今天,分享一篇Stable Diffusion 2.0来了!网友太快了,V1还没整透彻,V2就来了,希望以下Stable Diffusion 2.0来了!网友太快了,V1还没整透彻,V2就来了的内容对您有用。
如果你想,SD 2.0 能生成分辨率为 2048x2048 甚至更高的图像。
今日,Stability AI 官方宣布,那个爆红 AI 圈的 Stable Diffusion 来到了 2.0 版本(SD 2.0)!上线短短几个小时,点赞量已经很可观了。
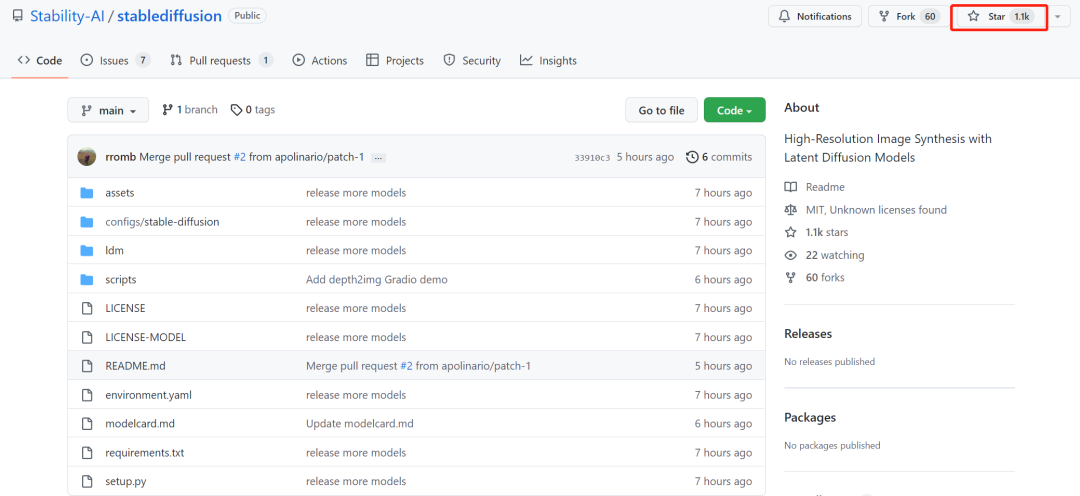
项目地址:https://github.com/Stability-AI/stablediffusion
可以说,这波更新速度够快的,就像网友说的,我从未见过任何技术发展如此之快。V1 还没整透彻,V2 就来了。

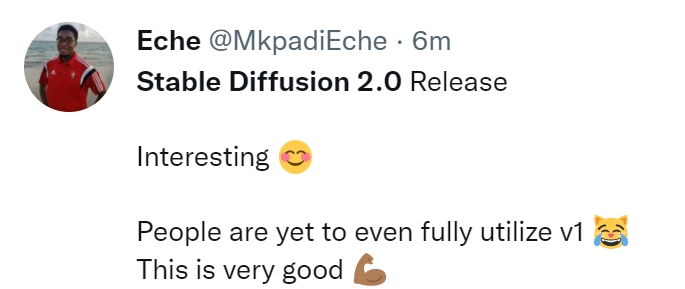
V1亮相之初,在Github 排行榜,Stable Diffusion 为所有软件中攀升至 10K star 最快的其中之一,在不到两个月的时间内飙升至 33K star。按照这个速度,2.0 版本很快就会赶上。
Stability AI 的产品副总裁兴奋的表示:Stable Diffusion 2.0 是有史以来发布的最强大的开源项目之一。这是迈向创造力、表达能力和沟通民主化的又一大步。
还有网友表示:「离完美不远了。可能是 V5 或 V6 版本」。
「新版本是改变游戏规则的更新。」
与最初的 V1 版本相比,Stable Diffusion 2.0 提供了许多重大改进和特性,具体表现在:
Stable Diffusion 2.0 版本包含一个具有鲁棒性的文本 - 图像模型,在全新的文本编码器 (OpenCLIP) 上训练而成,与早期的 V1 版本相比,文本 - 图像模型大大提高了图像生成质量,可以生成默认分辨率为 512x512 像素和 768x768 像素的图像。
此外,文本 - 图像模型是在 LAION-5B 数据集上训练的,然后使用 NSFW filter 过滤掉一些不可描述的内容。

Stable Diffusion 2.0 还包括一个 Upscaler Diffusion 模型,该模型将生成图像的分辨率提高了 4 倍。具体效果如何呢?例如下图展示的是 Upscaler 将低分辨率生成的图像 (128x128) 升级(upscaling)为更高分辨率的图像(512x512)。现在的图像已经够清晰了,然后在结合上述提到的文本 - 图像模型, 比如将 512x512 像素的图像提高 4 倍,Stable Diffusion 2.0 现在可以将图像升级为分辨率为 2048x2048 甚至更高的图像。

此外,Stable Diffusion 2.0 更新还包括 Depth2img(depth-guided stable diffusion)模型,它扩展了 V1 版本中图像 - 图像的特性,为创意应用提供了全新的可能性。Depth2img 用来推理输入图像的深度,然后使用文本和深度信息生成新图像。

左边为输入图像,右边为新生成的图像,相同的动作,面貌各异。该新模型可用于图像 - 图像结构的保持和形状的合成。
Depth2img 提供了不同创新性应用,虽然生成的图像与原始图像有很大的不同,但仍然保持了图像的连贯性和深度:

Stable Diffusion 2.0 生成的深度 - 图像保持一致性。
最后,Stable Diffusion 2.0 还引入了一个新的 text-guided 修复模型,用户可以非常智能、快递的切换图像部分内容,如下图中豹子的嘴巴和鼻子是不变的,其他部分可以随意改变。

研究者表示,他们正在努力优化模型以在单个 GPU 上运行,让尽可能多的人可以使用。
参考链接:https://stability.ai/blog/stable-diffusion-v2-release