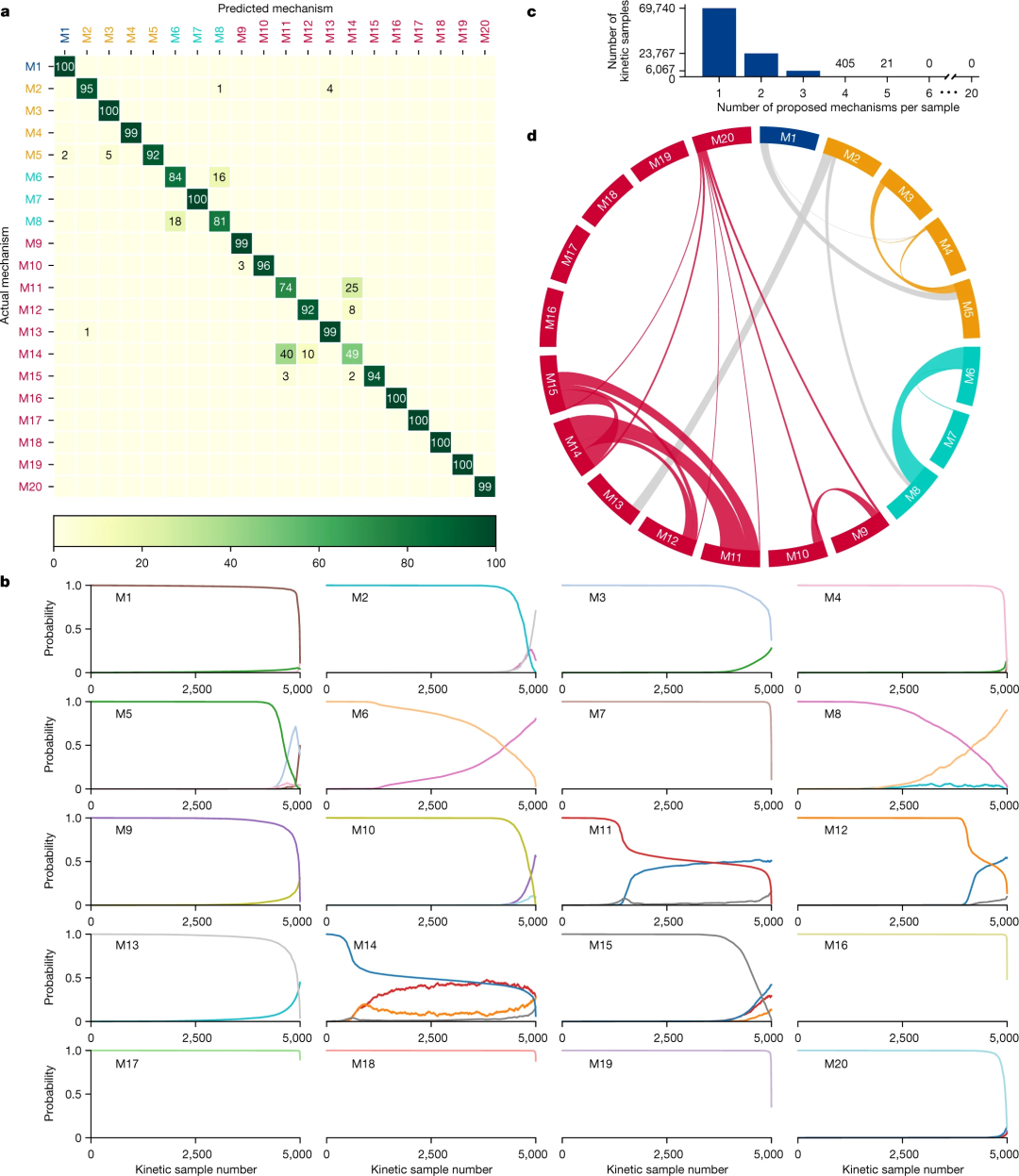 图 3:机器学习模型在测试集上的性能,每个动力学曲线有六个时间点。(来源:论文)
图 3:机器学习模型在测试集上的性能,每个动力学曲线有六个时间点。(来源:论文)即使有意引入「嘈杂」数据,该模型也表现良好,这意味着它可用于对实验数据进行分类。
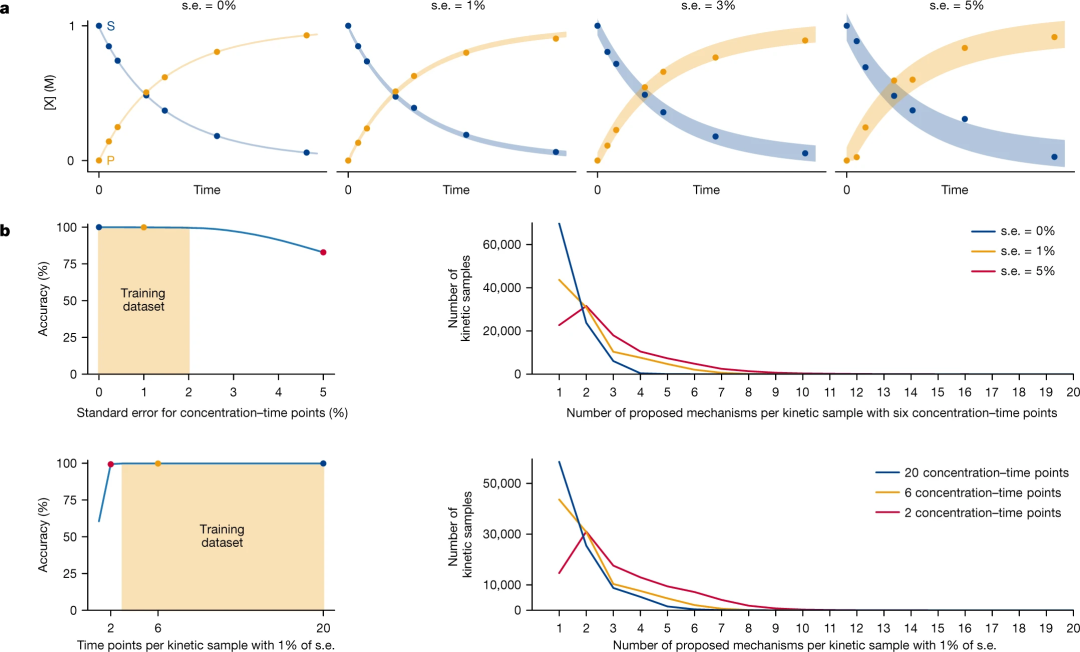 图 4:误差和数据点数量对机器学习模型性能的影响。(来源:论文)
图 4:误差和数据点数量对机器学习模型性能的影响。