机器之心专栏
加州大学洛杉矶分校、MIT、斯坦福等
来自MIT-IBM 沃森人工智能实验室首席科学家淦创团队提出了新一代视觉推理数据集,该数据集提出了基于局部(part)的视觉推理,并融合了五类人类认知推理任务:概念型推理,关系型推理,类比型推理,数学推理和物理推理。
人类视觉感知的一个关键点是将视觉场景解析为物体,并进一步解析为物体的各个局部,从而形成部分 - 整体层次结构。这种层级结构可以诱导出丰富的语义概念和关系,从而在解释和组织视觉信息方面,以及视觉感知和推理的泛化方面发挥着重要作用。然而,现有的视觉推理数据集主要关注整个物体,而不是物体中的局部。由于更细粒度的概念、更丰富的几何关系和更复杂的物理关系,基于部分 - 整体层次结构的视觉推理比以物体整体为中心的推理更具挑战性。
因此,为了更好地阐释和理解基于局部的概念和关系,本文引入了一个新的名为 PTR 的大规模诊断型视觉推理数据集。PTR 包含大约七万 RGBD 合成图像,带有关于语义实例分割、颜色属性、空间和几何关系以及某些物理属性(例如稳定性)的物体和局部标注。这些图像配有五种类型的问题:概念型推理,关系型推理,类比型推理,数学推理和物理推理。这些类型均来自于人类认知推理的重要方面,但在以往的工作中并没有被充分探索过。
本文在这个数据集上检验了几个最先进的视觉推理模型。研究者观察到它们的表现远远不及人类表现,特别是在一些较新的推理类型(例如几何,物理问题)任务上。该研究期待这个数据集能够促进机器推理向更复杂的人类认知推理推进。

论文地址:http://ptr.csail.mit.edu/assets/ptr.pdf
项目主页:http://ptr.csail.mit.edu
1 背景介绍
视觉推理要求机器通过观察给定的场景来回答推理问题。近年来,由于在自然数据中存在大量的噪声和偏差,研究人员合成数据集。合成数据集的生成是完全可控的,因此研究者更容易诊断推理模型中的不足。CLEVR[1] 是这类数据集中的代表。然而,各类视觉推理模型在 CLEVR 上的准确率已经趋近饱和,这是因为 CLEVR 数据集的推理局限于感知层面,远远落后于人类在认知层面的推理能力。因此,本文提出了新一代视觉推理数据集,专注于对人类来说相对容易,但在机器推理领域还没有被充分发掘的新任务。
同时,之前的视觉推理数据集主要关注物体的整体特征,而不太强调详细的局部理解。然而,心理学证据表明,人类会将视觉场景解析为部分 - 整体层次结构。因此,本文提出的数据集主要专注于整体 - 部分关系的推理。
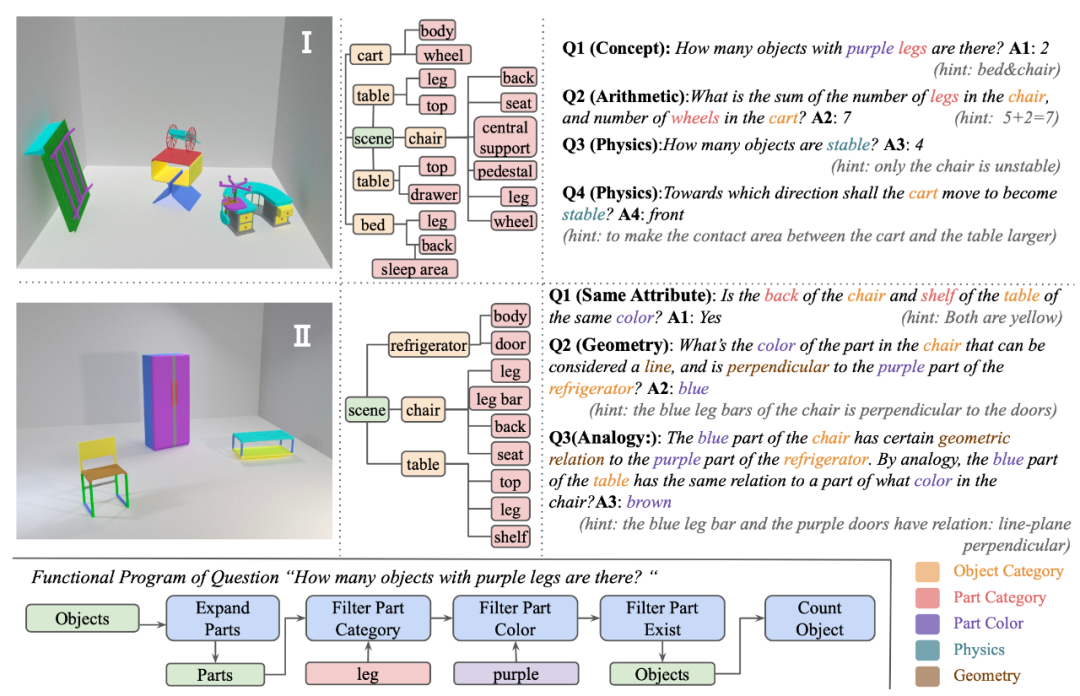
图二:PTR 数据集介绍
2 数据集介绍
PTR 数据集有七万的 RGBD 图片和 70 万基于这些图片的问题。本文作者提供了详细的图片标注,包括语义实例分割、几何、物理状态的标注。数据集的生成采取了精细的偏差和噪声控制。
下图总结了 PTR 数据集涵盖的概念。
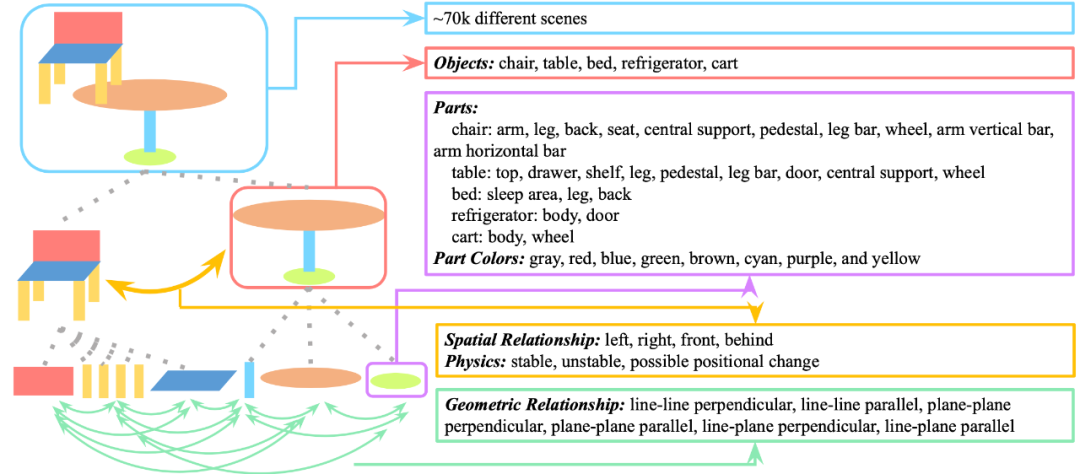
图三:PTR 数据集中的概念
可以看出,PTR 数据集具有丰富的认知层面的概念和关系。在物体整体方面,具有空间关系、物理状态等概念,在局部方面,有几何关系等概念。整体 - 部分的加入大大增加了视觉推理的层次性和丰富性。
PTR 数据集包含了五类问题:概念型推理,关系型推理,类比型推理,数学推理和物理推理。
2.1 概念型推理
主要考察机器对于整体 - 部分的概念和关系的理解。

