原标题:AMD RDNA 2 GPU与NVIDIA的安培GPU对决内存延迟性 来源:cnBeta.COM
Chips and Cheese测试了AMD的RDNA 2和NVIDIA的Ampere GPU架构的内存延迟性能,并发现了一些有趣的结果。
AMD的RDNA 2 GPU与NVIDIA的Ampere GPU架构相比,具有卓越的内存延迟性能。在CPU方面,随着多芯片die和同一die上的多个IO芯片的不断使用,测量缓存和延迟性能已经成为一个关键的指针。GPU也是由多个缓存层次组成,填补了计算和内存性能之间的空白。
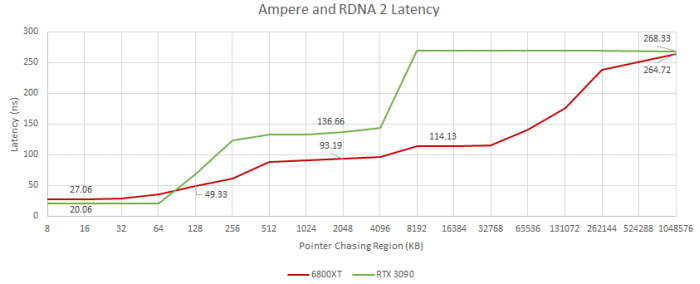
这次测试使用基于OpenCL的指针跟踪基准测试来测量当前一代GPU(如NVIDIA Ampere和AMD RDNA 2体系结构)上的缓存和内存延迟性能。在基准测试中,AMD Radeon RX 6800 XT(RDNA 2 GPU)与NVIDIA GeForce RTX 3090(Ampere GPU)进行了对决。缓存和内存基准测试显示,AMD的RDNA 2架构表现远好于NVIDIA的Ampere GPU,尽管在去往内存的路上要多检查两级缓存,但延迟时间更低。使用Infinity缓存只比L2命中增加了20ns,仍然比NVIDIA的Ampere快。
NVIDIA Ampere GA102 GPU体积大了很多,使用了比较传统的GPU内存子系统,只有两级缓存,但却要耗费大量的周期,导致延迟(L1到L2)超过100ns。而RDNA 2的延迟则只有66ns。需要注意的是,AMD Navi 21 GPU的体积更小,只有4 MB的二级缓存,而NVIDIA GA102 GPU的整个芯片有6 MB的二级缓存。NVIDIA A100 Ampere GPU for HPC则拥有庞大的40 MB二级缓存。
RDNA 2的缓存速度很快,而且数量很多。与Ampere相比,各级别的延迟都很低。Infinity Cache只比L2命中增加了20ns左右,延迟比Ampere的L2还低。令人惊奇的是,RDNA 2的VRAM延迟与Ampere差不多,尽管RDNA 2在通往内存的路上多检查了两级缓存。相比之下,Nvidia坚持使用更传统的GPU内存子系统,只有两级缓存,L2延迟很高。从Ampere的SM-private L1到L2缓存需要超过100 ns。RDNA的L2与L0的距离约为66ns,即使它们之间有L1缓存。绕过GA102庞大的die似乎需要很多周期。
这可以解释AMD在较低分辨率下的优异性能。RDNA 2的低延迟L2和L3缓存可能会在较小的工作负载下给它带来优势,相比之下,Nvidia的Ampere芯片需要更多的并行任务才能大放异彩。与旧的Pascal和Maxwell芯片相比,Ampere架构在更大的GPU上带来了高度改善的延迟速度。另一方面,AMD在与旧的基于GCN和VLIW架构的芯片相比,也有一些令人印象深刻的进步。一旦新一轮基于芯片的GPU在未来几年登陆游戏领域,这些数据的比较肯定会很有趣。