(来源:论文)最后,研究人员使用先前报道的几个实验动力学曲线对他们的模型进行了基准测试。预测的机理与早期动力学研究的结论非常吻合。在某些情况下,该模型还识别了在原始工作中没有检测到的机理细节。对于一个具有挑战性的反应,该模型提出了三个非常相似的机理类别。然而,作者正确地说,这个结果不是一个错误,而是他们模型的一个特征,因为它表明需要进一步的具体实验来探索机理。
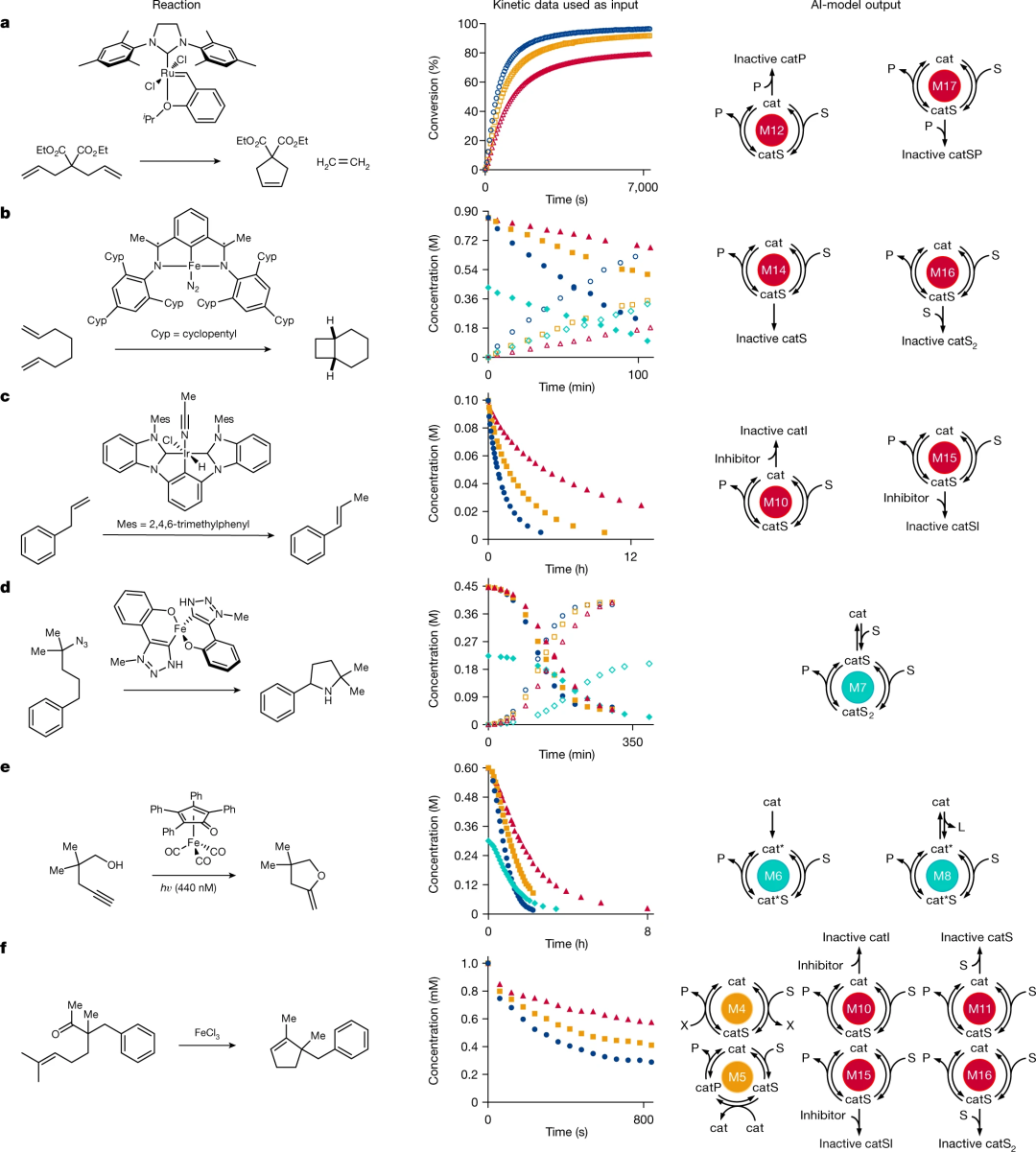 图 5:具有实验动力学数据的案例研究。(来源:论文)
图 5:具有实验动力学数据的案例研究。(来源:论文)总之,Burés 和 Larrosa 开发了一种方法,不仅可以自动执行从动力学研究中推导出机理假设的漫长过程,还可以对具有挑战性的反应机理进行动力学分析。与数据分析中的任何技术进步一样,由此产生的机理分类应被视为需要进一步实验支持的假设。误解动力学数据的风险始终存在,但该算法能够在少量实验的基础上以高精度识别正确的反应路径,可以说服更多研究人员尝试动力学分析。
因此,这种方法可以普及和推动动力学分析纳入反应开发流程,尤其是当化学家对机器学习算法越来越熟悉时。
参考内容:https://www.nature.com/articles/d41586-023-00145-7






