2.2 关系型推理
主要考察机器对于物体之间的空间关系,和局部之间的几何关系的理解。

2.3 类比型推理
主要考察机器能否将物体之间 / 局部之间的关系迁移到其他物体 / 局部上。

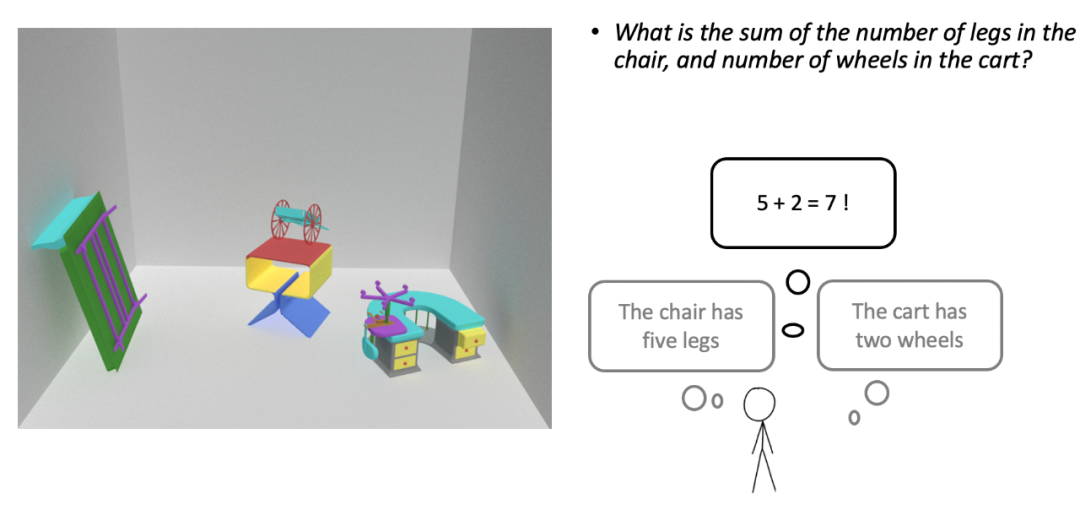
2.4 数学推理
主要考察机器能否对场景进行数学推理。
2.5 物理推理
主要考察机器能否对物体的物理状态作出判断。

3 实验部分
本文检验了几个 SOTA 视觉推理模型在该数据集上的效果,包括 NS-VQA[2], MDETR[3], MAC[4] 等。
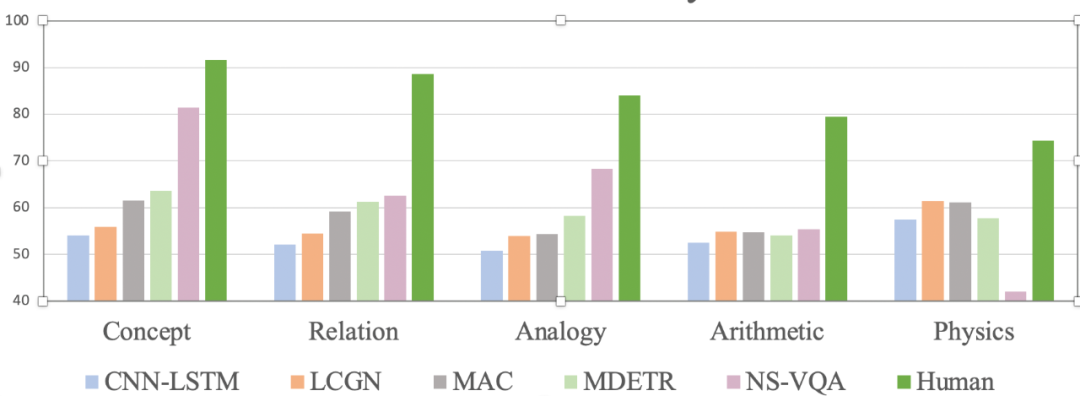
图四:实验结果
从结果可以看出,视觉推理模型的效果要远远低于人类表现。其中 NS-VQA 用到了 ground-truth 分割、语义等训练模型。然而,在较难的问题例如物理、几何上面效果仍然很差。
为进一步研究该结果来源于感知上的不正确还是认知推理上的能力欠缺,本文对 NS-VQA 模型进行了消融研究。
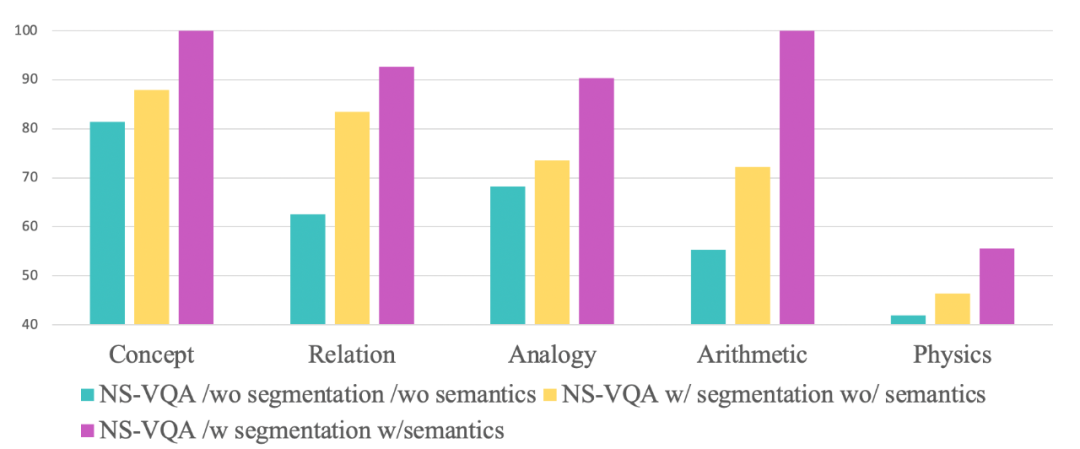
图五:NS-VQA 模型的消融研究
结果表明,即便拥有完美的感知能力并给予该模型所有需要的物体、局部分割,模型在几何、类比、物理问题上效果依旧不乐观。
实验表明,该研究数据集对未来机器如何进行和人类一样的认知推理,特别是在一些比较难的物理、集合问题上进行推理,提出了非常重要的方向。
[1] CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning. Justin Johnson, Li Fei-Fei, Bharath Hariharan, C. Lawrence Zitnick, Laurens van der Maaten, Ross Girshick
[2] Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding. Kexin Yi*, Jiajun Wu*, Chuang Gan, Antonio Torralba, Pushmeet Kohli, Joshua B. Tenenbaum
[3] MDETR -- Modulated Detection for End-to-End Multi-Modal Understanding
Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, Nicolas Carion
[4] Compositional Attention Networks for Machine Reasoning. Drew A. Hudson, Christopher D. Manning
NVIDIA TAO Toolkit是一个AI工具包,它提供了AI/DL框架的现成接口,能够更快地构建模型,而不需要编码。
12月14日19:30-21:00,本次分享摘要如下:
介绍 TAO Toolkit 的最新特性;
介绍 NVIDIA Deepstream 的最新特性;
利用 TAO Toolkit 丰富的预训练模型库,快速训练模型;
直接利用 TAO Toolkit 的预训练模型和 Deepstream 部署应用;